Hadoop集群搭建的详细过程
Hadoop集群搭建
一、准备
三台虚拟机:master01,node1,node2
时间同步
1.date命令查看三台虚拟机时间是否一致
2.不一致时间同步:ntpdate ntp.aliyun.com
调整时区
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
查看jdk
java-version
修改主机名
三台分别执行vim /etc/hostname 修改为指定的主机名
关闭防火墙
systemctl stop firewalld
查看防火墙状态
systemctl status firewalld
取消防火墙自启
systemctl disable firewalld
静态ip设置
手动编辑配置文件
1、编辑网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
BOOTPROTO=static
HWADDR=00:0C:29:E2:B8:F2
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.137.150
GATEWAY=192.168.137.2
NETMASK=255.255.255.0
DNS1=192.168.190.2
DNS2=223.6.6.6 需要修改:HWADDR(mac地址,centos7不需要手动指定mac地址)
IPADDR(根据自己的网段,自定义IP地址)
GATEWAY(根据自己的网段填写对应的网关地址) 2、关闭NetworkManager,并取消开机自启
systemctl stop NetworkManager
systemctl disable NetworkManager 3、重启网络服务
systemctl restart network
配置免密登录
1、生成密钥
ssh-keygen -t rsa 2、配置免密登录
ssh-copy-id master01
ssh-copy-id node1
ssh-copy-id nade2 3、测试免密登录
ssh node1
配置映射文件:/etc/hosts
192.168.137.150 master01
192.168.137.160 node1
192.168.137.170 node2
二、搭建Hadoop集群
1、上传安装包并解压
cd /usr/local/soft/
解压:
tar -zxvf
2、配置环境变量
vim /etc/propfile
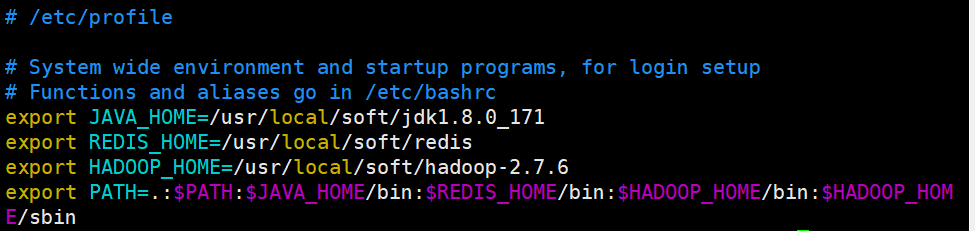
重新加载环境变量
source /etc/profile
3、修改Hadoop配置文件
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop
配置hadoop-env.sh

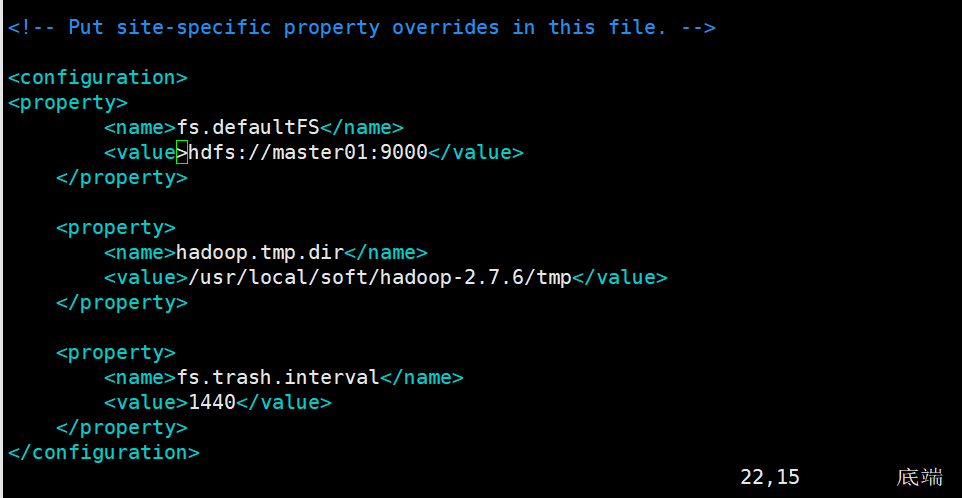
配置core-site.xml
fs.defaultFS: 默认文件系统的名称。其方案和权限决定文件系统实现的URI。uri的方案确定命名文件系统实现类的配置属性(fs.scheme.impl)。uri的权限用于确定文件系统的主机、端口等。
hadoop.tmp.dir:是 hadoop文件系统依赖的基本配置,很多配置路径都依赖它,它的默认位置是在 /tmp/{$user}下面,注意这是个临时目录!!!
