(数据科学学习手札78)基于geopandas的空间数据分析——基础可视化
本文对应代码和数据已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
通过前面的文章,我们已经对geopandas中的数据结构、坐标参考系以及文件IO有了较为深入的学习,在拿到一份矢量数据开始分析时,对其进行可视化无疑是探索了解数据阶段重要的步骤。
作为基于geopandas的空间数据分析系列文章的第四篇,通过本文你将会学习到基于geopandas的基础可视化。
2 基础可视化
geopandas使用matplotlib作为绘图后端,使用plot()方法对GeoSeries或GeoDataFrame进行可视化,简简单单即可完成基本的可视化,再结合上matplotlib的一些额外元素补充,便可以创建出更加精美的可视化作品,下面我们分别进行介绍。
2.1 GeoSeries
GeoSeries由于仅有单独一列几何对象,无对应的数值故不涉及数值向视觉元素的映射,因此可视化相对简单,下面我们先来看看GeoSeries.plot()的常用的参数有哪些,如果你已经对matplotlib有一定了解,想必理解这些参数起来会更加轻松:
figsize:传入(宽度, 高度)形式的元组或列表,用于控制绘制出图像的宽度和高度,单位均为英寸
facecolor:设置几何对象的填充色,可接受颜色名称和十六进制色彩,设置为'none'时不填充颜色
edgecolor:设置几何对象的边界色,对面数据和点数据效果较为明显,不建议对线数据设置该参数,传入格式同facecolor
linewidth:设置几何对象边界宽度,对面数据和点数据效果较为明显,不建议对线数据设置该参数
linestyle:字符串类型,用于设置几何对象边界及线数据的线型
markersize:设置点数据的大小
marker:字符串类型,用于设置点数据的形状
alpha:设置对应几何对象全局的色彩透明度,0-1,越大越不透明
label:适用于纯粹的线数据或点数据,在需要添加图例时适用,用作各个对象在图例中显示的名称
hatch:字符型,用于设置面数据内部的填充线样式下文的例子中将具体举例说明
ax:
matplotlib坐标轴对象,如果需要在同一个坐标轴内叠加多个图层就需要用这个参数传入先前待叠加的ax
下面我们从实际例子上手,深入理解上述各参数,我们使用到的数据china-shapefiles.zip为中国国土+南海九段线,你可以在本文开头列出的Github仓库对应本文的路径下找到它。
首先利用上一篇文章介绍的读取.zip文件中数据的方法,将我们所需的陆地及九段线数据分别读入(其中由于原始数据china.shp中每个要素不是单独的省份而是面,即有的包含众多岛屿的省份会由若干行共同构成,因此使用geopandas地理操作中的融合dissolve()按照OWNER列融合分离的面为多面,从而使得每一行是对应的完整的省份,关于更多地理操作将会在后续的对应的文章介绍):
import geopandas as gpd
