SparkSql自定义数据源之读取的实现
一.sparksql读取数据源的过程
1.spark目前支持读取jdbc,hive,text,orc等类型的数据,如果要想支持hbase或者其他数据源,就必须自定义

2.读取过程
(1)sparksql进行 session.read.text()或者 session.read .format("text") .options(Map("a"->"b")).load("")

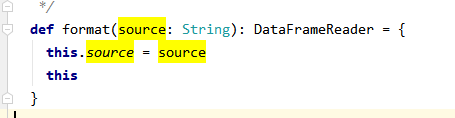

read.方法:创建DataFrameReader对象
format方法:赋值DataFrameReade数据源类型
options方法:赋值DataFrameReade额外的配置选项

进入 session.read.text()方法内,可以看到format为“text”
(2)进入load方法
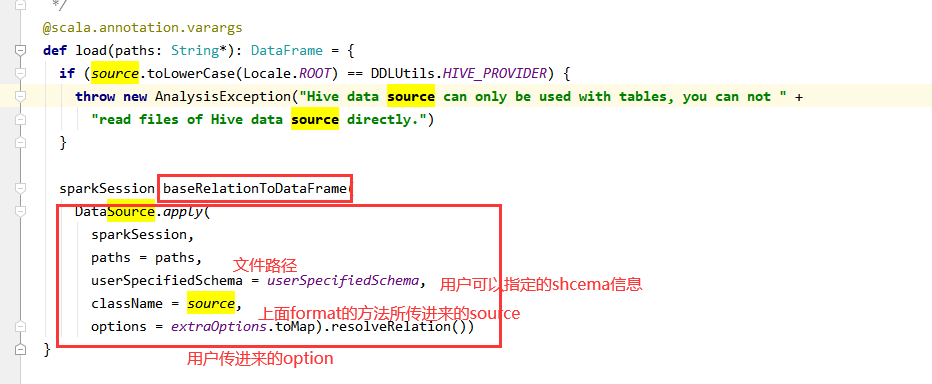
load原来是:sparkSession.baseRelationToDataFrame这个方法最终创建dataframe
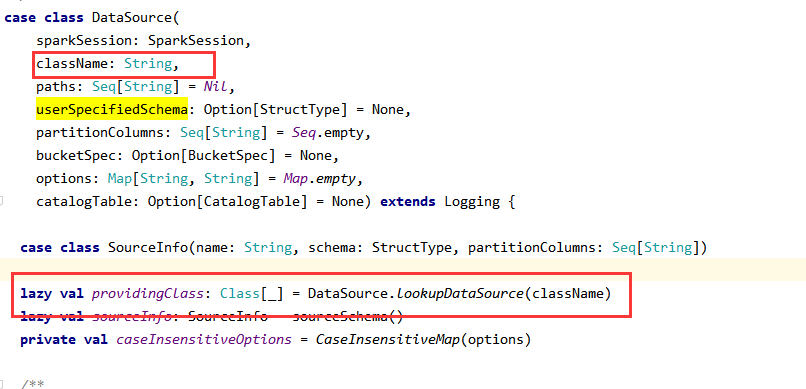
(3)进入DataSource的resolveRelation()方法
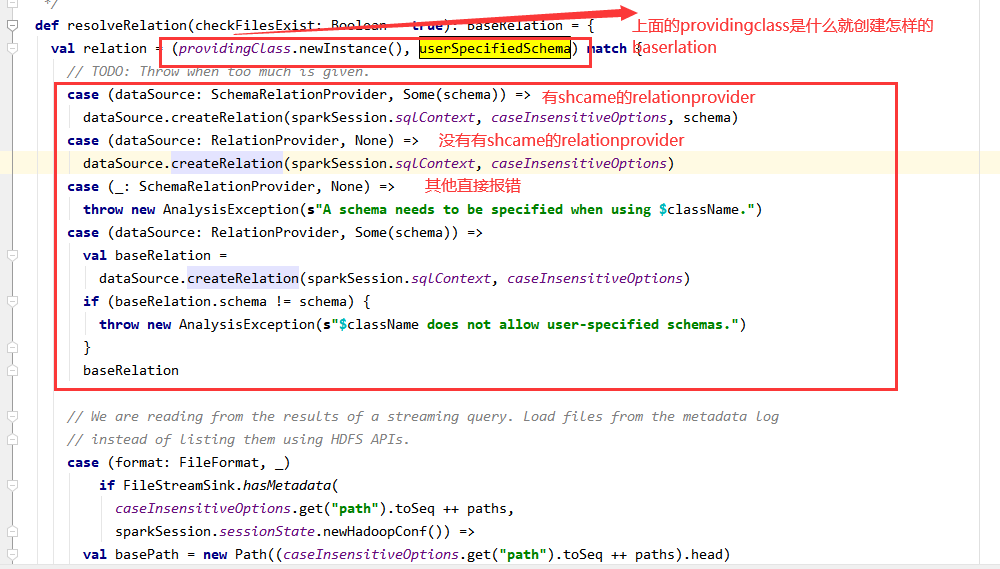
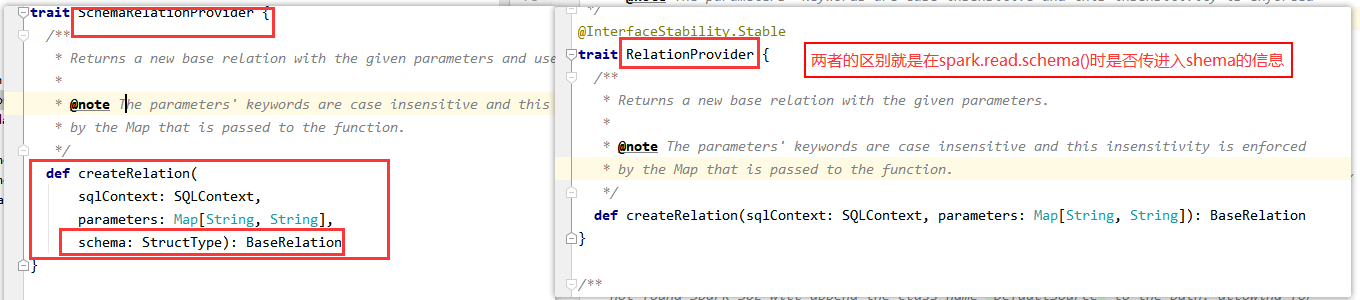
此段就是:providingClass这个类是哪一个接口的实现类,分为有shema与没有传入schema的两种
(3)providingClass是format传入的数据源类型,也就是前面的source
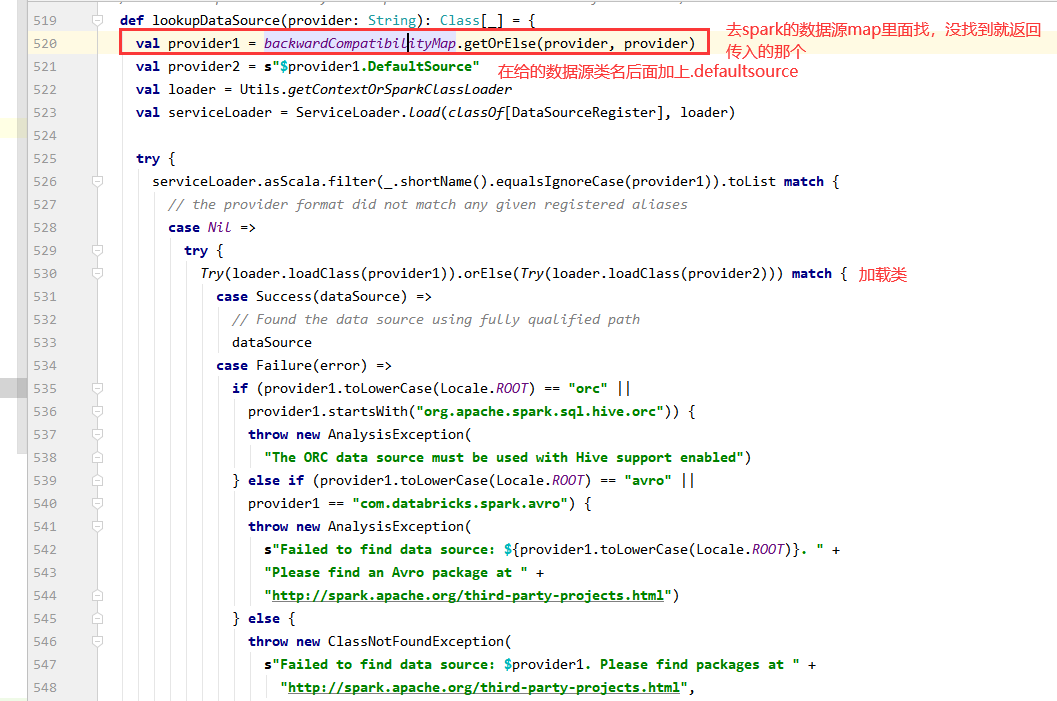
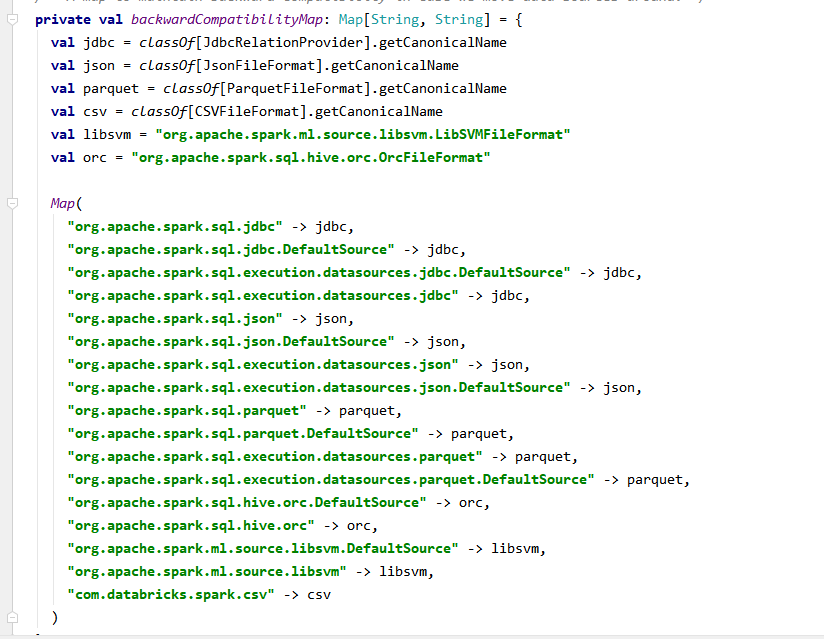
spark提供的所有数据源的map
4.得出结论只要写一个类,实现RelationProvider下面这个方法,在方法里面返回一个baserelation