因此,它的持久化配置很重要的! 如果选择默认,一旦因为断电等外在因素影响,/tmp/{$user}下的所有东西都会丢失。
fs.trash.interval:启用垃圾箱配置,dfs命令删除的文件不会立即从HDFS中删除。相反,HDFS将其移动到垃圾目录(每个用户在
/user/<username>/.Trash下都有自己的垃圾目录)。只要文件保留在垃圾箱中,文件可以快速恢复。<property>
<name>fs.defaultFS</name>
<value>hdfs://master01:9000</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/tmp</value>
</property> <property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
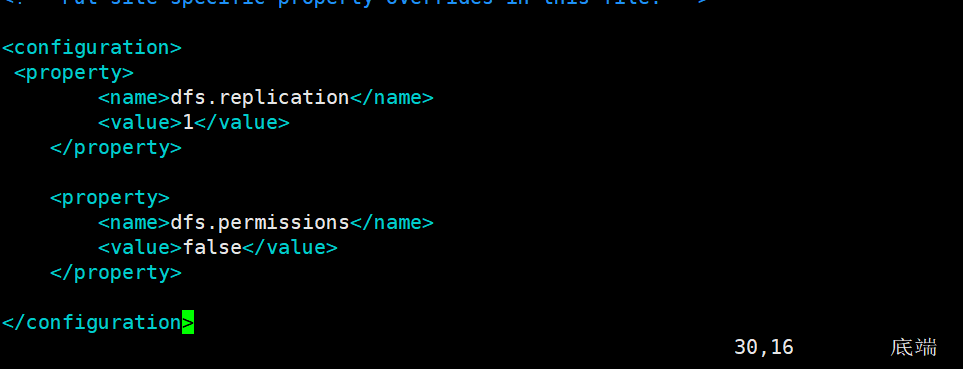
配置hdfs-site.xml
dfs.replication:每个datanode上只能存放一个副本。我这里就2个datanode
dfs.permissions:如果为“true”,则在HDFS中启用权限检查。如果为“false”,则关闭权限检查,但所有其他行为保持不变。从一个参数值切换到另一个参数值不会更改文件或目录的模式、所有者或组。
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <property>
<name>dfs.permissions</name>
<value>false</value>
</property>
配置mapred-site.xml.template
mapreduce.framework.name:用于执行MapReduce作业的运行时框架。
