mysql续
接上篇博客,写完以后看了看,还是觉的写的太简单,就算是自己复习都不够,所以再补充一些
1.创建多表关联
需求:图书管理系统,创建几张表,包含书籍,出版社,作者,作者详细信息等内容
分析:
(1)图书只有一个出版社,出版社可以出版很多书,多对一关系
(2)图书可以有多个作者,一个作者也可以写多本书,多对多关系
(3)作者的详细信息表,与作者一对一关系
(4)多对一关系,用外键;一对一关系,在外键上加唯一约束;多对多关系,用第三张表存储关系
(5)需要建立五张表,书籍,出版社,作者,作者详细信息,图书与作者关系表
代码贴到这,用pycharm书写,推荐mysql命令大写
create database book_manage_system character set utf8; --创建出版社表,字段有id,name,city
create table publish(id int primary key auto_increment,
name varchar(20),
city varchar(20)); --创建书籍表,书籍表是出版社表的子表,字段有id,name,price,publish_id
create table book (id int primary key auto_increment,
name varchar(20),
price double(6,2),
publish_id int,
foreign key (publish_id) references publish(id)
--增加外键,与出版社表和作者表建立关系
); --创建作者详细信息表,字段有ID,name,age,city,phone_num,email
create table auth_detail (id int primary key auto_increment,
name varchar(20),
age int,
city varchar(20),
phone_num varchar(11),
email varchar(30)); --创建作者表,为作者详细信息表的子表,字段有ID,name,auth_detail_id
create table author(id int primary key auto_increment,
name varchar(20),
auth_detail_id int unique,
foreign key (auth_detail_id) references auth_detail(id)
--增加外键,与作者详细信息表建立联系,一对一关系,唯一性约束
); --创建作者与书籍的关系表,字段有auth_id,book_id
create table book_to_auth(id int primary key auto_increment,
auth_id int,
foreign key (auth_id) references author(id),
book_id int,
foreign key (book_id) references book(id));
--创建外键,作者信息与书籍信息联系
2.用pycharm来编写mysql语句
虽然mysql的命令我们都应该熟记于心,但是当我们已经记住后,从开发效率方面考虑,我们就可以使用一些文本编辑器来帮助我们写这些语句了,下面说一下配置pycharm的流程
(1)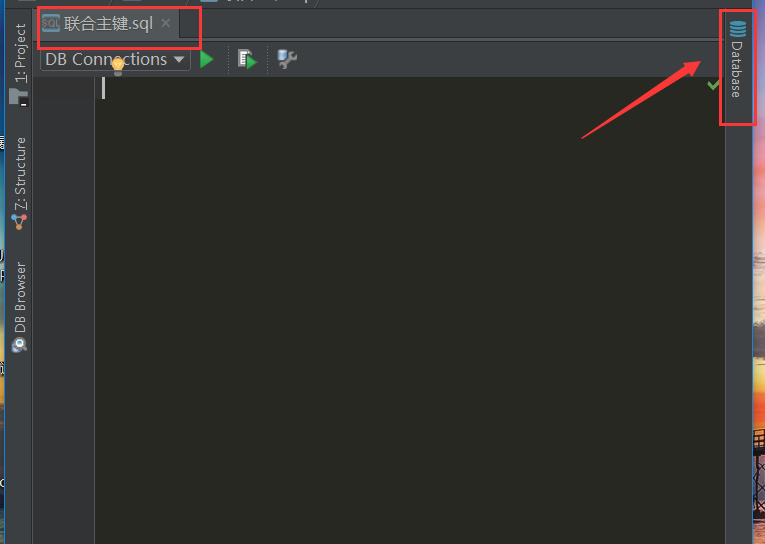 新建一个sql文件,打开pycharm右边的database
新建一个sql文件,打开pycharm右边的database
(2)
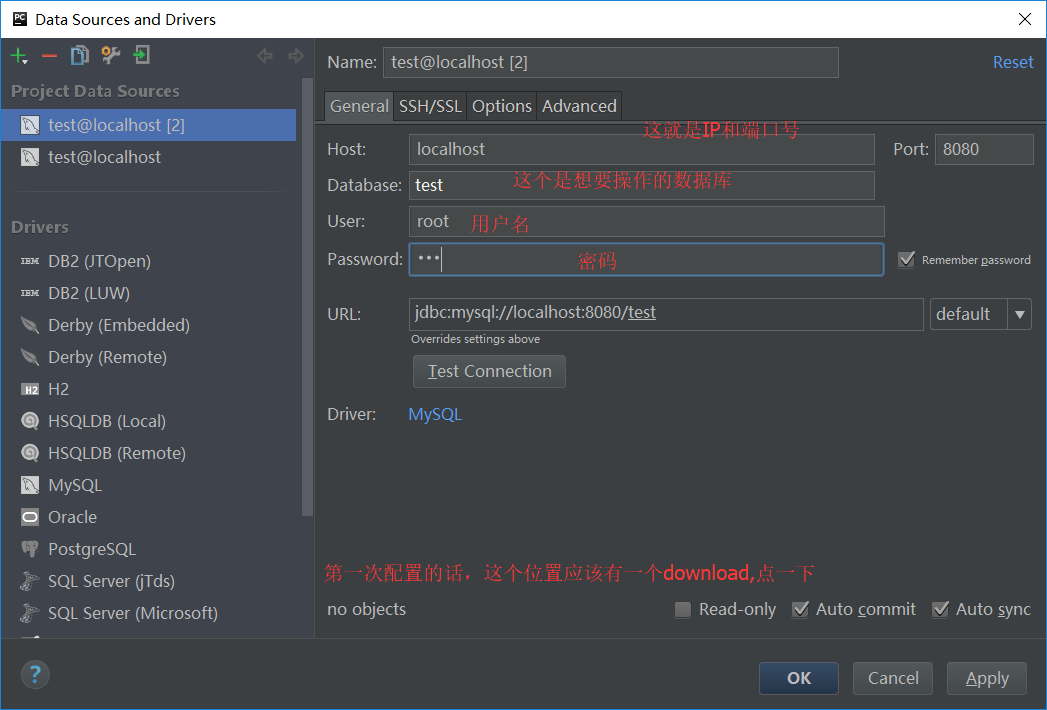
(3)
(4)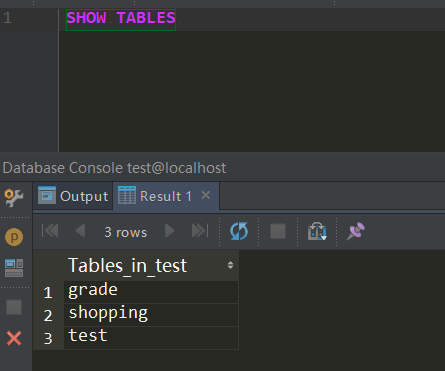
ok,这就可以了,妈妈再也不用担心我忘记大写了,效率也是提升了不知多少倍
但是需要注意,这只能操作一个数据库,想切换数据库的话,要重新走一遍刚才的流程,把想要操作的数据库添加进来就行了
3.联合主键
上一篇博客写了设置主键可以用primary key,也可以用not null unique
这里要详细说一下,
- 如果表中只有一个非空且唯一约束,自动就会识别为主键
- 非空且唯一约束并非只能设置一次,但是第一个设置这个约束的被识别为主键
- 每张表只能有一个主键,但是主键并不一定在一个字段上,即联合主键
CREATE TABLE union_primary_key (id int,
name VARCHAR(20),
age int,
PRIMARY KEY (id,name))
看一下表结构,

看到没,两个主键了,这就叫联合主键。