import matplotlib.pyplot as plt
# 设置matplotlib绘图模式为嵌入式
%matplotlib inline
plt.rcParams["font.family"] = "SimHei" # 设置全局中文字体为黑体
# 读入中国领土面数据
china = gpd.read_file('zip://china-shapefiles.zip!china-shapefiles/china.shp',
encoding='utf-8')
# 由于每行数据是单独的面,因此按照其省份列OWNER融合
china = china.dissolve(by='OWNER').reset_index(drop=False)
# 读入南海九段线线数据
nine_lines = gpd.read_file('zip://china-shapefiles.zip!china-shapefiles/china_nine_dotted_line.shp',
encoding='utf-8')
用plot()方法叠加绘制不带任何个性化参数的原始地图(CRS为EPSG:4326即WGS84):
# 初始化图床
fig, ax = plt.subplots(figsize=(12, 8))
ax = china.geometry.plot(ax=ax)
ax = nine_lines.geometry.plot(ax=ax)
fig.savefig('图1.png', dpi=300)
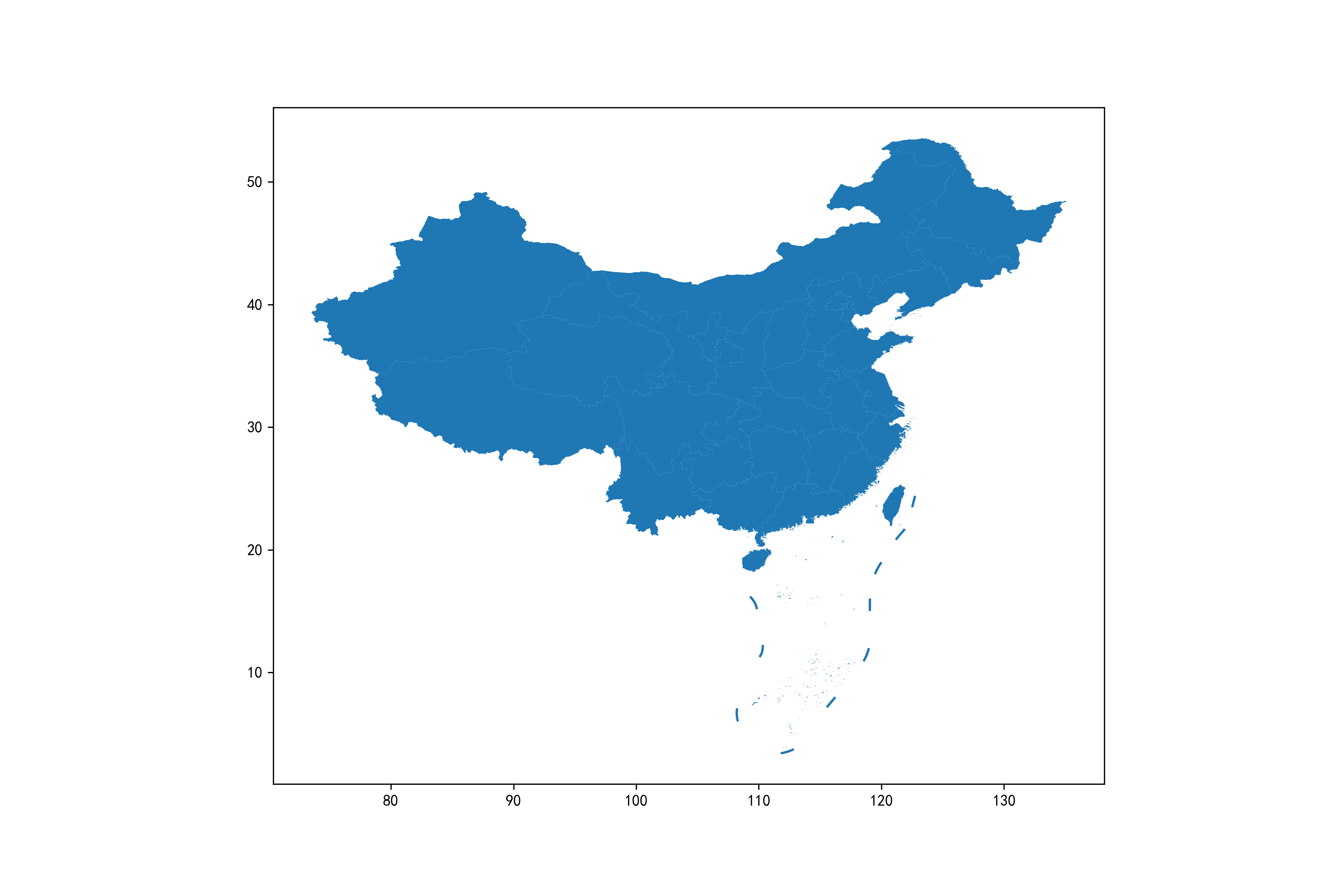 图1
图1
接下来我们一步一步,将适用于GeoSeries.plot()的参数展示运用:
- Step1:选择合适的投影
在之前关于坐标参考系的文章中我们了解过绘制地图时投影的重要性,参考超图对绘制中国地图投影选用方面的建议(http://support.supermap.com.cn/datawarehouse/webdochelp/idesktop/features/Visualization/MapSetting/ChooseAMapProjection.htm),我们使用绘制中国地图常用的Albers Equal Area作为投影,在https://proj.org/operations/projections/aea.html查询到其信息说明:
 图2
图2
将其proj信息传入to_crs()方法中(注意按照将添加上中央经线105度和标准纬度范围25到47度),统一到所有图层中:
# 定义CRS
albers_proj = '+proj=aea +lat_1=25 +lat_2=47 +lon_0=105'
fig, ax = plt.subplots(figsize=(12, 8))
ax = china.geometry.to_crs(albers_proj).plot(ax=ax)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax)
