Python迭代器详解
# collections是一个包含了许多类型的module
from collections import Iterator,Iterable,Generator
可迭代对象iterable
可迭代的对象的意思是就是说这个实体是可迭代的,例如字符、列表、元组、字典、迭代器等等,可以用for ... in进行循环,可以使用for循环迭代的标志是内部实现了__iter__方法。
可迭代对象仅含有__iter__的内部方法,你可以通过封装next()方法(python3中为__next__())来将其做成一个迭代器,以生成器(generator,特殊的函数类型的迭代器)为例,你可以通过yield关键字来做一个迭代器,只不过名字被叫做generator,yield可以看做就是为对象添加了__iter__方法和指示下一次迭代的next()/__next__()方法。
使用isinstance(实体名,Iterable)可判断是否为可迭代对象
迭代器iterator
迭代器就是实现了迭代方式的容器,iterable对象一般只能按默认的正序方式进行迭代,你可以通过为其添加__next__()/next()方法来定制不同的迭代方式,这样通过next方法封装起来的迭代对象生成器就被称作迭代器。与iterable相比iterator多了一个next()方法,next()方法用于定制for循环时具体的返回值及返回顺序以及处理StopIteration异常等。
iterator必定是iterable的,因此其必然含有__iter__方法,此方法保证了iterator是可以迭代的,个人认为可以将__iter__()方法看做迭代器的入口,此入口告诉python对象是可for循环的,当你还为class定义了__next__方法时python的for循环会直接调用__next__()方法进行迭代,因此对于实现了__next__方法的迭代器来讲__iter__方法是一个不可或缺的鸡肋方法,不可或缺是因为他是可迭代的标识,鸡肋是因为他不会实质性的起作用,虽然他是迭代器的入口但却不是迭代的起始点,也因此iterator的__iter__方法可以随意返回self或者self.属性或者None。
使用isinstance(实体名,Iterator)可判断是否为迭代器
生成器generator
generator对象是一种特殊的iterator函数,它会在执行过程中保存执行的上下文环境,并在下次循环中从yield语句后继续执行,生成器的标志就是yield关键字。
generator不需要抛出StopIteration异常(你可以看做yield已经在内部实现了StopIteration跳出循环),函数并没有将序列项一次生成,所以generator在实现上可以有无穷个元素,而不需要无穷的存储空间,这在内存优化方面很有用处。
使用isinstance(实体名,Generator)可判断是否为生成器。
生成器的创建办法有两种:
- 通过函数创建,称作generator function
- 通过推导式创建,例如g=(x*2 for x in range(10)),称作generator expression
__iter__()和iter()
python有一个built-in函数iter()用来从序列对象,如String, list,tuple中生成迭代器。
__iter__()方法是python的魔法方法,如果对象是iterator那么for循环时python会直接调用__next__()方法拿到循环的下一个值,直到遇到StopIteration错误时退出循环。
在python中,如果对象不含__next__方法,但是__iter__只返回self的话,尝试对对象使用for循环就会报“TypeError: iter() returned non-iterator of type [类名]”,针对这种错误要么加一个__next__()方法,要么__iter__()返回一个包含__next__()方法的迭代器对象。那么按理来说string、list这些iterable对象也是只含有__iter__不含__next__的,为何他们就可以for循环呢,这点在本文中的示例三中有演示,如果__iter__魔法方法调用了iter()方法,返回了一个迭代器对象,那么即便其不包含__next__也可以进行迭代
二、示例
示例一:(Python3环境)
# 先看一个iterale对象
In [91]: from collections import Iterator,Iterable,Generator
In [92]: a=['ShanXi','HuNan','HuBei','XinJiang','JiangSu','XiZang','HeNan','HeBei']
In [93]: isinstance(a,Iterator),isinstance(a,Iterable),isinstance(a,Generator)
Out[93]: (False, True, False)
# 可以看到这是一个可迭代对象但并不是迭代器,我们把它搞成一个迭代器试试看:
# 方法一:
In [102]: def generator_list(a):
...: for e in a:
...: yield 'Province:\t'+e
In [105]: for province in generator_list(a):
...: print(province)
Province: ShanXi
# ...其他输出省略
In [122]: isinstance(generator_list(a),Generator),isinstance(generator_list(a),Iterable),isinstance(generator_list(a),Iterator)
Out[122]: (True, True, True)
# 方法2:
class iterator_list(object):
def __init__(self,a):
self.a=a
self.len=len(self.a)
self.cur_pos=-1
def __iter__(self):
return self
def __next__(self): # Python3中只能使用__next__()而Python2中只能命名为next()
self.cur_pos +=1
if self.cur_pos<self.len:
return self.a[self.cur_pos]
else:
raise StopIteration() # 表示至此停止迭代
In [144]: for province in iterator_list(a):
...: print(province)
In [147]: isinstance(iterator_list(a),Generator),isinstance(iterator_list(a),Iterable),isinstance(iterator_list(a),Iterator)
Out[147]: (False, True, True)
# iterator当然是iterable,因为其本身含有__iter__方法。
问题一:既然可迭代对象也可以使用for循环遍历,为何还要使用迭代器呢?
