pandas数据结构之DataFrame操作
2024-10-15 09:14:06
这一次我的学习笔记就不直接用官方文档的形式来写了了,而是写成类似于“知识图谱”的形式,以供日后参考。
下面是所谓“知识图谱”,有什么用呢?
1.知道有什么操作(英文可以不看)
2.展示本篇笔记的结构
3.以后忘记某个函数某个参数时,方便查询
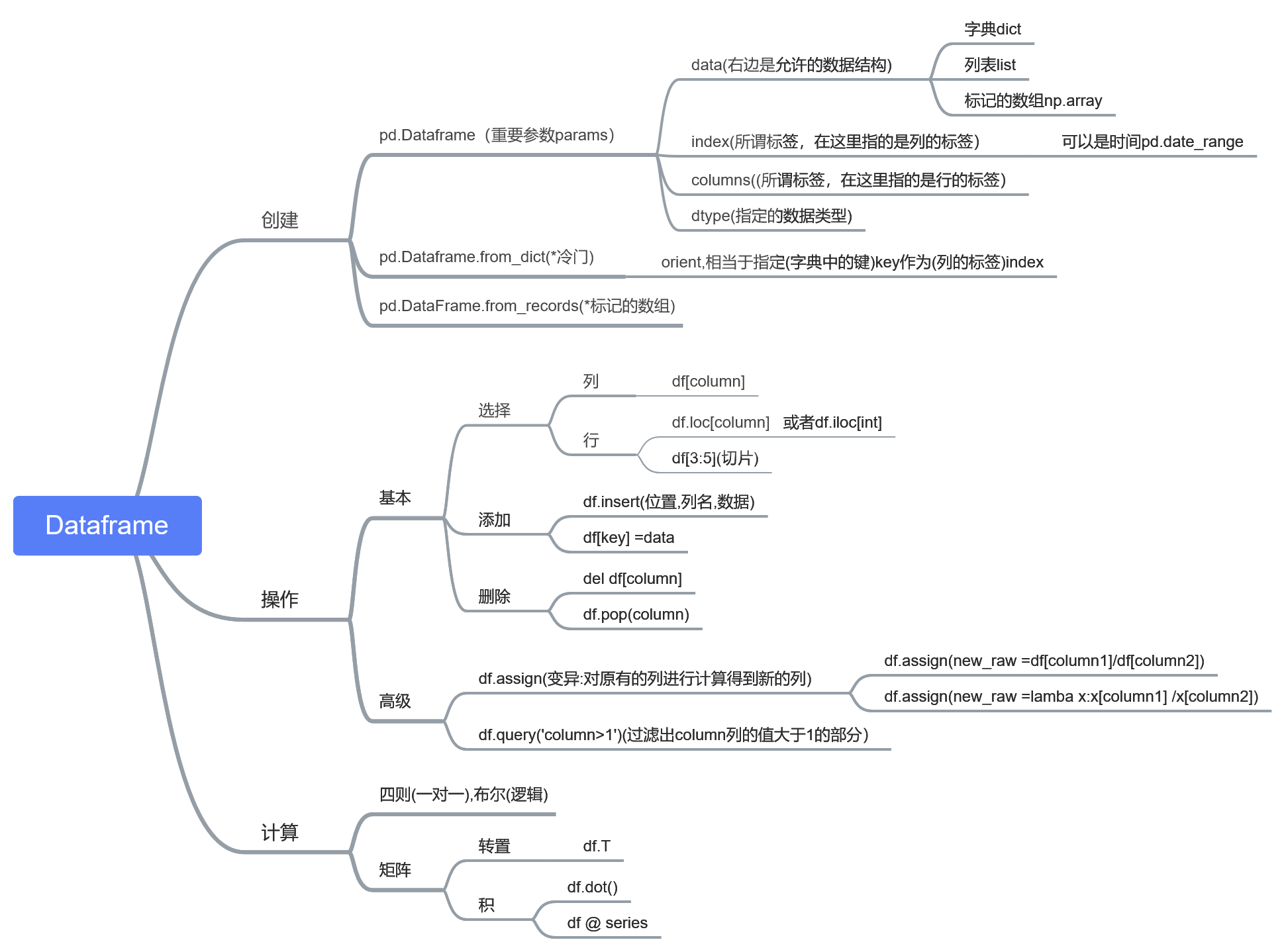
原来写的地方是,那儿的代码看起来会舒服很多: https://www.yuque.com/u86460/dgt6mu/tlywuc
创建
df.Dataframe(data,index)
1.data类型是字典
字典由series构成
>>> import pandas as pd
>>> #由series构成
>>> d ={'a':pd.Series([1,2,3,4]),'b':pd.Series([4,3,2,1,0])}
>>> df =pd.DataFrame(d)
>>> df
a b
0 1.0 4
1 2.0 3
2 3.0 2
3 4.0 1
4 NaN 0
>>> #指定Series的index(标签)
>>> d ={'a':pd.Series([1,2,3,4],index=['a', 'b', 'c','d']),
'b':pd.Series([4,3,2,1,0],index=['a', 'b', 'c','d','f'])}
>>> pd.DataFrame(d)
a b
a 1.0 4
b 2.0 3
c 3.0 2
d 4.0 1
f NaN 0
>>> #指定Dataframe的index(列标签)
>>> pd.DataFrame(d,index =['a', 'b', 'c','d','f'])
a b
a 1.0 4
b 2.0 3
c 3.0 2
d 4.0 1
f NaN 0
>>> #指定Dataframe的columns(行标签)
>>> pd.DataFrame(d,index =['a', 'b', 'c','d','f'],columns=['b','c'])
b c
a 4 NaN
b 3 NaN
c 2 NaN
d 1 NaN
f 0 NaN
字典由列表或数组构成
>>> d ={'a':[1,2,3,4],'b':[4,3,2,1]}
>>> pd.DataFrame(d,index=['a', 'b', 'c','d'])
a b
a 1 4
b 2 3
c 3 2
d 4 1
字典的键由元组构成
>>> pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},
('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4},
('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6},
('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8},
('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}})
a b
b a c a b
A B 1.0 4.0 5.0 8.0 10.0
C 2.0 3.0 6.0 7.0 NaN
D NaN NaN NaN NaN 9.0
2.类型是list
多个的字典构成的列表
>>> d = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
>>> pd.DataFrame(d)
a b c
0 1 2 NaN
1 5 10 20.0
多个series构成的列表
>>> d =[pd.Series([1,2,3,4],index=['a', 'b', 'c','d']),
pd.Series([4,3,2,1,0],index=['a', 'b', 'c','d','f'])]
>>> pd.DataFrame(d)