fig.savefig('图3.png', dpi=300)
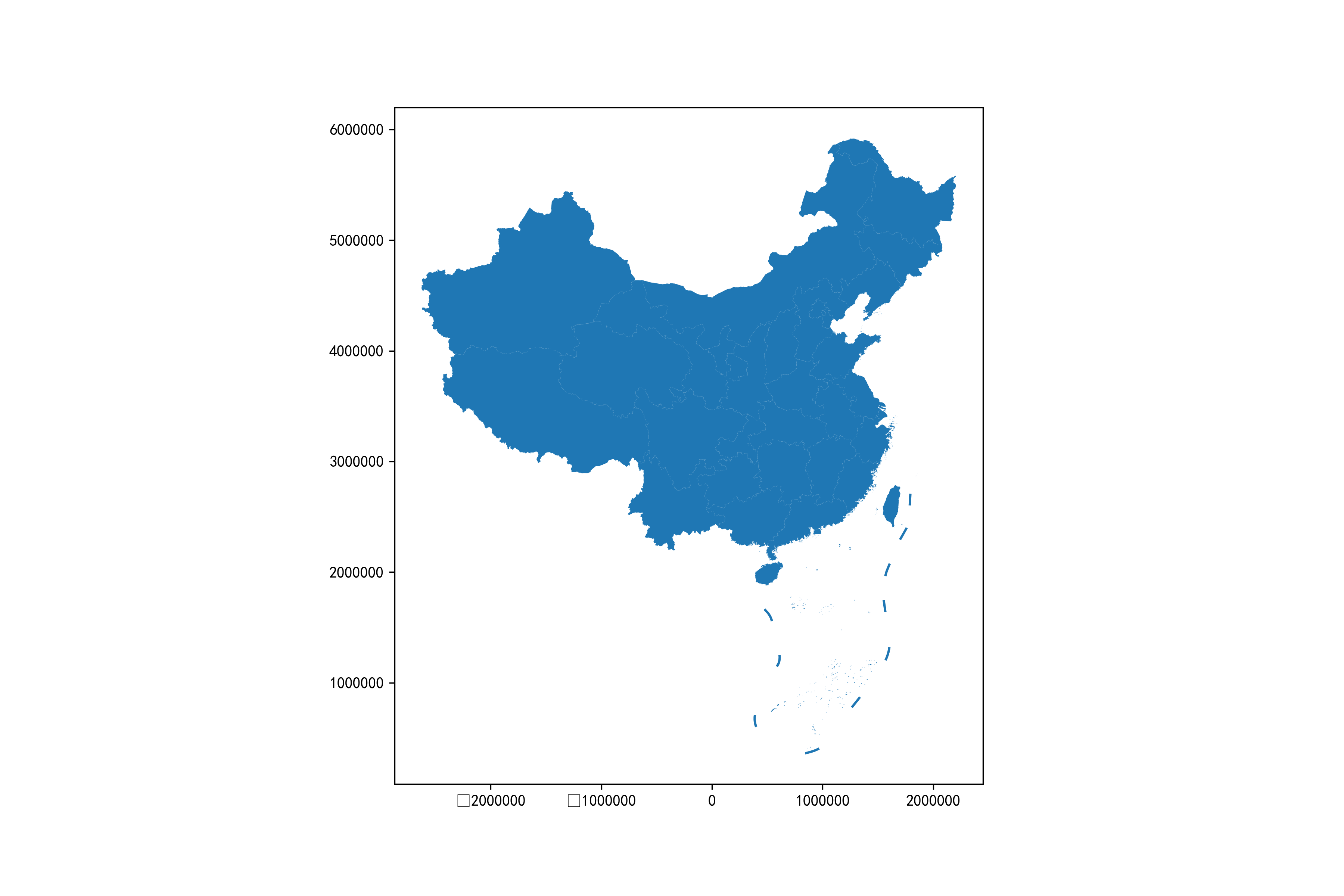 图3
图3
这时的形状较为接近真实情况,看起来也比较自然。
- Step2:修改颜色
下面我们来调整面数据的填充色与轮廓色,线数据(九段线)的色彩,并分别设置透明度alpha,这里为了美观,将坐标轴顺便移除:
fig, ax = plt.subplots(figsize=(12, 8))
ax = china.geometry.to_crs(albers_proj).plot(ax=ax,
facecolor='grey',
edgecolor='white',
alpha=0.8)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
alpha=0.4)
ax.axis('off') # 移除坐标轴
fig.savefig('图4.png', dpi=300)
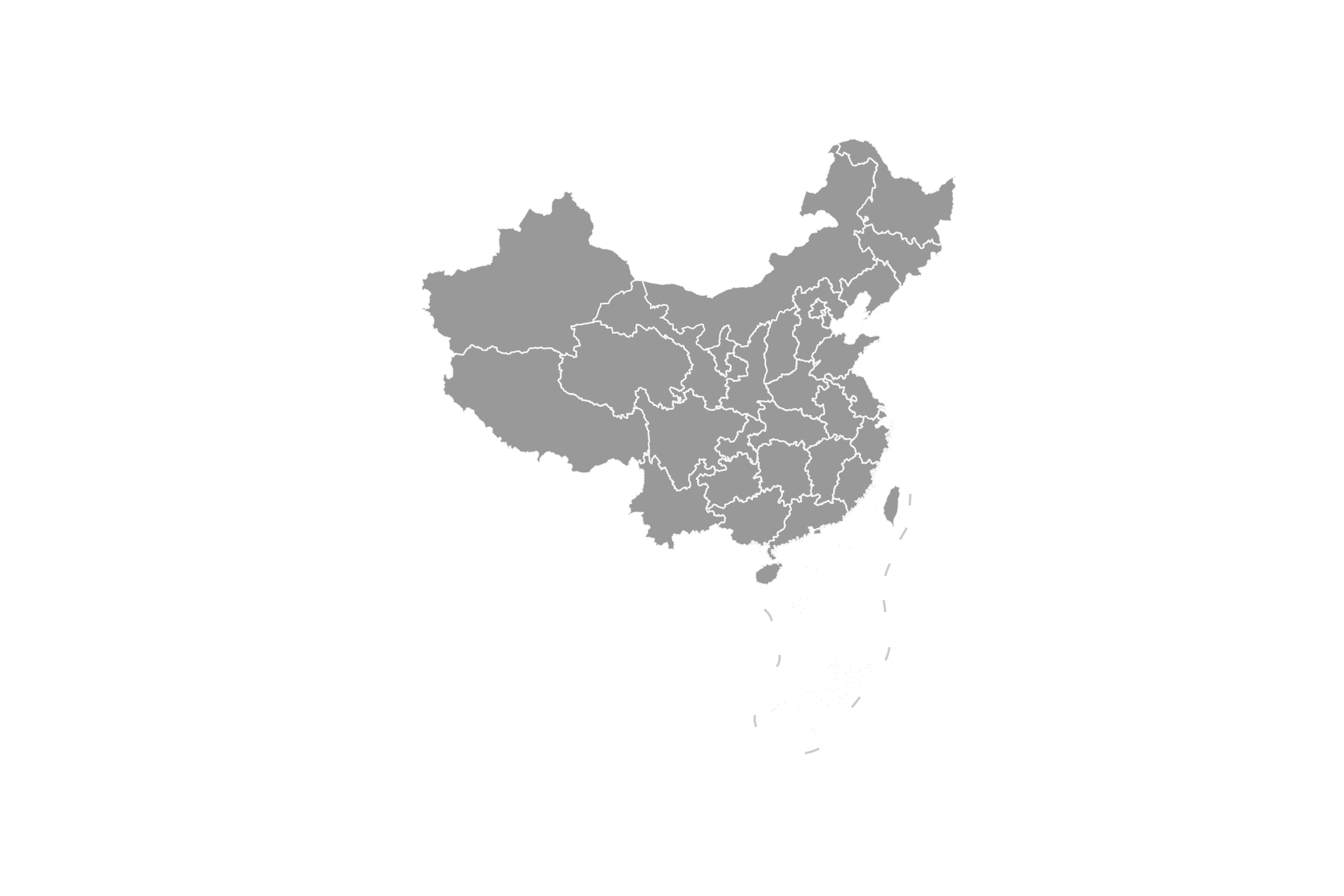 图4
图4
- Step3:修改线型与线宽
接下来我们在图4的基础上,修改线型和线宽,其中线型参数linestyle与matplotlib完全一致,不同选择对应样式如图5:
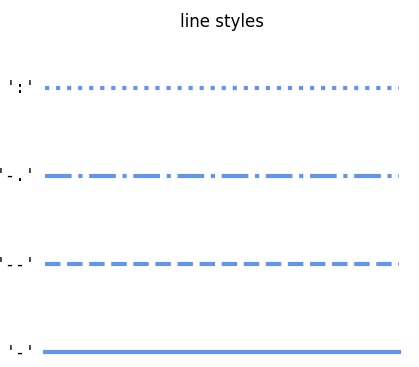 图5
图5
参考图5,我们维持九段线线型不变但适当增大其宽度为3,面数据的轮廓则设置为'--':
fig, ax = plt.subplots(figsize=(12, 8))
ax = china.geometry.to_crs(albers_proj).plot(ax=ax,
facecolor='grey',
edgecolor='white',
linestyle='--',
alpha=0.8)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax.axis('off') # 移除坐标轴
fig.savefig('图6.png', dpi=300)
 图6
图6
- Step4:修改面填充阴影线样式
接下来我们利用hatch参数来修改面数据填充阴影样式,主要样式对应如下,如'-'代表横线填充:
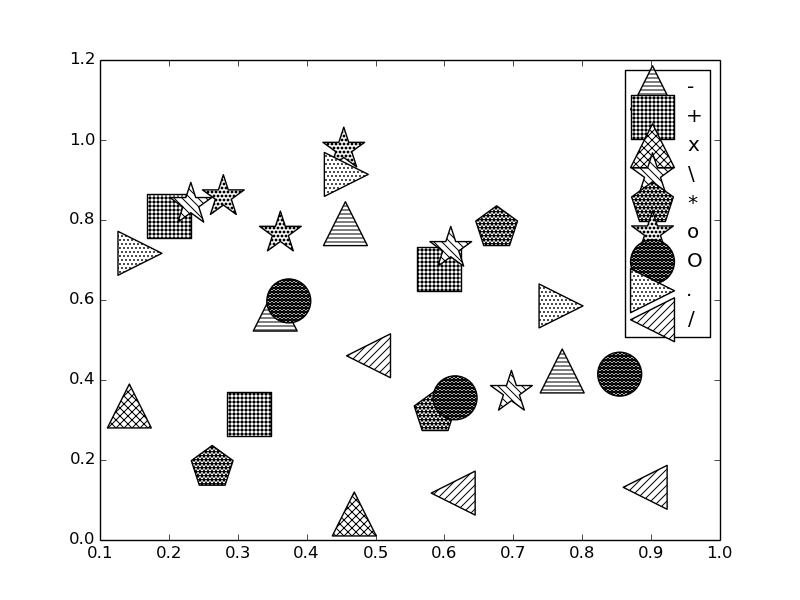 图7
图7
参考图7,我们设置面数据的填充阴影样式为'x',值得一提的是,hatch参数对于同一种阴影模式,可以通过增加字符数量来提高阴影密度,如下图是hatch='x'时:
fig, ax = plt.subplots(figsize=(12, 8))
ax = china.geometry.to_crs(albers_proj).plot(ax=ax,
facecolor='grey',
edgecolor='white',
linestyle='--',
hatch='x',
alpha=0.8)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax.axis('off') # 移除坐标轴
