Linux块设备IO子系统(二) _页高速缓存
磁盘驱动就是实现磁盘空间和内存空间数据上的交互,在上一篇中我们讨论了内存端的Page Segment Block Sector相关的概念,本文以3.14内核为例,讨论这部分内存是如何被组织管理的。我们知道,为了解决CPU和内存的速度不匹配,计算机系统引入了Cache缓存机制,这种硬件Cache的速度接近CPU内部寄存器的速度,可以提高系统效率,同样的思路也适用于解决内存和磁盘的速度不匹配问题,此外,磁盘多是机械式的,从寿命的角度考虑也不适合频繁读写,所以内核就将一部分内存作为缓存,提高磁盘访问速度的同时延长磁盘寿命,这种缓存就是磁盘高速缓存。包括页高速缓存(Page Cache,对完整数据页进行操作的磁盘高速缓存) + 目录项高速缓存(Dentry Cache,描述文件系统路径名的目录项对象) + 索引节点高速缓存(Buffer Cache,存放的是描述磁盘索引节点的索引节点对象),本文主要讨论页高速缓存,有了页高速缓存,内核的代码和数据结构不必从磁盘读,也不必写入磁盘。页高速缓存可以看作特定文件系统层的一部分。
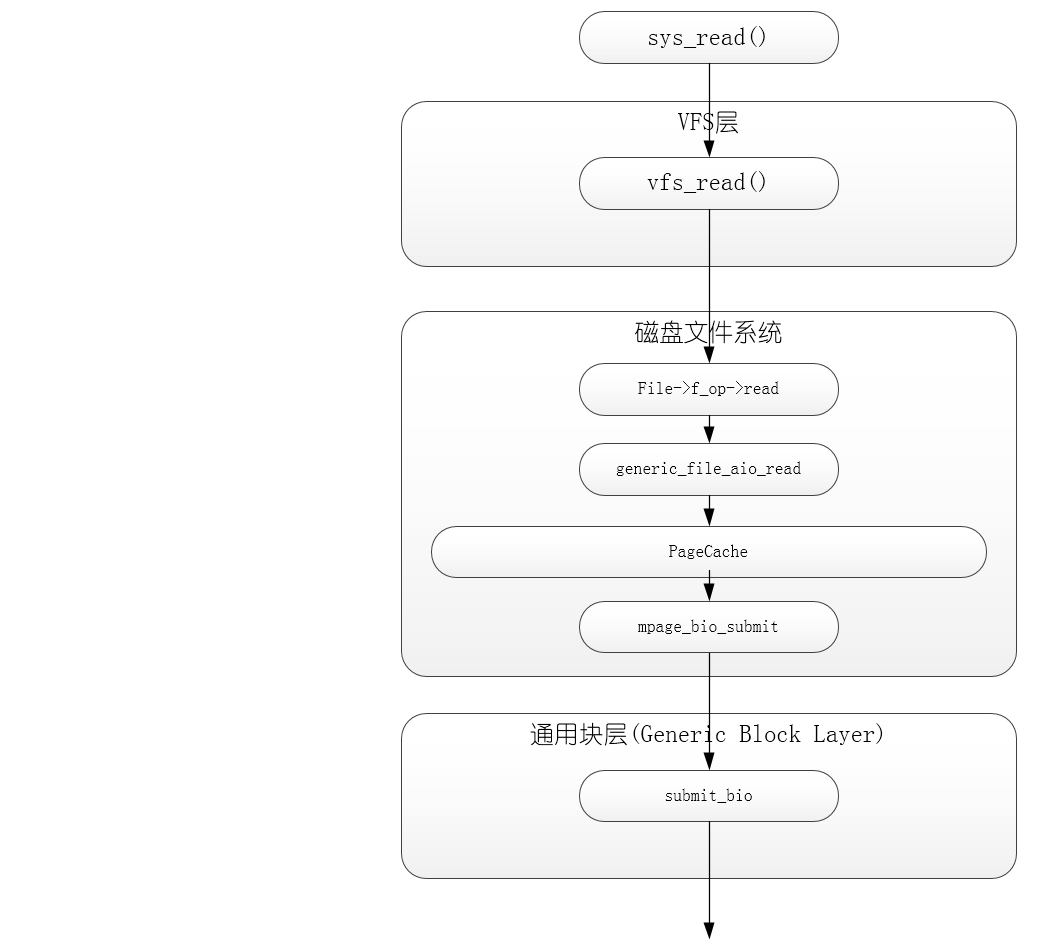
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
└── vfs_read(f.file, buf, count, &pos);
└──file->f_op->read(file, buf, count, pos);
└──do_sync_read(file, buf, count, pos);
└──filp->f_op->aio_read(&kiocb, &iov, 1, kiocb.ki_pos);
├──generic_file_aio_read(struct kiocb *iocb, const struct iovec *iov, unsigned long nr_segs, loff_t pos)
└──filemap_write_and_wait_range(mapping, pos, pos + iov_length(iov, nr_segs) - 1);
-----------------------------------Page Cache----------------------------------------------------
int mpage_readpage(struct page *page, get_block_t get_block)
└──wait_on_sync_kiocb(&kiocb);
├──do_mpage_readpage(bio, page, 1, &last_block_in_bio, &map_bh, &first_logical_block, get_block);
└──mpage_bio_submit(READ, bio);
└──submit_bio(rw, bio);
绝大多数情况下,内核在读写磁盘时都引用页高速缓存。新页被追加到页高速缓存以满足用户态进程的读请求。如果页不再高速缓存中,新页就被加到高速缓存中,然后用从磁盘读出的数据填充它,如果内存有足够的空闲空间,就让该页在高速缓存中长期保留,使其他进程再使用该页时不再访问磁盘。
同样,在把一页数据写到块设备之前,内核首先检查对应的页是否已经在高速缓存中,如果不在,就要先在其中增加一个新项,并用要写到磁盘中的数据填充该项。IO数据的传送不是马上开始,而是延迟几秒才对磁盘进行更新,从而使进程有机会队要写入磁盘的数据做进一步的修改。
页高速缓存肯可能是下面几种之一:
- 含有普通文件数据的页(上篇中的一个Page)
- 含有目录的页
- 含有直接从块设备文件(跳过文件系统)读出的数据的页。
- 含有用户态进程数据的页
- 属于特殊文件系统文件的页,如shm
从inode到page
既然是建立一块磁盘空间和一块内存空间之间的关系,那么就要通过相关的结构表示这种关系,在磁盘端,存储空间本质上都是属于一个文件,Linux中用inode结构表示一个文件,内存端,Linux内核用address_space来组织一组内存页,所以,我们可以在inode结构中找到相应的address_space对象域,而这个文件就成为该页的所有者(owner)。简单的追一下代码,我们可以画出下面这张关系图,本节主要围绕这张图讨论
inode
inode是内核中描述一个文件的结构,更多关于inode的讨论,可以参考Linux设备文件三大结构:inode,file,file_operations,本文中我们主要关心i_mapping和i_data两个成员。
//3.14/include/linux/fs.h
527 struct inode {
541 struct address_space *i_mapping;
594 struct address_space i_data;
616 };
