Python正则式 - re
2024-09-03 22:02:53
目录
1. 相关概念
1.1. rstring
rstring: 非转义的原始字符串
普通字符中可能包含转义字符,用于表示对应的特殊含义的,比如最常见的'\n'表示换行,'\t'表示Tab等。而如果是以r开头,那么说明后面的字符,都是普通的字符了,即如果是'\n'那么表示一个反斜杠字符,一个字母n,而不是表示换行了。
rstring常用于正则表达式,对应着re模块。
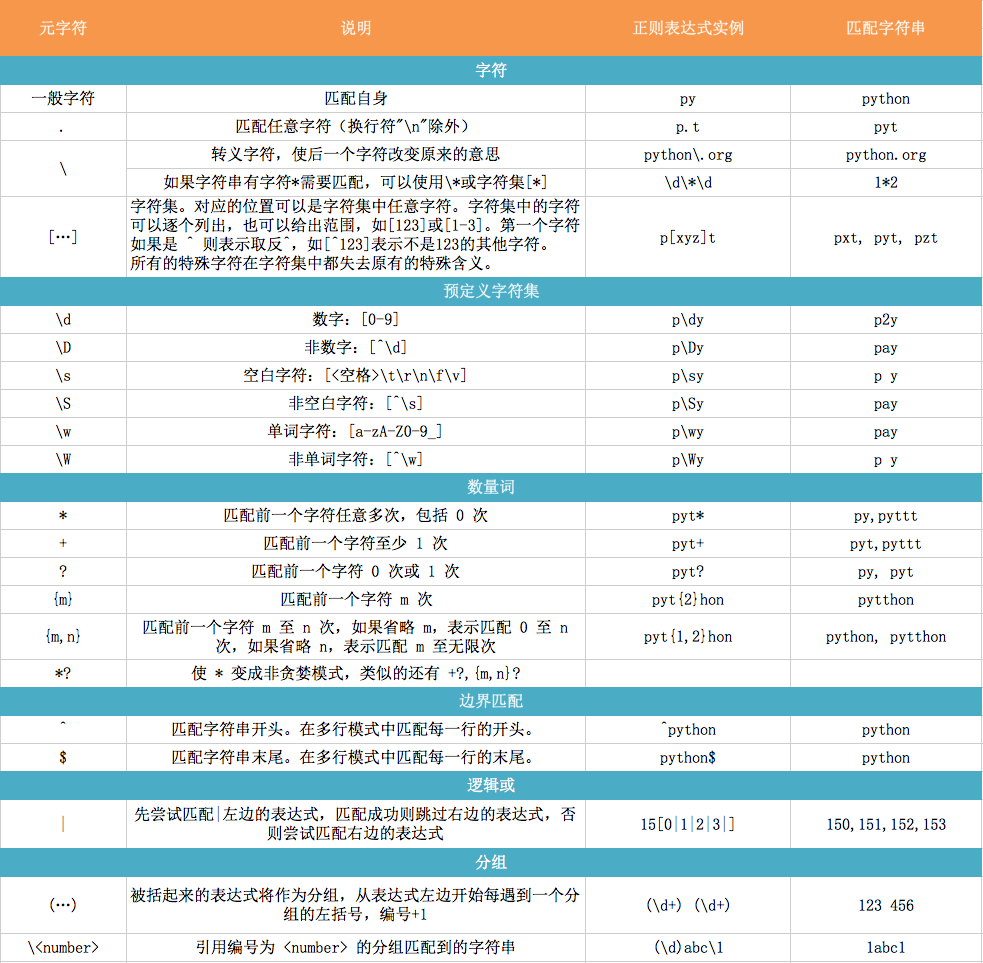
1.2. 元字符

2. 模式Pattern
模式字符串使用特殊的语法来表示一个正则表达式:
- 字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
- 多数字母和数字前加一个反斜杠时会拥有不同的含义。
- 标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
- 反斜杠本身需要使用反斜杠转义。
- 由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'\t',等价于 '\t')匹配相应的特殊字符。
实例
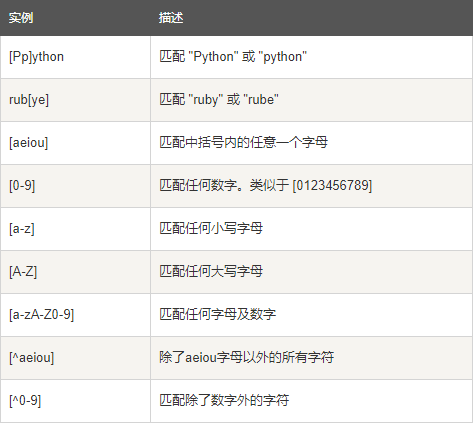
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
2.1. re.flag

| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感(re.IGNORECASE) |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $(re.MULTILINE) |
| re.S | 使 . 匹配包括换行在内的所有字符(re.DOTALL) |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
3. API
re.compile(re_pattern) -> Pattern
re.match(re_pattern: str, origin_string, flags=0) # return None if Failed...
