Python爬虫3-----浏览器伪装
2024-10-01 09:27:31
1、浏览器伪装技术原理
当爬取CSDN博客时,会发现返回403,因为对方服务器会对爬虫进行屏蔽,故需伪装成浏览器才能爬取。浏览器伪装一般通过报头进行。
2、获取网页的报头
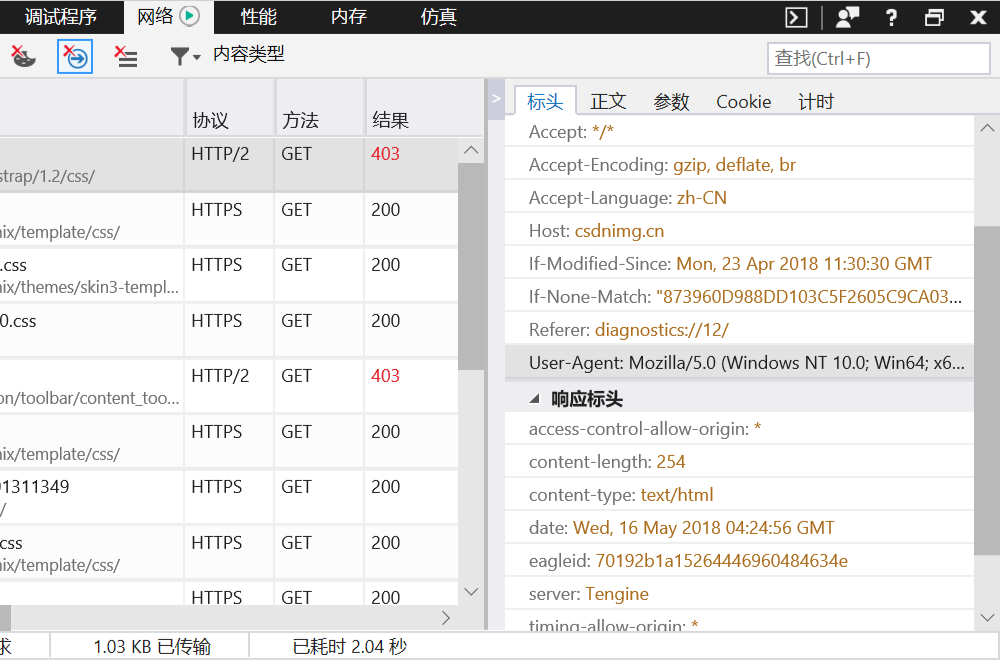
3、代码:
import urllib.request
url="https://blog.csdn.net/blogdevteam/article/details/80324831"
header=("User-Agent","https://blog.csdn.net/blogdevteam/article/details/80324831")
#build_opener可以添加报头信息
opener=urllib.request.build_opener()
#添加报头
opener.addheaders=[header]
data=opener.open(url).read()
'''
#如果用urlopen来打开网页获取数据,则采用install_opener函数
#urllib.request.install_opener(opener)
#data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
print(data)
最新文章
- Git 学习看这篇就够了!
- selenium 3.0 beta2 初体验
- 廖雪峰JavaScript学习摘录
- 试一下SVG
- 自己写ORM框架 SqlHelper_DG C#(java的写在链接里)
- java设计模式--原始模型模式
- Android - 多语言自动适配
- 201521123113《Java程序设计》第12周学习总结
- 嵌入式C快速翻转一个任何类型的数的二进制位
- name 'reload' is not defined解决方法
- java反射(java.lang.reflect) ---普通单例模式唯一性问题
- 给定一个只包含正整数的非空数组,返回该数组中重复次数最多的前N个数字 ,返回的结果按重复次数从多到少降序排列(N不存在取值非法的情况)
- qt 在窗口上画框
- 撩课-Java每天5道面试题第17天
- Kafka创建Topic时如何将分区放置到不同的Broker中
- vs2017连接mysql以及问题汇总
- android官方资料
- Laravel5.5 使用队列 Queue
- HTML meta标签总结,HTML5 head meta属性整理
- SQL2008数据库导出到SQL2000全部步骤过程