struct inode
--541-->指向这个inode拥有的address_space对象
--594-->这个inode拥有的address_space对象
address_space
页高速缓存的核心结构就address_space对象,他是一个嵌入在页所有者的索引节点对象中的数据结构。高速缓存中的许多页都可能属于一个所有者,从而可能被链接到同一个address_space对象。该对象还在所有者的页和对这些页的操作之间建立起链接关系。
412 struct address_space {
413 struct inode *host; /* owner: inode, block_device */
414 struct radix_tree_root page_tree; /* radix tree of all pages */
415 spinlock_t tree_lock; /* and lock protecting it */
416 unsigned int i_mmap_writable;/* count VM_SHARED mappings */
417 struct rb_root i_mmap; /* tree of private and shared mappings */
418 struct list_head i_mmap_nonlinear;/*list VM_NONLINEAR mappings */
419 struct mutex i_mmap_mutex; /* protect tree, count, list */
420 /* Protected by tree_lock together with the radix tree */
421 unsigned long nrpages; /* number of total pages */
422 pgoff_t writeback_index;/* writeback starts here */
423 const struct address_space_operations *a_ops; /* methods */
424 unsigned long flags; /* error bits/gfp mask */
425 struct backing_dev_info *backing_dev_info; /* device readahead, etc */
426 spinlock_t private_lock; /* for use by the address_space */
427 struct list_head private_list; /* ditto */
428 void *private_data; /* ditto */
429 } __attribute__((aligned(sizeof(long))));
struct address_space
--413-->这个address_space对象所属的inode对象
--414-->这个address_space对象拥有的radix_tree_root对象
--425-->指向backing_dev_info对象,这个对象描述了所有者的数据所在的块设备,通常嵌入在块设备的请求队列描述符中。
radix_tree_root
描述一个radix树的根,内核使用这个数据结构快速的查找增删一个inode拥有的页高速缓存页
64 struct radix_tree_root {
65 unsigned int height;
66 gfp_t gfp_mask;
67 struct radix_tree_node __rcu *rnode;
68 };
50 struct radix_tree_node {
51 unsigned int height; /* Height from the bottom */
52 unsigned int count;
53 union {
54 struct radix_tree_node *parent; /* Used when ascending tree */
55 struct rcu_head rcu_head; /* Used when freeing node */
56 };
57 void __rcu *slots[RADIX_TREE_MAP_SIZE];
58 unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
59 };
struct radix_tree_node
--51-->当前树的深度,不包括叶子节点的层数
--52-->记录节点中非空指针数量的计数器
--57-->slot是包含64个指针的数组,每个元素可以指向其他节点(struct radix_tree_node)或者页描述符(struct page),上层节点指向其他节点,底层节点指向页描述符(叶子节点)