fig.savefig('图8.png', dpi=300)
 图8
图8
而hatch='xxxx'时绘制出的地图如下:
 图9
图9
更有意思的是,不同阴影模式可以混合在一起,譬如我们下面设置hatch='x**':
fig, ax = plt.subplots(figsize=(12, 8))
ax = china.geometry.to_crs(albers_proj).plot(ax=ax,
facecolor='grey',
edgecolor='white',
linestyle='--',
hatch='x**',
alpha=0.8)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax.axis('off') # 移除坐标轴
fig.savefig('图10.png', dpi=300)
 图10
图10
- Step5:点数据个性化
GeoSeries.plot()中的markersize和marker专门针对点数据进行配置,可是我们的数据里并没有点数据,为了举例说明,下面我们来从已有的数据中生成点数据,我最开始的想法是为每个面生成重心,作为每个省份的中心点:
fig, ax = plt.subplots(figsize=(12, 8))
ax = china.geometry.to_crs(albers_proj).plot(ax=ax,
facecolor='grey',
edgecolor='white',
linestyle='--',
hatch='xxxx',
alpha=0.8)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax = china.geometry.centroid.to_crs(albers_proj).plot(ax=ax,
facecolor='black')
ax.axis('off') # 移除坐标轴
fig.savefig('图11.png', dpi=300)
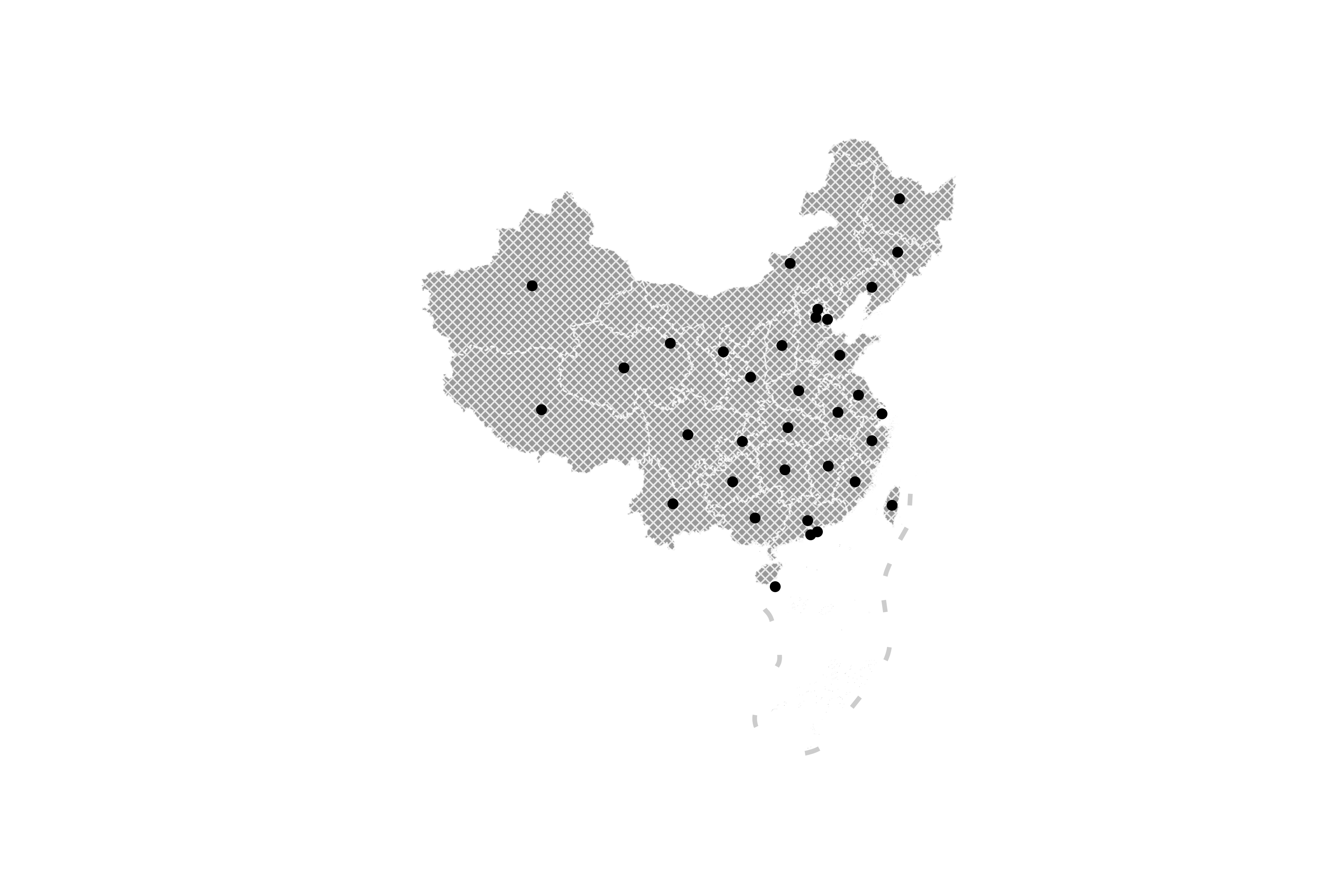 图11
图11
但是细心观察可以发现,有些省份的重心很尴尬地落在外面,譬如甘肃省,因为它是一个非常典型的非凸多边形(凸多边形内部任意两点间连线都不会穿过其边界),因此计算出来的重心落在了外部,好在geopandas为我们提供了representative_point()方法,用于求出任意多边形内部的一个典型点:
fig, ax = plt.subplots(figsize=(12, 8))
ax = china.geometry.to_crs(albers_proj).plot(ax=ax,
facecolor='grey',
edgecolor='white',
linestyle='--',
hatch='xxxx',