mapreduce.jobhistory.address:Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过*mr-jobhistory-daemon.sh start historyserver命令来启动Hadoop历史服务器。我们可以通过Hadoop jar的命令来实现我们的程序jar包的运行,关于运行的日志,我们一般都需要通过启动一个服务来进行查看,就是我们的JobHistoryServer,我们可以启动一个进程,专门用于查看我们的任务提交的日志。mapreduce.jobhistory.address和mapreduce.jobhistory.webapp.address默认的值分别是0.0.0.0:10020和0.0.0.0:19888
1、复制:
[root@master01 hadoop]# cp mapred-site.xml.template mapred-site.xml
2、修改
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <property>
<name>mapreduce.jobhistory.address</name>
<value>master01:10020</value>
</property> <property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master01:19888</value>
</property>
配置yarn-site.xml
yarn.resourcemanager.hostname:指定yarn主节点
yarn.nodemanager.aux-services:NodeManager上运行的附属服务。需配置成 mapreduce_shuffle,才可运行MapReduce程序。默认值:“”
yarn.log-aggregation-enable:yarn日志聚合功能开关
yarn.log-aggregation.retain-seconds:日志保留时限,默认7天
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master01</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
配置slaves
从节点的信息
node1
node2
4、分发Hadoop到node1、node2
cd /usr/local/soft/
scp -r hadoop-2.7.6/ node1:`pwd`
scp -r hadoop-2.7.6/ node2:`pwd`
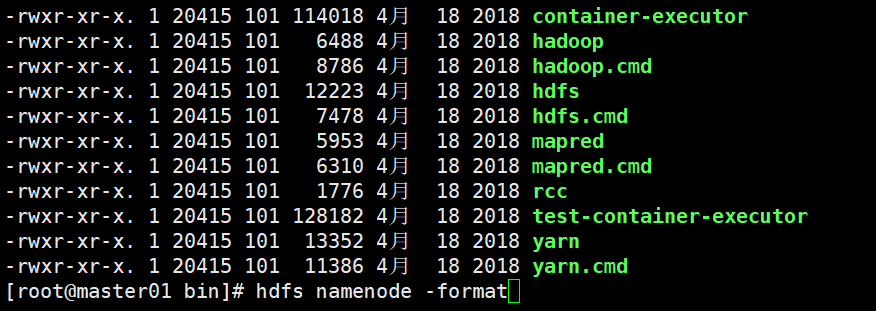
5、格式化namenode(第一次启动的时候需要执行,以及每次修改核心配置文件后都需要)
在主节点下进行格式化
hdfs namenode -format
6、启动Hadoop集群
start-all.sh
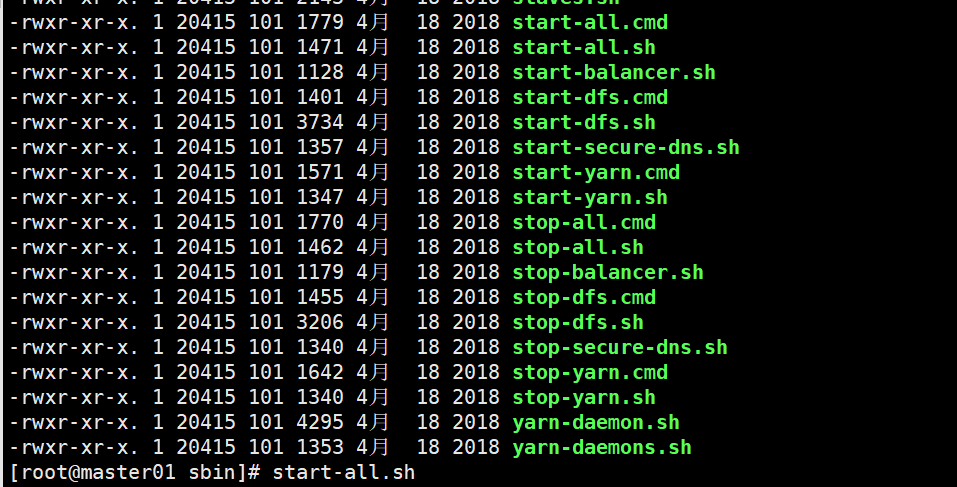
7、查看master01、node1、node2上的进程
jps
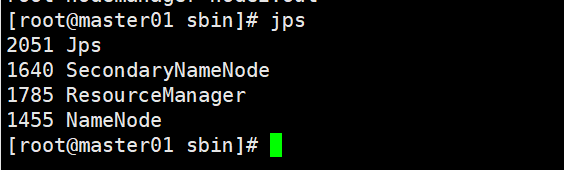
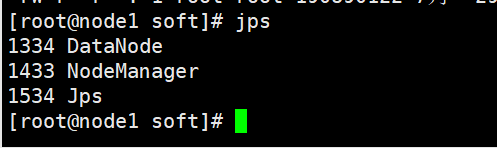
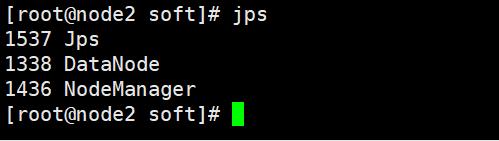
NameNode:接受客户端的读/写服务,收集 DataNode 汇报的 Block 列表信息
DataNode:真实数据存储的地方(block)
SecondaryNameNode:做持久化的时候用到
| 进程 | master01(主) | node1(从) | node2(从) |
|---|---|---|---|
| NameNode | √ | ||
| SecondaryNameNode | √ | ||
| ResourceManager | √ | ||