--58-->tag二维数组用于对radix_tree_node基树进行标记,下面就是一个页可能的标志
74 enum pageflags {
75 PG_locked, /* Page is locked. Don't touch. */
76 PG_error,
77 PG_referenced,
78 PG_uptodate,
79 PG_dirty,
80 PG_lru,
81 PG_active,
82 PG_slab,
83 PG_owner_priv_1, /* Owner use. If pagecache, fs may use*/
84 PG_arch_1,
85 PG_reserved,
86 PG_private, /* If pagecache, has fs-private data */
87 PG_private_2, /* If pagecache, has fs aux data */
88 PG_writeback, /* Page is under writeback */
93 PG_compound, /* A compound page */
95 PG_swapcache, /* Swap page: swp_entry_t in private */
96 PG_mappedtodisk, /* Has blocks allocated on-disk */
97 PG_reclaim, /* To be reclaimed asap */
98 PG_swapbacked, /* Page is backed by RAM/swap */
99 PG_unevictable, /* Page is "unevictable" */
112 __NR_PAGEFLAGS,
113
114 /* Filesystems */
115 PG_checked = PG_owner_priv_1,
116
117 /* Two page bits are conscripted by FS-Cache to maintain local caching
118 * state. These bits are set on pages belonging to the netfs's inodes
119 * when those inodes are being locally cached.
120 */
121 PG_fscache = PG_private_2, /* page backed by cache */
122
123 /* XEN */
124 PG_pinned = PG_owner_priv_1,
125 PG_savepinned = PG_dirty,
126
127 /* SLOB */
128 PG_slob_free = PG_private,
129 };
page
page就是内核中页描述符,通过radix树的操作,我们最终可以找到一组page,这组page归属于一个inode。我们可以看到其中的pgoff_t index成员,用来表示当前页在整组高速缓存页中的索引。至此,我们就通过一个文件的inode找到了它拥有的页高速缓存,接接下来就是使用块设备驱动实现相应的页缓存和磁盘的数据交互。
44 struct page {
48 union {
49 struct address_space *mapping; /* If low bit clear, points to
57 };
59 /* Second double word */
60 struct {
61 union {
62 pgoff_t index; /* Our offset within mapping. */
73 };
121 };
198 }
页高速缓存的基本操作是增删查更,在此基础上可以封装更高级的API
增加page
static inline int add_to_page_cache(struct page *page, struct address_space *mapping, pgoff_t offset, gfp_t gfp_mask)
删除page
void delete_from_page_cache(struct page *page)
查找page
struct page *find_get_page(struct address_space *mapping, pgoff_t offset)
unsigned find_get_pages(struct address_space *mapping, pgoff_t start,unsigned int nr_pages, struct page **pages)
//抢不到锁会阻塞
struct page *find_lock_page(struct address_space *mapping, pgoff_t offset)
//抢不到锁立即返回try???