alpha=0.8)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax = china.geometry.representative_point() \
.to_crs(albers_proj) \
.plot(ax=ax,
facecolor='black')
ax.axis('off') # 移除坐标轴
fig.savefig('图12.png', dpi=300)
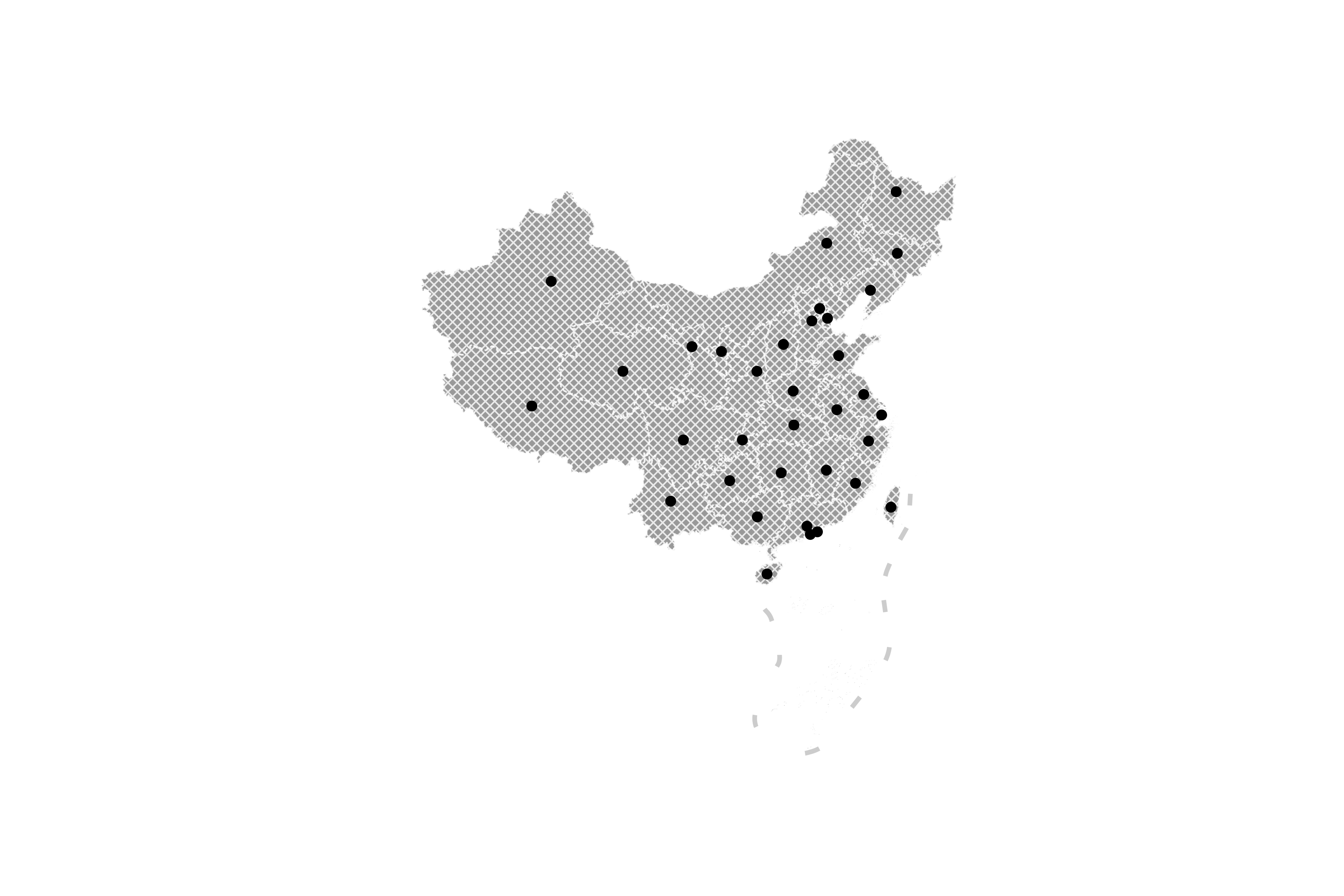 图12
图12
这时可以发现生成的点符合了我们的需求,下面我们为此基础上,利用marker调整点数据的样式,参考图13:
 图13
图13
譬如我们将marker修改为'*',并调整相关的其他参数使得点看起来更加明显:
fig, ax = plt.subplots(figsize=(12, 8))
ax = china.geometry.to_crs(albers_proj).plot(ax=ax,
facecolor='grey',
edgecolor='white',
linestyle='--',
hatch='xxxx',
alpha=0.8)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax = china.geometry.representative_point() \
.to_crs(albers_proj) \
.plot(ax=ax,
facecolor='white',
edgecolor='black',
marker='*',
markersize=200,
linewidth=0.5)
ax.axis('off') # 移除坐标轴
fig.savefig('图14.png', dpi=300)
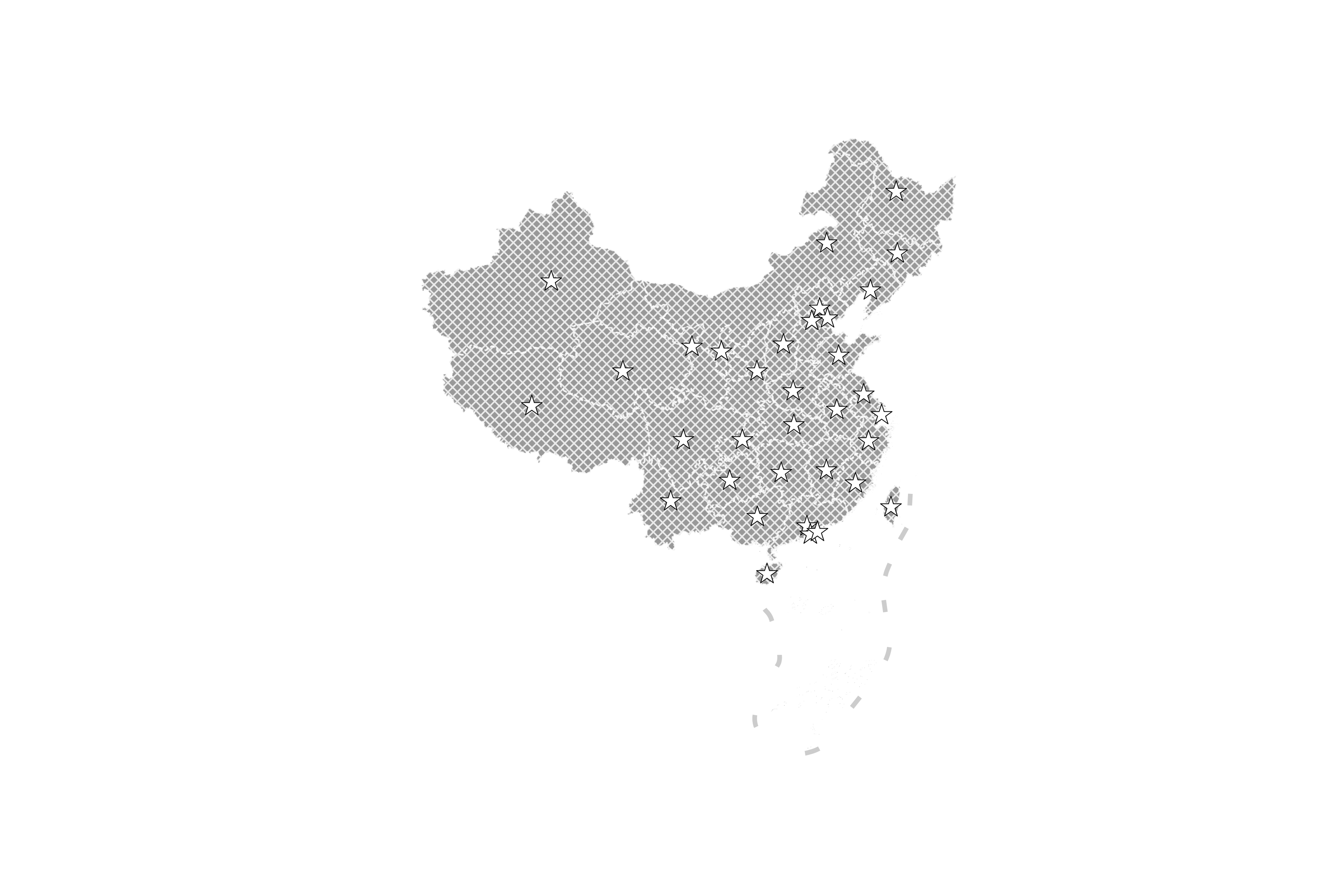 图14
图14
- Step6:图例与文字标注
接下来我们来学习如何为地图添加图例和文字标注,为了看着清楚我们移除阴影填充并降低点的大小,然后为九段线与点数据添加参数label,最后使用ax.legend()添加图例并设置相应参数:
fig, ax = plt.subplots(figsize=(12, 8))
ax = china.geometry.to_crs(albers_proj).plot(ax=ax,
facecolor='grey',
edgecolor='white',
linestyle='--',
alpha=0.8)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4,
label='南海九段线')
ax = china.geometry.representative_point() \
.to_crs(albers_proj) \
.plot(ax=ax,
facecolor='white',
edgecolor='black',
marker='*',
markersize=100,
linewidth=0.5,