def createRelation(sqlContext: SQLContext, parameters: Map[String, String]): BaseRelation
我们在实现baserelation里面的逻辑就可以了

5.看看spark读取jdbc类
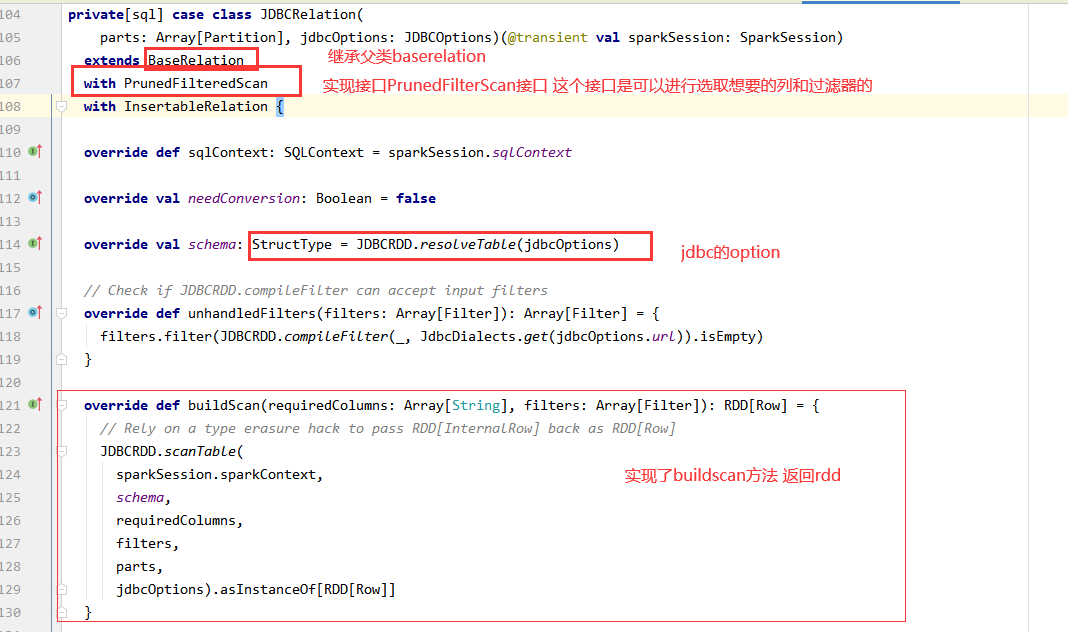
需要一个类,实现xxxScan这中类,这种类有三种,全局扫描tableScan,PrunedFilteredScan(列裁剪与谓词下推),PrunedScan ,
实现buildscan方法返回row类型rdd,结合baserelation有shcame这个变量 ,就凑成了dataframe
6.jdbcRdd.scanTable方法,得到RDD
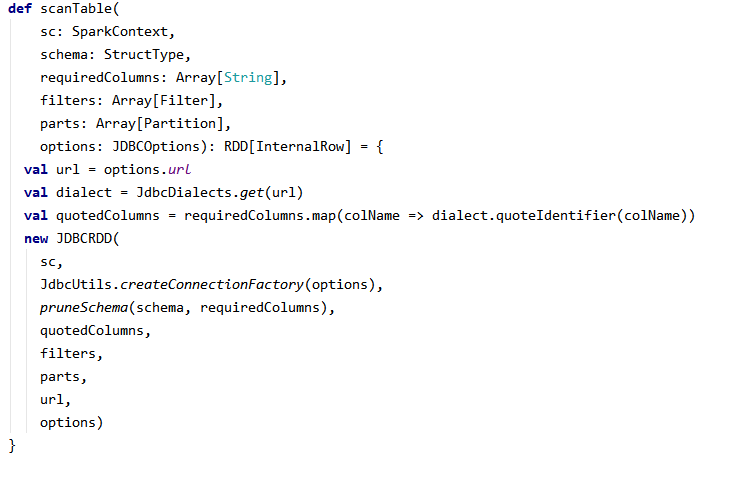
7.查看jdbcRDD的compute方法,是通过jdbc查询sql的方式获取数据
RDD的计算是惰性的,一系列转换操作只有在遇到动作操作是才会去计算数据,而分区作为数据计算的基本单位。在计算链中,无论一个RDD有多么复杂,其最终都会调用内部的compute函数来计算一个分区的数据。
override def compute(thePart: Partition, context: TaskContext): Iterator[InternalRow] = {
var closed = false
var rs: ResultSet = null
var stmt: PreparedStatement = null
var conn: Connection = null
def close() {
if (closed) return
try {
if (null != rs) {
rs.close()
}
} catch {
case e: Exception => logWarning("Exception closing resultset", e)
}
try {
if (null != stmt) {
stmt.close()
}
} catch {
case e: Exception => logWarning("Exception closing statement", e)