一般情况下不需要将可迭代对象封装为迭代器。但是想象一种需要重复迭代的场景,在一个class中我们需要对输入数组进行正序、反序、正序step=1、正序step=2等等等等的多种重复遍历,那么我们完全可以针对每一种遍历方式写一个迭代容器,这样就不用每次需要遍历时都费劲心思的写一堆对应的for循环代码,只要调用相应名称的迭代器就能做到,针对每一种迭代器我们还可以加上类型判断及相应的处理,这使得我们可以不必关注底层的迭代代码实现。
从这种角度来看,你可以将迭代器看做可迭代对象的函数化,有一个非常流行的迭代器库itertools,其实就是如上所说的,他为很多可迭代类型提前定义好了一些列的常见迭代方式,并封装为了迭代器,这样大家就可以很方便的直接通过调用此模块玩转迭代。
此外iterator还可以节省内存,这点在问题二会描述。
问题二:生成器(generator)如何节约内存的?
generator的标志性关键字yield其实可以看作return,以本文上述的generator_list()方法为例,generator_list(a)就是一个生成器。
生成器最大的好处在于:generator_list(a)并不会真正执行函数的代码,只有在被循环时才会去获取值,且每次循环都return一个值(即yield一个值),在处理完毕后下次循环时依然使用相同的内存(假设处理单位大小一样)来获取值并处理,这样在一次for循环中函数好像中断(yield)了无数次,每次都用相同大小的内存来存储被迭代的值。
yield与return的最大区别就是yield并不意味着函数的终止,而是意味着函数的一次中断,在未被迭代完毕之前yield意味着先返回一次迭代值并继续下一次函数的执行(起始位置是上一次yeild语句结束),而return则基本意味着一个函数的彻底终止并返回一个全量的返回值。
因此generator是为了节省内存的,而且将函数写为一个生成器可以使函数变的可迭代,如果我们想遍历函数的返回值,我们不用再单独定义一个可迭代变量存储函数的返回值们,而是直接迭代生成器函数即可(除非函数本身返回一个全量的可迭代对象)。
同理iterator的__iter__()方法只是一个迭代的入口,每次调用__next__()时返回一个迭代值,同样以O(1)的空间复杂度完成了迭代。
问题三:iterator与generator的异同?
generator是iterator的一个子集,iterator也有节约内存的功效,generator也可以定制不同的迭代方式。
官网解释:Python’s generators provide a convenient way to implement the iterator protocol.
其实说白了就是generator更加轻量,日常编程里你可能常常使用它,而iterator一般使用系统提供的工具就可以了,极少会自己写一个。
示例二:(Python2环境)
#-*- coding: utf-8 -*-
# 简便起见这里只写python2的代码,想要在python3中运行将print修改下再把next()改名为__next__即可。
list=['a','b','c','d','e','f','g','h','i','j']
class iter_standard(object):
def __init__(self,list):
self.list=list
self.len = len(self.list)
self.cur_pos = -1
def __iter__(self):
return self
def next(self):
self.cur_pos += 1
if self.cur_pos<self.len:
return self.list[self.cur_pos]
else:
raise StopIteration()
class iter_reverse(object):
def __init__(self,list):
self.list=list
self.len = len(self.list)
self.cur_pos = self.len
def __iter__(self):
return self
def next(self):
self.cur_pos -= 1
if self.cur_pos>=0:
return self.list[self.cur_pos]
else:
raise StopIteration()
for e in iter_standard(list):
print e
for e in iter_reverse(list):
print e
可以看到我们只要调用相应名字的迭代器对象就可以直接进行for循环了,这种写法相比起每次都需要在for循环中重复一遍算法逻辑要简单,除此之外你还可以为不同输入类型定制相同的迭代方式,这样就无需关注内部实现了。这就是迭代器的作用,为不同类型的输入封装相同的迭代功能,从而实现代码简化。Python中有一个非常有用的itertools module,提供了大量不同的迭代器,只要直接调用你就可以实现对序列的各种操作,你可以通过这个库加深对于迭代器的理解。
示例三:(Python2环境)
# 在github项目pymysqlreplication里发现,作者并未为class BinLogStreamReader专门写__next__方法,而是在__iter__里直接返回一个迭代器对象,这个迭代器对象是使用iter()方法调用self.fetchone生成的,代码如下:
# module binlogstream部分代码如下:
"""
class BinLogStreamReader(object):
......