re.search(pattern, string, flags=0) # 匹配任何位置
re.MatchObject.group() # 返回匹配对象的字符串
匹配对象的其他方法还有 start()、end()、span(). 具体见下文
re.sub(pattern, repl, string, count=0) # repl: 替换字符串,也可以为一个函数
re.compile(pattern[, flags]) # 生成一个表达式对象(re.RegexObject),一般供给 match()、search()、findall()
findall(string, pos=0, endpos=0) # 返回所有符合正则的字符串列表
finditer(pattern, string, flags=0) # 类似findall, 返回多个符合条件的正则对象(pattern)迭代器
re.split(pattern, string, maxsplit, flags) # 按正则的格式分割字符串
使用示例
pattern = re.compile(r'\d+')
m = pattern.match('abcd 1234')
t = pattern.findall('abc 123')
在上面,当匹配成功时返回一个 Match 对象,其中:
- group([group1, …]): 用于获得一个或多个分组匹配的字符串
- group() 或 group(0): 返回re整体匹配的字符串
- group(n,m): 返回组号为(n,m)所匹配的字符串
- groups(): 以tuple形式返回所有匹配的group
- start([group=0]): 用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引)
- end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1)
- span([group]): 返回 (start(group), end(group))
4. 其他
4.1. 单词边界 '\b'
字符的位置是非常重要的。如果它位于要匹配的字符串的开始,它在单词的开始处查找匹配项。如果它位于字符串的结尾,它在单词的结尾处查找匹配项。
import re
str1='i love python '
str2=re.findall(r'\bon',str1)
str3=re.findall(r'on\b',str1)
print(str2)
print(str3)
输出:
[]
['on']
4.2. 贪婪和非贪婪
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。
贪婪模式下字符串查找会直接走到字符串结尾去匹配,如果不相等就向前寻找,这一过程称为回溯。
4.3. 切片、替换
re.subn(pattern, repl, string[, count]) --> (sub(repl, string[, count]), 替换次数)
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
- 当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。
- 当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count用于指定最多替换次数,不指定时全部替换。
pattern = re.compile(r'(\w+)(\w+)(\d+)')
#先切片测试
print re.split(pattern,str)
print re.sub(pattern,r'\3 \1',str)
#subn统计sub替换次数
print re.subn(pattern,r'\3 \1',str)
最新文章
- Anti XSS 防跨站脚本攻击库
- javascript中的浅复制和深复制
- 【转载】C++——CString用法大全
- mysql 自定义排序顺序
- PDF判断打印是A4还是B5
- Lucene索引的初步创建
- GCC 命令行具体解释
- MyEclipse中jquery文件报错
- dos下遍历目录和文件的代码(主要利用for命令)
- Spring MVC 学习笔记 json格式的输入和输出
- 好多NFS的文章
- Team City的安装1
- editormd使用教程
- vue组件之前嵌套
- 题解 P4692 【[Ynoi2016]谁的梦】
- sql语句进行写数据库时,字符串含有'的处理方式
- C#设计模式——单例模式的实现
- activiti官网实例项目activiti-explorer之扩展流程节点属性2
- 怎么使用小程序的data-*属性?
- Map集合——双列集合