label='省级单位')
# 单独提前设置图例标题大小
plt.rcParams['legend.title_fontsize'] = 14
# 设置图例标题,位置,排列方式,是否带有阴影
ax.legend(title="图例", loc='lower left', ncol=1, shadow=True)
ax.axis('off') # 移除坐标轴
fig.savefig('图15.png', dpi=300)
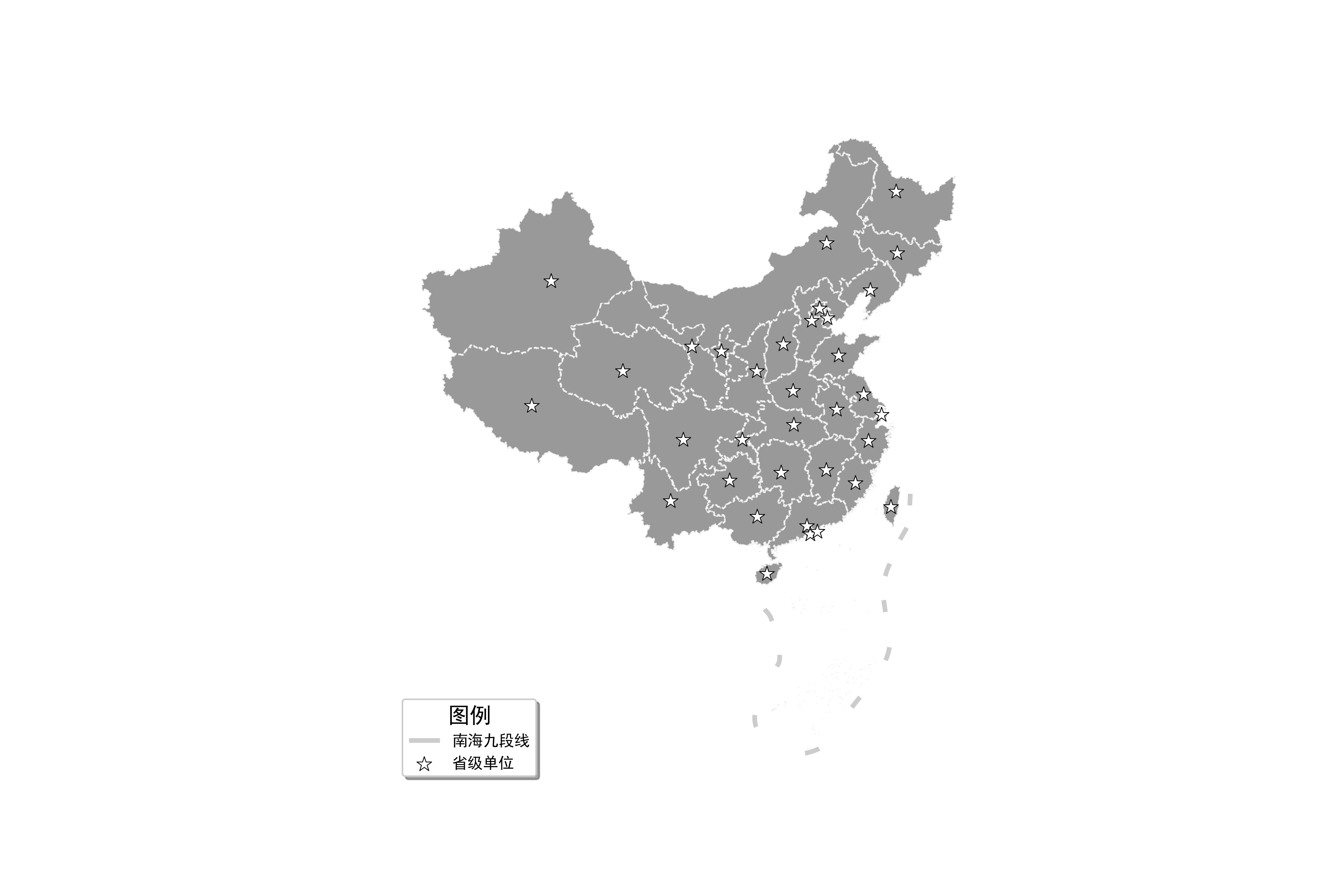 图15
图15
接下来我们把标记每个省级单位的星星换成名称文字,这里使用到matplolib中的text()方法,其以此传入对应循环到的点的x、y、文字内容,ha与va用于调整文字水平和竖直对齐方式,size调整文字大小,更具体的参数可以去matplotlib官网搜索查看,本文不做重点介绍:
fig, ax = plt.subplots(figsize=(12, 8))
ax = china.geometry.to_crs(albers_proj).plot(ax=ax,
facecolor='grey',
edgecolor='white',
linestyle='--',
alpha=0.8)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4,
label='南海九段线')
# 根据转换过投影的代表点,循环添加文字至地图上对应位置
for idx, _ in enumerate(china.geometry.representative_point().to_crs(albers_proj)):
# 提取省级单位简称
if ('自' in china.loc[idx, 'OWNER'] or '特' in china.loc[idx, 'OWNER']) \
and china.loc[idx, 'OWNER'] != '内蒙古自治区':
region = china.loc[idx, 'OWNER'][:2]
else:
region = china.loc[idx, 'OWNER'].replace('省', '') \
.replace('市', '') \
.replace('自治区', '')
ax.text(_.x, _.y, region, ha="center", va="center", size=6)
# 单独提前设置图例标题大小
plt.rcParams['legend.title_fontsize'] = 14
# 设置图例标题,位置,排列方式,是否带有阴影
ax.legend(title="图例", loc='lower left', ncol=1, shadow=True)
ax.axis('off') # 移除坐标轴
fig.savefig('图16.png', dpi=300)
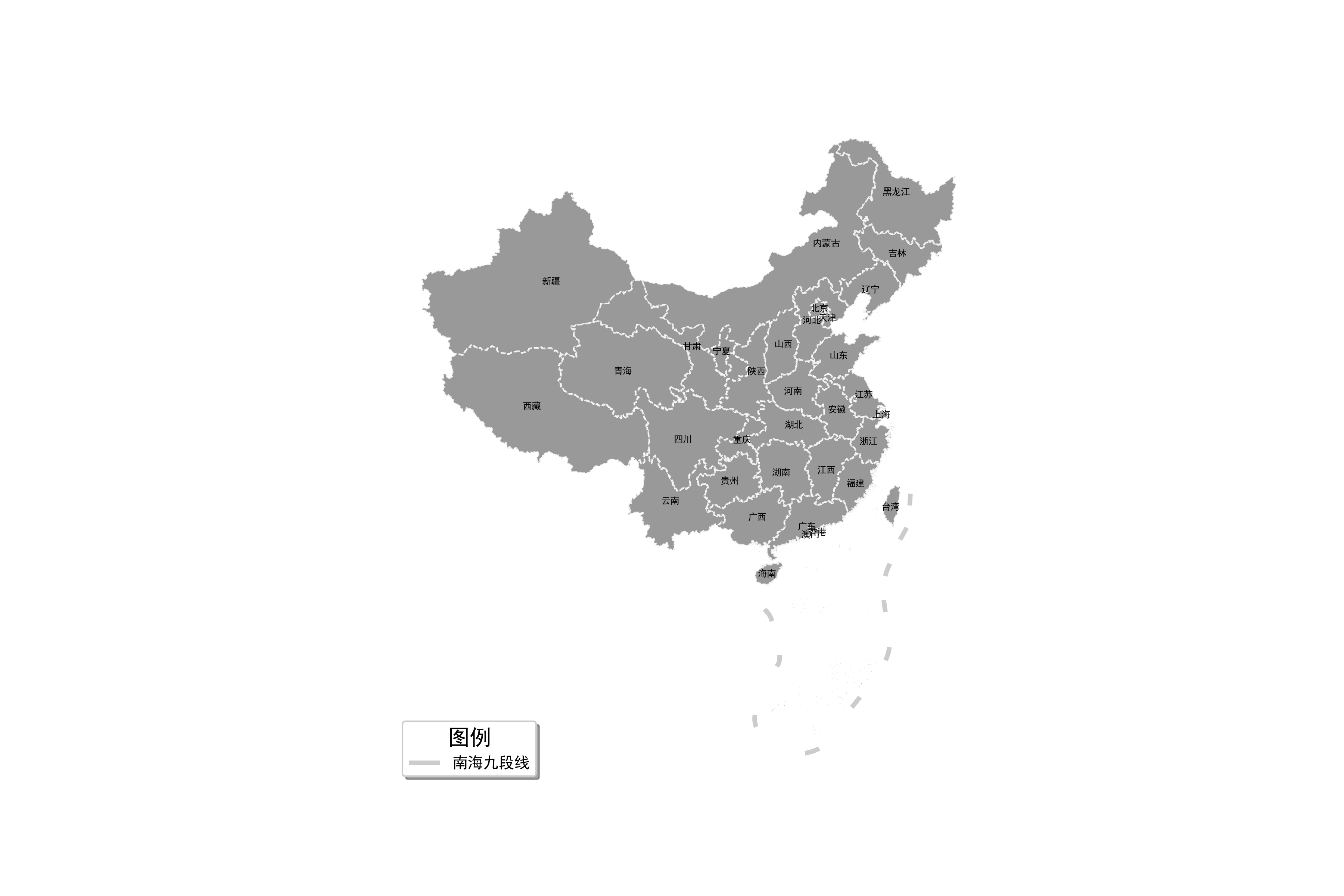 图16
图16
- Step7:添加小地图