a b c d f
0 1.0 2.0 3.0 4.0 NaN
1 4.0 3.0 2.0 1.0 0.0
>>> pd.DataFrame(d,index =['a','b'])
a b c d f
a 1.0 2.0 3.0 4.0 NaN
b 4.0 3.0 2.0 1.0 0.0
>>> #每一个series就是一行
3.类型是标记的数组
>>> import numpy as np
>>> #指定数组每一列的数据类型,相当于创建一个模板
>>> data = np.zeros((2,), dtype=[('A', 'i4'),('B', 'f4'),('C', 'a10')])
>>> #为模板赋值
>>> data[:] = [(1,2.,'Hello'), (2,3.,"World")]
>>> pd.DataFrame(data)
A B C
0 1 2.0 b'Hello'
1 2 3.0 b'World'
pd.DataFrame.from_dict(dict)
>>> pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]))
A B
0 1 4
1 2 5
2 3 6
>>> pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]),
orient='index', columns=['one', 'two', 'three'])
one two three
A 1 2 3
B 4 5 6
#orient,相当于指定(字典中的键)key作为(列的标签)index
DataFrame.from_records
>>> pd.DataFrame.from_records(data, index='C')
A B
C
b'Hello' 1 2.0
b'World' 2 3.0
操作
上面创建部分是交互式操作,接下来就直接看代码的的注释,可以自己试着交互
import pandas as pd
import numpy as np
#**创建部分
#df.Dataframe(data,index)
'类型是字典'
#由series构成
d ={'a':pd.Series([1,2,3,4]),'b':pd.Series([4,3,2,1,0])}
d ={'a':pd.Series([1,2,3,4],index=['a', 'b', 'c','d']),
'b':pd.Series([4,3,2,1,0],index=['a', 'b', 'c','d','f'])} #指定Series的index(标签)
pd.DataFrame(d,index =['a', 'b', 'c','d','f']) #指定Dataframe的index(列标签)
pd.DataFrame(d,index =pd.date_range('2000/1/1',periods=2)) #指定标签为日期
pd.DataFrame(d,index =['a', 'b', 'c','d','f'],columns=['b','c']) #指定Dataframe的columns(行标签)
#字典由列表或数组构成
d ={'a':[1,2,3,4],'b':[4,3,2,1]}
pd.DataFrame(d,index=['a', 'b', 'c','d'])
#字典的键由元组构成
pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},
('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4},
('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6},
('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8},
('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}})