应用的话,可以参照我们最开始设计的那个图书管理系统,在我们创建图书和作者关系的表的时候,图书id和作者id理论上都应该是必须同时有值且不能重复,就可以把他俩设置成联合主键
4.存储引擎
不知你有没有注意过,当我们用create命令查看表的创建信息时,会得到类似这样一些数据
| book | CREATE TABLE `book` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`price` double(6,2) DEFAULT NULL,
`publish_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `publish_id` (`publish_id`),
CONSTRAINT `book_ibfk_1` FOREIGN KEY (`publish_id`) REFERENCES `publish` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
最下边有一个 ENGINE=InnoDB
这就是存储引擎,存储引擎的作用是存储数据,为数据建立索引,查询数据
在MySQL中提供了多种存储引擎,有innodb,memory,blackhole等
innodb是我们最常用的,memory是基于内存的存储机制,不会长久保存,而blackhole叫黑洞引擎,所有丢到里面的数据都会消失,我至今也没理解是干什么用的,据说是为了测试。而我们最关心 的应该是innodb。外键这个东西就是innodb独有的。
我们可以通过命令SHOW ENGINES查看引擎(tips:在命令提示行中是显示不全的,可以在命令后面加一个\G,就可以正常显示了)
以innodb 创建一个表之后,就会有分别以opt,frm,ibd为后缀的三个文件创建,不同的引擎,创建的文件也不一样
5.索引(index或key)
索引在mysql中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。当表中的数据量很大时,索引能轻易的将查询性能提高好几个数量级。虽然在创建索引时很费时间,但是一旦创建好,就能大大提高查询速度。
创建索引的方式:
(1)创建普通索引
CREATE TABLE student(
id INT,
name VARCHAR(20),
INDEX index_name(name)
);
(2)创建唯一索引
CREATE TABLE student(
id INT,
name VARCHAR(20),
UNIQUE INDEX index_name(name)
);
(3)创建全文索引
CREATE TABLE student(
id INT,
name VARCHAR(20),
FULLTEXT INDEX index_name(name)
);
(4)创建多列索引
CREATE TABLE student(
id INT,
name VARCHAR(20),
INDEX index_name(name,id)
);
(5)在已存在的表上创建索引
# 1.create方法
CREATE INDEX 索引名
ON 表名 (字段名 ) # 2.alter方法
ALTER TABLE 表名 ADD INDEX
索引名 (字段名)
删除索引:
DROP INDEX 索引名 on 表名
6.还有pymsql和orm,下次写数据库的时候一块说
最新文章
- 简单有效的kmp算法
- WinForm中MouseEnter和MouseLeave混乱的问题
- Yii 多个子目录同步登录
- 国内CDN公共库
- Java Hour 20 Spring
- Objective-C:Foundation框架-概述
- Java-J2SE学习笔记-线程-生产者消费者问题
- 【转】MyBatis学习总结(一)——MyBatis快速入门
- effective c++ 条款9 do not call virtual function in constructor or deconstructor
- 13.localStorage和sessionStorage的区别
- checkbox插件
- CodeForces 958F3 Lightsabers (hard) 启发式合并/分治 多项式 FFT
- C语言的split功能
- Strom
- JNUOJ 1032 - 食物处理器
- Spring Advisor
- linux文件管理之解压缩
- Easyui入门视频教程 第09集---登录完善 图标自定义
- 01_MUI之Boilerplate中:HTML5演示样例,动态组件,自己定义字体演示样例,自己定义字体演示样例,图标字体演示样例
- stm32 学习参考(转)