大家平时如果留意会记得,我们一般看到的中国地图其南海区域都是单独在右下角的小地图里显示出来的,在geopandas里制作这种地图非常简单,我们只需要结合matplotlib中添加子图区域的add_axes(),即可完成制作,先来认识一下add_axes()的功能,它最重要的参数是rect,通过传入形如(bottom, left, width, height)来实现在图床中开辟子区域,让我们从下面简单的例子出发好好理解,首先我们使用plt.figure()创建一个方形画布,并在画布上使用add_axes((0, 0, 1, 1)):
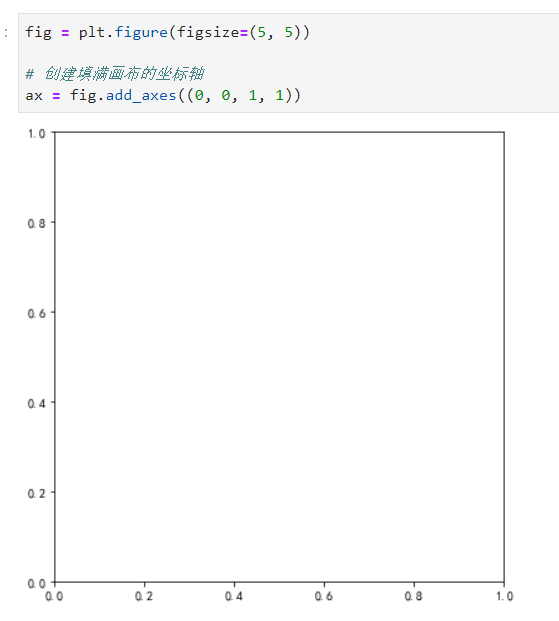 图17
图17
发现原理了吗?我们传入的(0, 0, 1, 1),其前两位其实代表着子图区域左下角坐标在整个画布中的比例坐标!而后两位则代表则代表着子图区域的相对于整个画布的比例宽度与长度!接着我们再为fig开辟新的子区域,并在新开辟的子区域正中心写上文字:
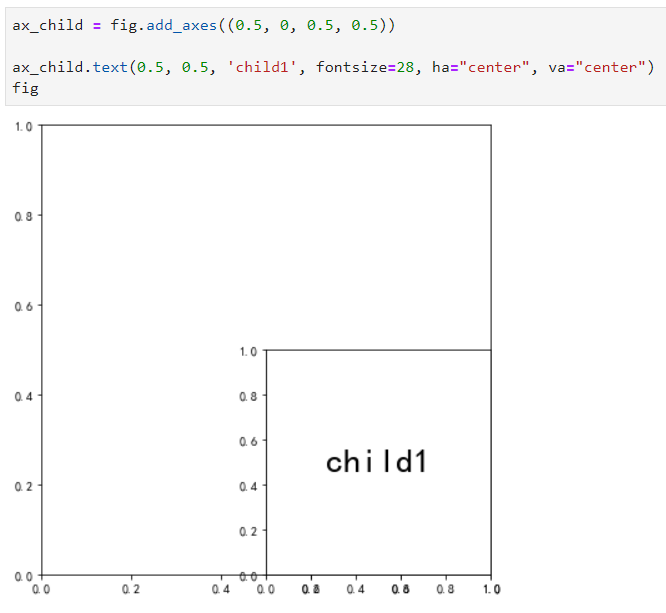 图18
图18
新的子图区域左下角坐标位于画布的底边中点,比例长宽均为0.5,所以得到了如图所示的效果,搞明白了这些之后,下面我们就可以来画带小地图的中国地图啦:
首先我们需要分别对中国地图以及南海插图的经纬度范围进行限定,因为并没有找到严格的范围规定,所以这里我们大致定义一下中国地图和南海插图的最小最大经纬度,生成GeoDataFrame并添加矢量信息,最后进行合适的投影转换:
from shapely.geometry import Point
bound = gpd.GeoDataFrame({
'x': [80, 150, 106.5, 123],
'y': [15, 50, 2.8, 24.5]
})
# 添加矢量列
bound.geometry = bound.apply(lambda row: Point([row['x'], row['y']]), axis=1)
# 初始化CRS
bound.crs = 'EPSG:4326'
# 再投影
bound.to_crs(albers_proj, inplace=True)
bound
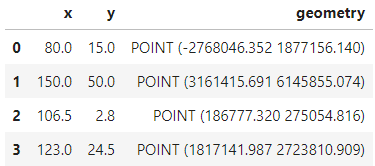 图19
图19
接下来的步骤就一目了然了,只需要把前文绘制地图部分的手法分别移植到两个子图上即可:
fig = plt.figure(figsize=(8, 8))
# 创建覆盖整个画布的子图1
ax = fig.add_axes((0, 0, 1, 1))
ax = china.geometry.to_crs(albers_proj).plot(ax=ax,
facecolor='grey',
edgecolor='white',
linestyle='--',
alpha=0.8)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4,
label='南海九段线')
