python3下scrapy爬虫(第七卷:编辑器内执行scrapy)
2024-10-08 17:23:10
之前我们都是在终端切入到scrapy的路境内执行爬虫的,你要多敲多少行的字节,所以这次我们谈谈如何在编辑器里执行,这个你可以用在爬虫中,当你使用PYTHONWEB开发时尽量不要在编辑器内启动端口服务那样不容易关闭服务
先来看下我编写的爬虫文件
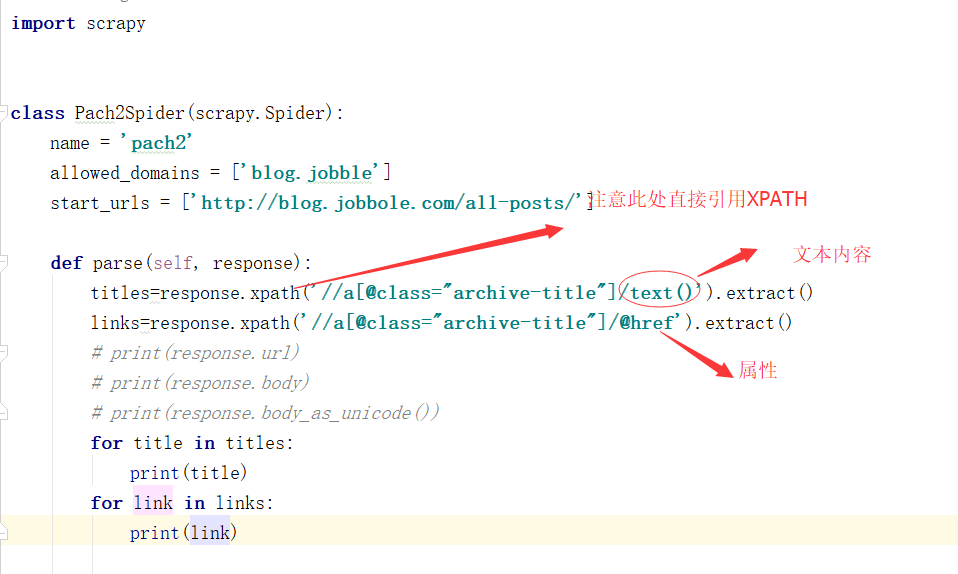
先来看下结果:
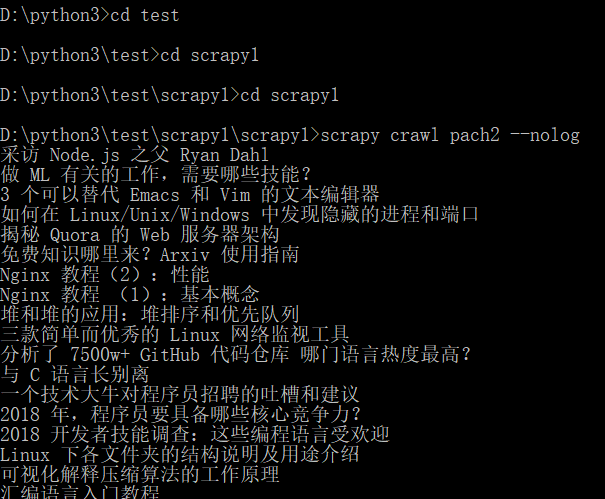
看到了吧不停的切换路径,也同时感到了xpath的强大了吧
总是切换到终端很麻烦,很多人为了炫耀自己的技术的强大都喜欢在终端各种操作,我个人觉得没有意义,明明走直线到家非得拐个弯
现在我们在文件中创建main.py文件 看一下路径 这个文件执行时是调动整个scrapy文件,那么文件创建的路径应该在外,看一下我编辑的位置
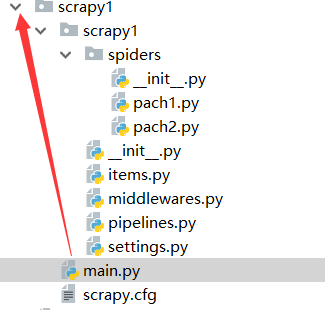
清晰明了 之前我写过pyMySQL的一篇随笔里面函数的用法和这里很相似

现在看下结果 看看哪个方便

最新文章
- UI第十四节——UIAlertController
- MVC将服务器端的物理路径转换为服务器路径
- 瞧一瞧迷一般的SQLDA
- Python namedtuple
- solr与.net系列课程(一)solr的安装与配置
- YII Framework学习教程-YII的国际化
- Microsoft Visual C++ Runtime Library Runtime Error的解决的方法
- 2014-2015 ACM-ICPC, Asia Xian Regional Contest G The Problem to Slow Down You 回文树
- 多线程归并排序的实现 java
- 什么是IP地址、子网掩码、路由和网关
- 配置Windows Server 2008 允许多用户远程桌面连接
- NodeJS 框架一览
- java.net.UnknownHostException 异常解决方案
- 简单的NIO使用实例
- 如何找出单链表中的倒数第k个元素
- Linux下完全删除用户
- vue实用组件——页面公共头部
- OVAL学习笔记
- Service生命周期以及应用
- day1 学习历程