def fetchone(self):
while True:
... # 各种参数赋值和终止条件定义
binlog_event = ...
if binlog_event.event_type ...
...
return binlog_event.event
......
def __iter__(self):
return iter(self.fetchone, None)
"""
# fetchone是class BinLogStreamReader的一个方法,使用while循环根据不同的条件进行判断,返回event序列,这个可迭代的序列使用iter()处理后就是一个迭代器了,因此直接在__iter__中返回后就取代了__next__的作用。
# 因为不含__next__方法因此使用isinstance()判断BinLogStreamReader是否为迭代器时就会出错,虽然结果显示不是迭代器,但其实确实是迭代器...
# 我们改写下示例二中的class iter_standard来验证这个错误:
#-*- coding: utf-8 -*-
from collections import Iterator,Iterable
list=['a','b','c','d','e','f','g','h','i','j']
class iter_standard(object):
def __init__(self,list):
self.list=list
def __iter__(self):
return iter(self.list)
print isinstance(iter_standard(list),Iterable),isinstance(iter_standard(list),Iterator)
# 结果如下图,isinstance并不认为iter_standard类是一个迭代器。
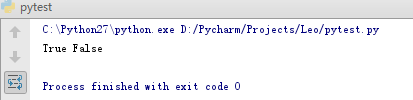
因此这里可以对iterable对象做一个有别于文章开头的解释,非iterator的iterable对象其标志不仅仅是含有__iter__方法,他的__iter__方法还返回了一个迭代器对象(例如示例三中的iter(self.list)),但因为其本身不含__next__方法所以其可for循环但并不是iterator。
补充:
日常工作中使用generator处理大文件是比较常见的场景,因为可以不用一次性读取整个文件,使用generator也可以极大的减少代码量。
这里贴一个某次使用generator进行基于mysql binlog恢复的脚本,使用此脚本读取一个300多G的flashback sql文件,占用极小的内存完成了恢复:
#!/usr/bin/python3.6.5/bin/python3.6
# coding=utf-8
import pymysql
import sys
import os
import time file = sys.argv[1]
mysql_conn = pymysql.connect(host = "xxx" , port = 3306 , user = "leo" , passwd = "xxx" , db = "xxx",charset='utf8') def get_sql_batch(open_file,batch_size,file_size):
cur_pos=0
open_file.seek(0 , os.SEEK_SET)
while cur_pos<file_size:
sql_batch=[]
for i in range(batch_size):
sql_line = open_file.readline()
if 'xxx' in sql_line:
sql_batch.append(sql_line)
cur_pos=f.tell()
yield sql_batch,cur_pos f=open(file)
f.seek(0 , os.SEEK_END)
filesize = f.tell()
f.seek(0 , os.SEEK_SET)
with mysql_conn.cursor() as cur:
for batch,pos in get_sql_batch(f,1000,filesize):
for sql in batch:
cur.execute(sql)
mysql_conn.commit()
print('%s: Current pos: %s,Current percent: %.2f%%'%(time.ctime(),pos,pos*100/filesize))
f.close()
最新文章
- matlab jet color mapping C / C++ / VC 实现
- bs4_3select()
- the XMLHttpRequest Object
- javaEE开发案例——购物车
- Eclipse 中Alt+/快捷键失效的解决办法。
- Demo学习: DownloadDemo
- SQL技巧之分类汇总
- ZOJ 1733 Common Subsequence(LCS)
- Android中关于List与Json转化问题
- WITH AS 优化逻辑读
- Java中json工具对比分析
- [Design Pattern] Mediator Pattern 简单案例
- opencv for python
- Please read “Security” section of the manual to find out how to run mysqld as root!错误解决(转)
- alex python of day1
- 调试bootmgr&winload vista&win7 x86&x64
- Python开发
- a message box to confirm the action
- PHP: PCRE 函数- Manual
- mac上配置php开发环境