hive学习笔记之三:内部表和外部表
2024-10-19 02:20:30
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
《hive学习笔记》系列导航
本篇概览
- 本文是《hive学习笔记》系列的第三篇,要学习的是各种类型的表及其特点,主要内容如下:
- 建库
- 内部表(也叫管理表或临时表)
- 外部表
- 表的操作
接下来从最基本的建库开始
建库
- 创建名为test的数据库(仅当不存在时才创建),添加备注信息test database:
create database if not exists test
comment 'this is a database for test';
- 查看数据库列表(名称模糊匹配):
hive> show databases like 't*';
OK
test
test001
Time taken: 0.016 seconds, Fetched: 2 row(s)
- describe database命令查看此数据库信息:
hive> describe database test;
OK
test this is a database for test hdfs://node0:8020/user/hive/warehouse/test.db hadoop USER
Time taken: 0.035 seconds, Fetched: 1 row(s)
- 上述命令可见,test数据库在hdfs上的存储位置是hdfs://node0:8020/user/hive/warehouse/test.db,打开hadoop的web页面,查看hdfs目录,如下图,该路径的文件夹已经创建,并且是以.db结尾的:
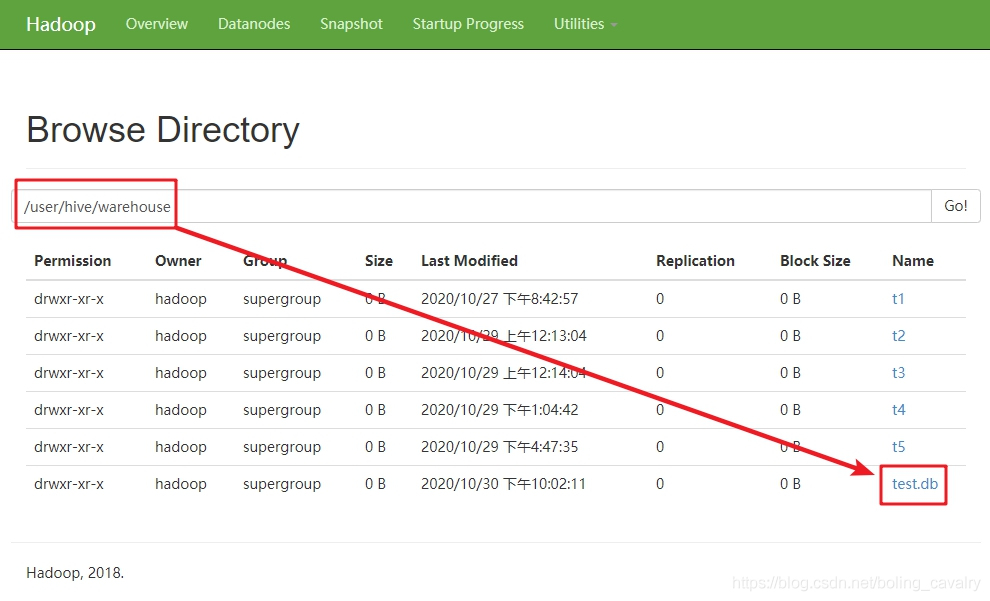
5. 新建数据库的文件夹都在/user/hive/warehouse下面,这是在中配置的,如下图红框:

6. 删除数据库,加上if exists,当数据库不存在时,执行该语句不会返回Error:
hive> drop database if exists test;
OK
Time taken: 0.193 seconds
以上就是常用的库相关操作,接下来实践表相关操作;
内部表
- 按照表数据的生命周期,可以将表分为内部表和外部表两类;
- 内部表也叫管理表或临时表,该类型表的生命周期时由hive控制的,默认情况下数据都存放在/user/hive/warehouse/下面;
- 删除表时数据会被删除;
- 以下命令创建的就是内部表,可见前面两篇文章中创建的表都是内部表:
create table t6(id int, name string)
row format delimited
fields terminated by ',';
- 向t6表新增一条记录:
insert into t6 values (101, 'a101');
- 使用hadoop命令查看hdfs,可见t6表有对应的文件夹,里面的文件保存着该表数据:
[hadoop@node0 bin]$ ./hadoop fs -ls /user/hive/warehouse/t6
Found 1 items
-rwxr-xr-x 3 hadoop supergroup 9 2020-10-31 11:14 /user/hive/warehouse/t6/000000_0
- 查看这个000000_0文件的内容,如下可见,就是表内的数据:
[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t6/000000_0
101 a101
- 执行命令drop table t6;删除t6表,再次查看t6表对应的文件,发现整个文件夹都不存在了:
[hadoop@node0 bin]$ ./hadoop fs -ls /user/hive/warehouse/
Found 5 items
drwxr-xr-x - hadoop supergroup 0 2020-10-27 20:42 /user/hive/warehouse/t1
drwxr-xr-x - hadoop supergroup 0 2020-10-29 00:13 /user/hive/warehouse/t2
drwxr-xr-x - hadoop supergroup 0 2020-10-29 00:14 /user/hive/warehouse/t3
drwxr-xr-x - hadoop supergroup 0 2020-10-29 13:04 /user/hive/warehouse/t4
drwxr-xr-x - hadoop supergroup 0 2020-10-29 16:47 /user/hive/warehouse/t5
外部表
- 创建表的SQL语句中加上external,创建的就是外部表了;
- 外部表的数据生命周期不受Hive控制;
- 删除外部表的时候不会删除数据;
- 外部表的数据,可以同时作为多个外部表的数据源共享使用;
- 接下来开始实践,下面是建表语句:
create external table t7(id int, name string)
row format delimited