'类型是list'
#多个的字典构成的列表
d = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
#多个series构成的列表
d =[pd.Series([1,2,3,4],index=['a', 'b', 'c','d']),
pd.Series([4,3,2,1,0],index=['a', 'b', 'c','d','f'])]
'类型是标记的数组'
data = np.zeros((2,), dtype=[('A', 'i4'),('B', 'f4'),('C', 'a10')]) #指定数组每一列的数据类型,相当于创建一个模板
data[:] = [(1,2.,'Hello'), (2,3.,"World")] #为模板赋值
#pd.DataFrame.from_dict(dict)
pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]))
pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]),
orient='index', columns=['one', 'two', 'three'])
#orient,相当于指定(字典中的键)key作为(列的标签)index
#DataFrame.from_records
df =pd.DataFrame.from_records(data, index='C')
#**操作部分
'选择'
#选择列
df['A']
#选择行
df.loc[b'Hello']
df.iloc[0]
df['d'] =df['A'] *df['B'] #生成新列
df['e'] =df['A'] >2
df['f'] =df['A'][:1] #切片
'添加'
df.insert(1,'dd',df['B']) #位置,column,值
'删除'
del df['A']
df.pop('B')
'变异'
df =pd.DataFrame(d)
df1 =df.assign(new =df['a'] +df['b'])
df1 =df.assign(new =lambda x:x['a'] *x['b'])
'过滤'
df1=df.query('a>1').assign(new =df['a'] +df['b'])
#**计算部分
'四则,布尔:+-*/,|&^ 都是点对点形式'
'矩阵'
df.T #转置
df.T@df
df.T.dot(df) #积
#输出部分
df.to_string()
#pd.set_option('display.max_colwidth',30)
#pd.set_option('display.width', 40) # default is 80
最新文章
- Android网络编程1
- Spring知识点提炼
- c# DllImport 找不到指定模块
- 把vim当做golang的IDE
- .Net Core开源通讯组件 SmartRoute(服务即集群)
- qml基础学习 模型视图(一)
- 条件注释判断浏览器版本<!--[if lt IE 9]>
- SQL语句中&、单引号等特殊符号的处理
- STAF自动化测试框架
- 转:C语言字符串操作函数 - strcpy、strcmp、strcat、反转、回文
- UVa 10054 The Necklace【欧拉回路】
- 开源Pull_To_Refresh控件使用
- javascript how sort() work
- codeforces 589F. Gourmet and Banquet 二分+网络流
- MySQL57安装图解
- zuul1.3源码扒一扒(1)
- iview表单验证不生效问题注意点
- centos7.2安装社区版docker-ce-17.06.1
- 关于DirectShow SDK 和Windows SDK,及DirectX SDK
- IE(IE6/IE7/IE8)支持HTML5标签