//抢不到锁会阻塞,但是如果页不存在就创建新的
struct page *find_or_create_page(struct address_space *mapping,pgoff_t index, gfp_t gfp_mask)
更新page
truct page *read_cache_page(struct address_space *mapping,pgoff_t index,int (*filler)(void *, struct page *),void *data)
从page 到 block
block即是那个VFS或文件系统中的最小逻辑操作单位,一个页高速缓存可以由几个block构成,他们之间的关系如下:

buffer_head
每个块缓冲区都有相应的buffer_head对象描述,该描述符包含内核必须了解的,有关如何处理块的所有信息,
62 struct buffer_head {
63 unsigned long b_state; /* buffer state bitmap (see above) */
64 struct buffer_head *b_this_page;/* circular list of page's buffers */
65 struct page *b_page; /* the page this bh is mapped to */
66
67 sector_t b_blocknr; /* start block number */
68 size_t b_size; /* size of mapping */
69 char *b_data; /* pointer to data within the page */
70
71 struct block_device *b_bdev;
72 bh_end_io_t *b_end_io; /* I/O completion */
73 void *b_private; /* reserved for b_end_io */
74 struct list_head b_assoc_buffers; /* associated with another mapping */
75 struct address_space *b_assoc_map; /* mapping this buffer is
76 associated with */
77 atomic_t b_count; /* users using this buffer_head */
78 };
struct buffer_head
--63-->缓冲区状态标志
--64-->指向缓冲区的链表中的下一个元素的指针
--65-->指向拥有该块的缓冲区页的描述符的指针
--67-->块引用计数
--68-->块大小
--69-->表示块缓冲区在缓冲区页中的位置,实际上,这个位置的编号依赖于页是否在高端内存,如果在高端内存,则b_data字段存放的是块缓冲区相对于页的起始位置的偏移量,否则,b_data存放的是块缓冲区的线性地址
--71-->指向IO完成方法数据的指针
--72-->IO完成方法
--73-->指向IO完成方法数据的指针
--74-->为与某个索引节点相关的间接块的链表提供的指针
下面是b_state可能的取值
//include/linux/buffer_head.h
19 enum bh_state_bits {
20 BH_Uptodate, /* Contains valid data */
21 BH_Dirty, /* Is dirty */
22 BH_Lock, /* Is locked */
23 BH_Req, /* Has been submitted for I/O */
24 BH_Uptodate_Lock,/* Used by the first bh in a page, to serialise
25 * IO completion of other buffers in the page
26 */
27
28 BH_Mapped, /* Has a disk mapping */
29 BH_New, /* Disk mapping was newly created by get_block */
30 BH_Async_Read, /* Is under end_buffer_async_read I/O */
31 BH_Async_Write, /* Is under end_buffer_async_write I/O */
32 BH_Delay, /* Buffer is not yet allocated on disk */
33 BH_Boundary, /* Block is followed by a discontiguity */
34 BH_Write_EIO, /* I/O error on write */
35 BH_Unwritten, /* Buffer is allocated on disk but not written */
36 BH_Quiet, /* Buffer Error Prinks to be quiet */
37 BH_Meta, /* Buffer contains metadata */
38 BH_Prio, /* Buffer should be submitted with REQ_PRIO */
39 BH_Defer_Completion, /* Defer AIO completion to workqueue */
40
41 BH_PrivateStart,/* not a state bit, but the first bit available
42 * for private allocation by other entities
43 */
44 };
增
将块设备缓冲区所在的页添加到页高速缓存中
static int grow_buffers(struct block_device *bdev, sector_t block, int size)
删
将块设备缓冲区所在的页从页高速缓存中剔除
int try_to_free_buffers(struct page *page)
int try_to_release_page(struct page *page, gfp_t gfp_mask)
查
在页高速缓存中搜索块
当内核需要读写一个单独的物理设备块时(例如一个超级块),必须检查所有请求的块,缓冲区是否已经在页高速缓存中。在页高速缓存中搜索执行的块缓冲区(由块设备描述符的地址bdev和逻辑块号nr表示)的过程可以分成3个步骤
- 获取一个指针,让它指向包含指定的块设备的address_space对象(bdev->bd_inode->imapping)
- 获取块设备的大小(bdev->bd_block_size),并计算包含指定块的页索引。这需要在逻辑块号上进行移位操作,eg,如果块的大小是1024字节,每个缓冲区页包含4个块缓冲区,那么页的索引是nr/4
- 在块设备的基树中搜索缓冲区页,获得页描述符后,内核访问缓冲区首部,它描述了页中块缓冲区的状态
__find_get_block(struct block_device *bdev, sector_t block, unsigned size)
__getblk(struct block_device *bdev, sector_t block, unsigned size)
__bread(struct block_device *bdev, sector_t block, unsigned size)
交
块缓冲区最终要提交到通用块层进行IO操作,相关的API如下