| DataNode | √ | √ | |
| NodeManager | √ | √ |
8、访问HDFS的web界面
http://192.168.137.150:50070
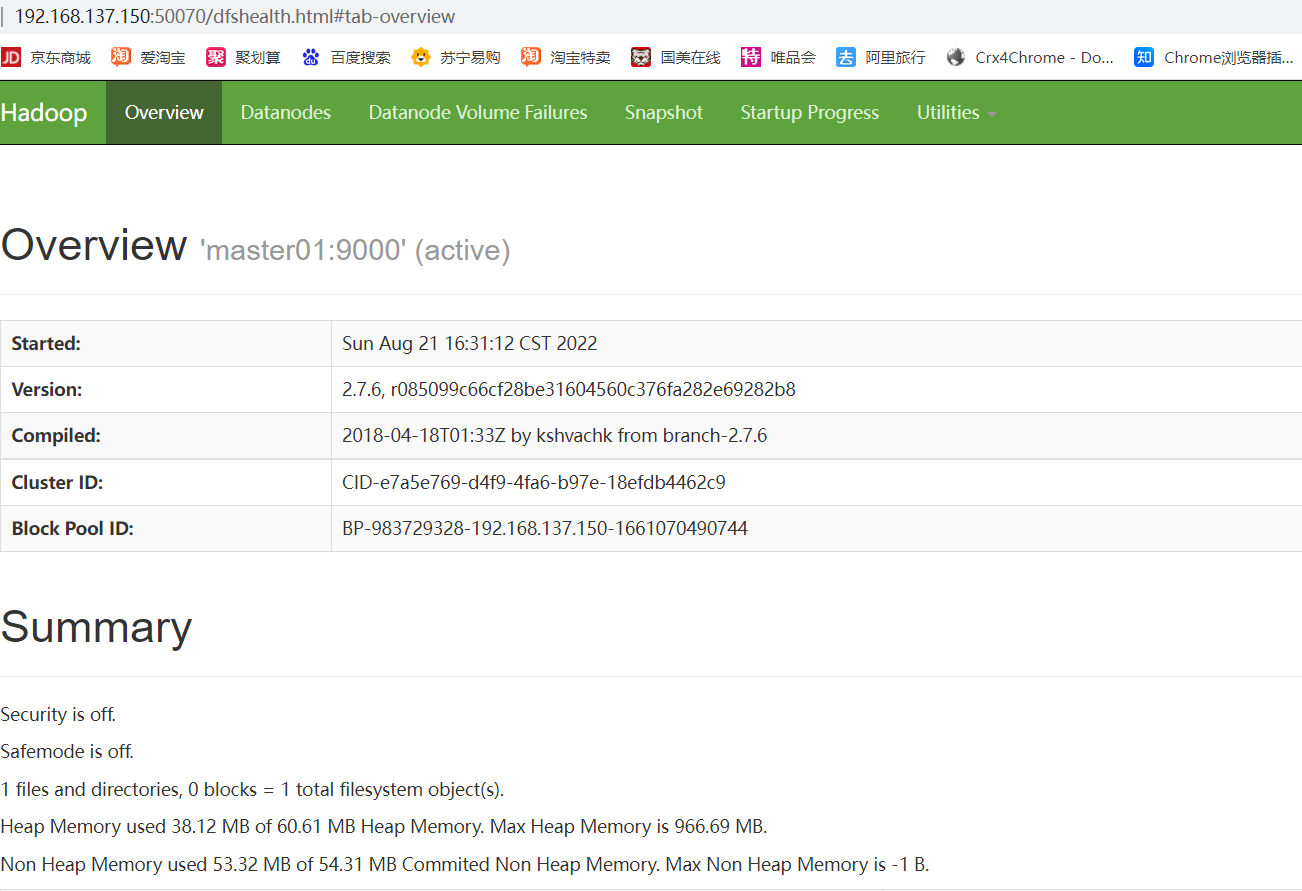
9、访问YARN的web界面
http://192.168.137.150:8088
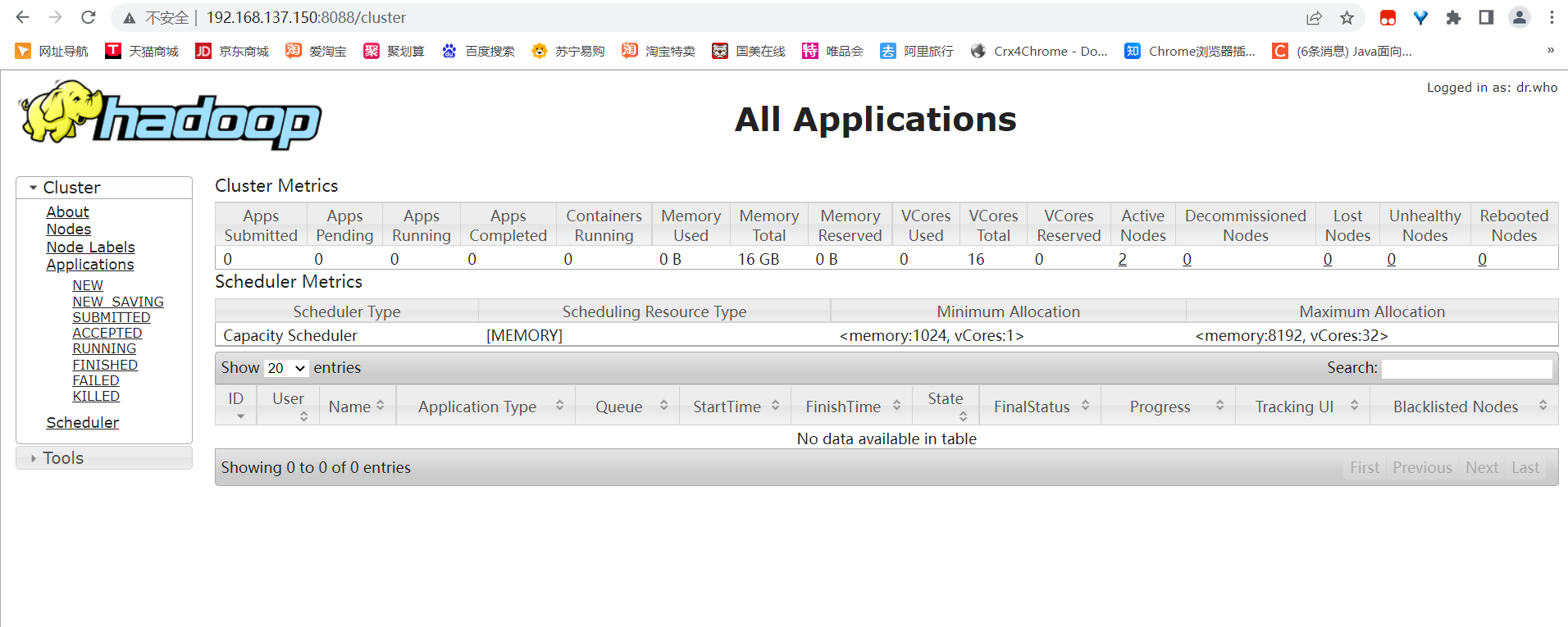
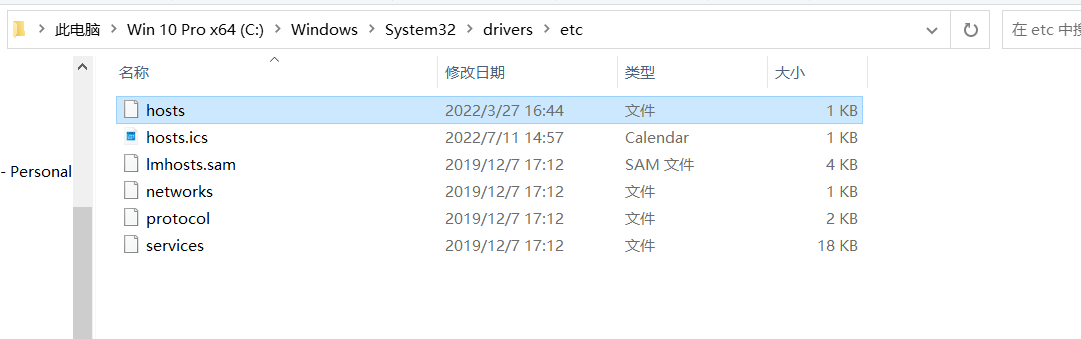
10、配置windows映射,让电脑可以下载hadoop上的文件
- 首先到这个目录c盘的这个目录下。c盘文件不允许修改,点击hosts的属性,安全,编辑,给user用户一个修改权限就可以修改了。
添加:192.168.137.150 master01
192.168.137.160 node1
192.168.137.170 node2
最新文章
- Ajax部分
- Spring Bean详细讲解
- AspNetPager分页控件配置
- Lucene 查询工具 LQT
- python数据类型和字符串(三)
- PHP序列化以及反序列化系列[1]--PHP序列化格式的写法
- MySQL(六) —— 运算符和函数
- svn安装
- Zybo智能小车识别图像中的文字
- 5个缺失的 JavaScript 数字格式化函数
- 2015.1写留言板的时用的 知识点和函数 --->总结
- Android4.4 + WebAPI 实现拍照上传
- bzoj 1013 [JSOI2008]球形空间产生器sphere(高斯消元)
- IOS-AssetsLibrary(相册)框架介绍
- Java高级特性之枚举学习总结
- 简单cpu处理器
- jsp中,对window对象的简单总结
- iis的web站点配置
- PAT乙级-1056. 组合数的和(15)
- maven打包如何跳过测试