}
try {
if (null != conn) {
if (!conn.isClosed && !conn.getAutoCommit) {
try {
conn.commit()
} catch {
case NonFatal(e) => logWarning("Exception committing transaction", e)
}
}
conn.close()
}
logInfo("closed connection")
} catch {
case e: Exception => logWarning("Exception closing connection", e)
}
closed = true
}
context.addTaskCompletionListener{ context => close() }
val inputMetrics = context.taskMetrics().inputMetrics
val part = thePart.asInstanceOf[JDBCPartition]
conn = getConnection()
val dialect = JdbcDialects.get(url)
import scala.collection.JavaConverters._
dialect.beforeFetch(conn, options.asProperties.asScala.toMap)
// H2's JDBC driver does not support the setSchema() method. We pass a
// fully-qualified table name in the SELECT statement. I don't know how to
// talk about a table in a completely portable way.
//坐上每个分区的Filter条件
val myWhereClause = getWhereClause(part)
//最終查询sql语句
val sqlText = s"SELECT $columnList FROM ${options.table} $myWhereClause"
//jdbc查询
stmt = conn.prepareStatement(sqlText,
ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY)
stmt.setFetchSize(options.fetchSize)
rs = stmt.executeQuery()
val rowsIterator = JdbcUtils.resultSetToSparkInternalRows(rs, schema, inputMetrics)
//返回迭代器
CompletionIterator[InternalRow, Iterator[InternalRow]](
new InterruptibleIterator(context, rowsIterator), close())
}
最新文章
- [Machine Learning] 机器学习常见算法分类汇总
- cf378D(stl模拟)
- 第十章:Javascript子集和扩展
- easyui 中重复加载两次url
- Activity的task相关 详解
- ADO.NET 快速入门(三):从存储过程获取输出参数
- JavaScript HTML DOM 元素(节点)
- Gitlab管理下本地Git配置
- 解决vmware“二进制转换和长模式与此平台兼容.....”问题
- java基础之类与对象1
- U813.0操作员功能权限和数据权限的设置
- 当锚点遇到fixed
- 【BZOJ2876】【Noi2012】骑行川藏 拉格朗日乘法
- springboot最新版本自定义日志注解和AOP
- Teradata全面转型
- eclipse 对 hadoop1.2.1 hdfs 文件操作
- ElasticSearch 索引整体迁移方案
- 学JS的心路历程-JS支持面向对象?(二)
- 【转】【MySQL报错】ERROR 1558 (HY000): Column count of mysql.user is wrong. Expected 43, found 39.
- koa 核心源码介绍