pyspark 中的rdd api 编码练习
2024-10-21 13:05:15
1,使用pyspark 的rdd api 进行了数据文件的处理,包括构建RDD, 统计分析RDD ,从文件中读取数据RDD,从文件中构建 rdd的模式shema.
然后通过模式,从rdd中生成dataframe。
2,代码
'''
构建sparkSession 和练习数据(RDD 和 KV rdd)
'''
spark = SparkSession.builder.appName("rdd_api_test") \
.master("local[2]") \
.getOrCreate()
sc = spark.sparkContext
rdd1 = sc.parallelize([1, 5, 60, 'a', 9, 'c', 4, 'z', 'f'])
rdd2 = sc.parallelize([('a', 6),
('a', 1),
('b', 2),
('c', 5),
('c', 8),
('c', 11)]) '''
查看rdd元素 , 元素个数, KV对RDD中key的出现次数, 分区个数等常用api
'''
print(rdd2.collect())
print (rdd2.take(2))
print('amount of elements:', rdd2.count())
print('RDD count of key:', rdd2.countByKey())
print('RDD output as map:', rdd2.collectAsMap())
print('RDD number of partitions:', rdd2.getNumPartitions()) '''
数值型rdd ,常用统计函数, 最小,最大 ,平均 , 标准差,方差
'''
rdd5 = sc.parallelize(range(100))
print('RDD Min:', rdd5.min()) # rdd 最小值
print('RDD Max:', rdd5.max())
print('RDD Mean:', rdd5.mean())
print('RDD Standard deviation:', rdd5.stdev())
print('RDD Variance:', rdd5.variance()) '''
从文件读取数据,并且去掉第一行列名,进行显示
数据源:nba.csv
'''
full_csv = sc.textFile('nba.csv')
header = full_csv.first()
print(full_csv.filter(lambda line: line != header).take(4)) # 去掉头行后,看效果 '''
从文档中读出文件头部,设置rdd模式,然后把RDD转化为df
数据源:本地文件:customerheaders.txt
数据样例:
id:string
full_name:string
...
'''
from pyspark.sql.types import IntegerType, DoubleType, StringType, StructType, StructField header_list = sc.textFile('customerheaders.txt') \
.map(lambda line: line.split(":")).collect() # 返回数组,元素为[id string]... def strToType(str): # string 映射到 DataType
if str == 'int':
return IntegerType()
elif str == 'double':
return DoubleType()
else:
return StringType() schema = StructType([StructField(t[0], strToType(t[1]), True) for t in header_list]) # 列表构造器 构造 StructType
for item in schema:
print(item) '''
对原始文件rdd中每一行进行规范化处理
数据举例:
7,Mohandas MacRierie,mmacrierie0@xrea.com,11/24/1990,Fliptune,-7.1309871,111.591546,
254,Rita Slany,rslany1@ucla.edu,8/7/1961,Yodoo,48.7068855,2.3371075,
'''
customers_rdd = sc.textFile('customers.txt') '''
一行字符串的解析函数
逻辑:
1,取出
'''
def parseLine(line):
tokens = zip(line.split(","), header_list) # 打包为元组的列表, [(7, [id string]),(Mohandas, [name string]), ... ]
parsed_tokens = []
for token in tokens:
token_type = token[1][1] # 取到数据的类型,然后转化该类型,并放入parsed_tokens
print('token_type = ', token_type)
if token_type == 'double':
parsed_tokens.append(float(token[0]))
elif token_type == 'int':
parsed_tokens.append(int(token[0]))
else:
parsed_tokens.append(token[0])
return parsed_tokens records = customers_rdd.map(parseLine) # 把文本字符串根据模式中对应的类型,转化为对象 for item in records.take(4):
print(item) df = spark.createDataFrame(records, schema) # rdd --> df
print (df) '''
其他一些API介绍:
rdd.foreach([FUNCTION]): 对每个元素执行函数
rdd.groupBy([CRITERA]): 分组聚合 like: ('a', 1) ('b',2) ('a', 3) --> ('a',Iterable(1,3)) ('b', 2)
rdd.subtract(rdd2): 做差集计算,元素在rdd中出现,没有在rdd2中出现
rdd.subtractByKey(rdd2): 同上,适用于KV rdd
rdd.sortBy([FUNCTION]): 自定义RDD元素排序
rdd.sortByKey(): 按照key 进行排序,其中key的类型必须实现了排序逻辑
rdd.join(rdd2): like : ('a', 1) ('b',2) ('a', 3) --> ('a',(1,3)) ('b', 2) '''
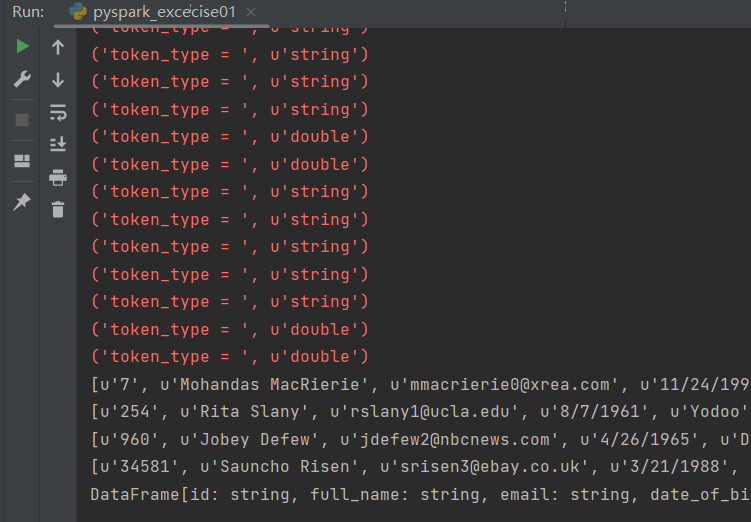
运行结果:
最新文章
- bahuanghou111
- CF731C Socks并查集(森林),连边,贪心,森林遍历方式,动态开点释放内存
- Windows 2003 FastCgi安装环境
- CoreAnimation5-图层时间和缓冲
- activity学习(1) 生命周期理解
- java内存映射文件
- jquery 简单的栏目切换
- C语言strstr()函数:返回字符串中首次出现子串的地址
- [物理学与PDEs]第2章习题3 Laplace 方程的 Neumann 问题
- 使用perconna xtrabackup备份脚本
- Codeforces Round #487 (Div. 2) E. A Trance of Nightfall (矩阵优化)
- jquery中把一串字符串分割,如:123456789后者abcdefg类型的
- find the most comfortable road(hdu1598)不错的并查集
- python自带的IDLE如何清屏
- L1-042 日期格式化
- hdu--DFS
- MySQL redo log及recover过程浅析
- linux下环境变量PS1-命令提示符
- 谨慎安装Python3.7.0,SSL低版本导致Pip无法使用
- 剑指Offer——圆圈中最后剩下的数(约瑟夫环)
热门文章
- FreeBSD 安装 fcitx5的配置
- 树莓派4B—LCD触摸屏和硬件串口配置
- bat想要写一个卸载软件的脚本,最后宣布失败[未完待续...]
- 微信小程序的全局弹窗以及全局实例
- .net core Ubuntu下docker部署(精简版)
- Linux:find 指令的选项 +n、-n、n
- 初学 Socket.io
- pip使用阿里云镜像
- [{"morpherRegistry":{},"dynaClass":{"dynaProperties":[{"indexed":false,"mapp
- [C#]判断一个IP是否在某个IP段内