fields terminated by ','
location '/data/external_t7';
- 查看hdfs文件,可见目录/data/external_t7/已经创建:
[hadoop@node0 bin]$ ./hadoop fs -ls /data/
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2020-10-31 12:02 /data/external_t7
- 新增一条记录:
insert into t7 values (107, 'a107');
- 在hdfs查看t7表对应的数据文件,可以见到新增的内容:
[hadoop@node0 bin]$ ./hadoop fs -ls /data/external_t7
Found 1 items
-rwxr-xr-x 3 hadoop supergroup 9 2020-10-31 12:06 /data/external_t7/000000_0
[hadoop@node0 bin]$ ./hadoop fs -cat /data/external_t7/000000_0
107,a107
- 试试多个外部表共享数据的功能,执行以下语句再建个外部表,名为t8,对应的存储目录和t7是同一个:
create external table t8(id_t8 int, name_t8 string)
row format delimited
fields terminated by ','
location '/data/external_t7';
- 建好t8表后立即查看数据,发现和t7表一模一样,可见它们已经共享了数据:
hive> select * from t8;
OK
107 a107
Time taken: 0.068 seconds, Fetched: 1 row(s)
hive> select * from t7;
OK
107 a107
Time taken: 0.074 seconds, Fetched: 1 row(s)
- 接下来删除t7表,再看t8表是否还能查出数据,如下可见,数据没有被删除,可以继续使用:
hive> drop table t7;
OK
Time taken: 1.053 seconds
hive> select * from t8;
OK
107 a107
Time taken: 0.073 seconds, Fetched: 1 row(s)
- 把t8表也删掉,再去看数据文件,如下所示,依然存在:
[hadoop@node0 bin]$ ./hadoop fs -cat /data/external_t7/000000_0
107,a107
- 可见外部表的数据不会在删除表的时候被删除,因此,在实际生产业务系统开发中,外部表是我们主要应用的表类型;
表的操作
- 再次创建t8表:
create table t8(id int, name string)
row format delimited
fields terminated by ',';
- 修改表名:
alter table t8 rename to t8_1;
- 可见修改表名已经生效:
hive> alter table t8 rename to t8_1;
OK
Time taken: 0.473 seconds
hive> show tables;
OK
alltype
t1
t2
t3
t4
t5
t6
t8_1
values__tmp__table__1
values__tmp__table__2
Time taken: 0.029 seconds, Fetched: 10 row(s)
- 添加字段:
alter table t8_1 add columns(remark string);
查看表结构,可见已经生效:
hive> desc t8_1;
OK
id int
name string
remark string
Time taken: 0.217 seconds, Fetched: 3 row(s)
至此,咱们对内部表和外部表已经有了基本了解,接下来的文章学习另一种常见的表类:分区表;
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
最新文章
- CSS导航菜单水平居中的多种方法
- RASPBERRY PI 外设学习资源
- OD使用教程
- C之五子棋
- 【Mysql】日期时间格式化
- mysql数据库表格导出为excel表格
- js优化 ----js的有序加载
- Git权威指南 读笔(1)
- Chapter 1 First Sight——36
- [Unity]Unity开发NGUI代码实现ScrollView(放大视图)
- VUE2.0实现购物车和地址选配功能学习第三节
- Angular环境准备和Angular cli
- Java 用Freemarker完美导出word文档(带图片)
- MySQL视图,触发器,事务,存储过程,函数
- C# 中使用特性获得函数被调用的路径,行号和函数
- Linux 文件大小查找排序
- 人工智能为什么选择Python语言?
- 本地navicat远程连接到云服务器数据库
- java中基础数据类型的应用
- 可以用的远程maven地址