int submit_bh(int rw, struct buffer_head *bh)
void ll_rw_block(int rw, int nr, struct buffer_head *bhs[])
脏页回写
在脏页回写机制中,首先,内核使用一个backing_dev_info对象来描述一个bdi设备,即backing device info——非易失存储设备,这些backing_dev_info都会挂接到bdi_list链表中,我们可以从其注册函数bdi_register()中看出。由于bdi的低速,所以也就有了本文讨论的页缓冲机制以及脏页回写问题,当一个高速缓存页被修改时,内核就会将相应的page对象中的相应的tag置为PG_dirty,即"脏页",脏页需要在合适的时候回写到磁盘对于脏页回写,2.6.2x/3x以前的内核通过动态的创建/删除pdflush线程来实现脏页回写,但是2.6.2x/3x之后的内核对这个方面进行的改进,采用writeback机制进行回写,writeback机制需要的核心结构和方法的关系如下。

可以看出,一个逻辑磁盘--一个gendisk对象--一个request_queue对象--一个backing_dev_info对象,这个backing_dev_info对象就是脏页回写的核心结构
64 struct backing_dev_info {
65 struct list_head bdi_list;
97 struct bdi_writeback wb; /* default writeback info for this bdi */
100 struct list_head work_list;
102 struct device *dev;
110 };
struct backing_dev_info
--65-->将所有的backing_dev_info链接起来的链表节点
--97-->bdi_writeback对象,使用延迟工作进行脏页回写
--100-->这个bdi设备中等待被处理的页的描述
--102-->表示这是一个device
37 /*
38 * Passed into wb_writeback(), essentially a subset of writeback_control
39 */
40 struct wb_writeback_work {
41 long nr_pages;
42 struct super_block *sb;
43 unsigned long *older_than_this;
44 enum writeback_sync_modes sync_mode;
45 unsigned int tagged_writepages:1;
46 unsigned int for_kupdate:1;
47 unsigned int range_cyclic:1;
48 unsigned int for_background:1;
49 unsigned int for_sync:1; /* sync(2) WB_SYNC_ALL writeback */
50 enum wb_reason reason; /* why was writeback initiated? */
51
52 struct list_head list; /* pending work list */
53 struct completion *done; /* set if the caller waits */
54 };
51 struct bdi_writeback {
52 struct backing_dev_info *bdi; /* our parent bdi */
53 unsigned int nr;
54
55 unsigned long last_old_flush; /* last old data flush */
56
57 struct delayed_work dwork; /* work item used for writeback */
58 struct list_head b_dirty; /* dirty inodes */
59 struct list_head b_io; /* parked for writeback */
60 struct list_head b_more_io; /* parked for more writeback */
61 spinlock_t list_lock; /* protects the b_* lists */
62 };
struct bdi_writeback
--57-->延迟工作对象,最终会调用下面的函数处理脏页
778 /*
779 * Explicit flushing or periodic writeback of "old" data.
780 *
781 * Define "old": the first time one of an inode's pages is dirtied, we mark the
782 * dirtying-time in the inode's address_space. So this periodic writeback code
783 * just walks the superblock inode list, writing back any inodes which are
784 * older than a specific point in time.
785 *
786 * Try to run once per dirty_writeback_interval. But if a writeback event
787 * takes longer than a dirty_writeback_interval interval, then leave a
788 * one-second gap.
789 *
790 * older_than_this takes precedence over nr_to_write. So we'll only write back
791 * all dirty pages if they are all attached to "old" mappings.
792 */
793 static long wb_writeback(struct bdi_writeback *wb,
794 struct wb_writeback_work *work)
最新文章
- CSS调试小技巧 —— 调试DOM元素hover,focus,actived的样式
- AC日记——校门外的树 洛谷 P1047
- Android程序进行混淆,在导出签名apk包时出错!
- [python IDE] 舒服的pycharm设置
- Django model 中meta options之 abstract
- 利用jQuery.validate异步验证用户名是否存在
- Safari浏览器Session问题
- Number and String in JS
- 10 Comparisons with adjectvies and nouns
- MapRedcue的demo(协同过滤)
- 初始化 CSS 样式
- ORM操作 数据库外键 一对多
- Python threading中lock的使用
- IP子系统集成
- Oracle EBS INV 更新物料慢
- Windows版Jenkins+SVN+Maven自动化部署环境搭建【转】
- python之路----包
- tomcat源码阅读之生命周期(LifeCycle)
- sorted()&enumerate()
- Spring笔记一