CUDA学习ing..
2024-08-22 12:41:59
0.引言
本文记载了CUDA的学习过程~刚开始接触GPU相关的东西,包括图形、计算、并行处理模式等,先从概念性的东西入手,然后结合实践开始学习。CUDA感觉没有一种权威性的书籍,开发工具变动也比较快,所以总感觉心里不是很踏实。所以本文就是从初学者的角度,从无知开始探索的过程。当然在学习过程中避免不了出现概念性的理解错误,出现描述模糊不确切的地方还望指出,共勉共勉~
1.CUDA的概念
2.CUDA的模型
CUDA的运行模型,让host中的每个kernel按照线程网格的方式(Grid)在显卡硬件(GPU)上执行。每一个线程网格又包含多个线程块(block),每一个线程块又包含多个线程(Thread)。
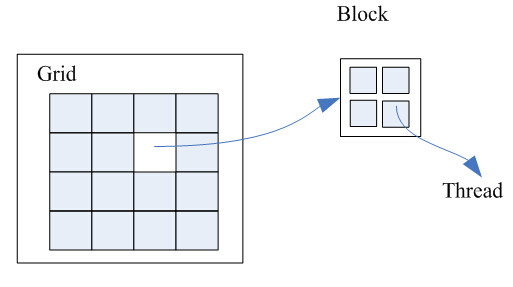
Thread是UCDA模型中最基本的运行单元,执行最基本的程序指令。每一组协作的Thread被归于一个Block。在Block内部允许共享存储,可以容纳Thread的上限是512个。Grid是一组Block,共享全局存储空间。每一个Grid对应着一个Kernel任务(GPU上执行的核心任务)。
Warp:GPU执行程序时(Multi-processor)调度单位,目前CUDA的Warp的大小为32,同在一个Warp线程,在相同的指令下执行不同的数据。由于Multi-processor的数量不同,所以一个Block内的所有Thread不一定全部同时运行,但是每个Warp内的所有Thread一定同时运行。因此,我们定义BlockSize的时候应该是Warp Size的整数倍,也就是BlockSize应该为32 的整数倍。理论上来说,Thread的数量越多,就越能弥补单个Thread读取数据的 latency,但是当Tread越多,每个Thread可用的寄存器数量也就越少,严重的时候甚至能造成Kernel无法启动。因此每个Block至少应该包含64个Thread,一般数目为128或者256,具体的数量依据Multi-processor的数目而定。一个Multi-processor最多可以同时运行768个Thread,但是每个Multi-processor最多包含8个Block,因此要保持100%利用率,Block与Size就应该保持下列设定:
2 blocks x 384 threads
3 blocks x 256 threads
4 blocks x 192 threads
6 blocks x 128 threads
8 blocks x 96 threads
最新文章
- Util应用程序框架公共操作类(九):Lambda表达式扩展
- DataWindow.Net 2.5 配置
- Dell vsotro 14 3000系列从win10重装win7
- KEIL4.12中添加ULINK2的支持
- tc令牌桶限速心得
- IOS 在功能 autorelease release
- ListView的局部刷新
- display的none与block(判断登录界面的账号密码是否为空)
- 在Java环境上运行redis
- NPOI导出excel(带图片)
- zTree多条件模糊查询
- 【java】System成员输入输出功能out、in、err
- .Net Core 学习笔记1——包、元包、框架
- 《mysql必知必会》学习_第17章_20180807_欢
- 11.webview、shareSDK
- 格雷码(Gray code)仿真
- log4j下载地址及日志文件输入位置配置
- pythonweb框架Flask学习笔记05-简单登陆
- 让网络编程更轻松和有趣 t-io
- BZOJ 4571 【SCOI2016】 美味