# 单独提前设置图例标题大小
plt.rcParams['legend.title_fontsize'] = 14
# 设置图例标题,位置,排列方式,是否带有阴影
ax.legend(title="图例", loc='lower left', ncol=1, shadow=True)
ax.axis('off') # 移除坐标轴
ax.set_xlim(bound.geometry[0].x, bound.geometry[1].x)
ax.set_ylim(bound.geometry[0].y, bound.geometry[1].y)
# 创建南海插图对应的子图,这里的位置和大小信息是我调好的,你可以试着调节看看有什么不同
ax_child = fig.add_axes([0.75, 0.15, 0.2, 0.2])
ax_child = china.geometry.to_crs(albers_proj).plot(ax=ax_child,
facecolor='grey',
edgecolor='white',
linestyle='--',
alpha=0.8)
ax_child = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax_child,
edgecolor='grey',
linewidth=3,
alpha=0.4,
label='南海九段线')
ax_child.set_xlim(bound.geometry[2].x, bound.geometry[3].x)
ax_child.set_ylim(bound.geometry[2].y, bound.geometry[3].y)
# 移除子图坐标轴刻度,因为这里的子图需要有边框,所以只移除坐标轴刻度
ax_child.set_xticks([])
ax_child.set_yticks([])
fig.savefig('图20.png', dpi=300)
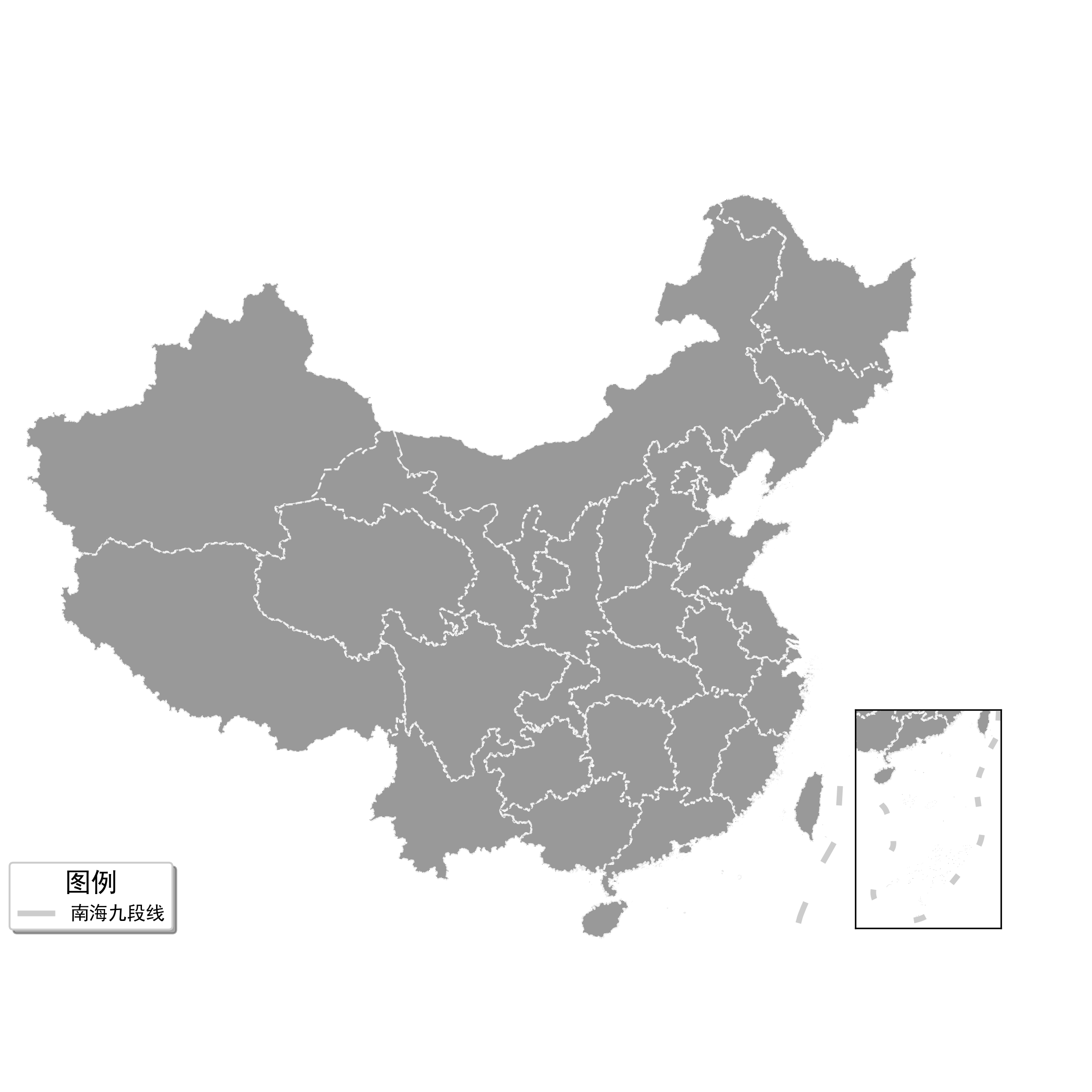 图20
图20
2.2 GeoDataFrame
介绍完了围绕GeoSeries展开的绘图方法,下面我们来学习geopandas中围绕GeoDataFrame展开的可视化方法。
与GeoSeries相比,GeoDataFrame拥有多列数据,即我们可以将辅助列的数值信息映射到地图的视觉元素上,因此在GeoSeries常用参数的基础上,新增了更多参数:
column:用于指定映射地图视觉元素的数值信息,可以是对应
GeoDataFrame的列名,或是直接传入与几何对象一一对应得数值序列,默认为Nonecmap:传入映射视觉元素时的色彩方案,具体使用方式下文中会做详细介绍
categorical:bool型,True表示指定映射目标列采取离散表示,对于数值型的列有意义,当对应目标列为类别型时自动变为True
legend:bool型,为True时会为地图添加图例
scheme:str型,用于指定地区分布图分层设色的数值划分方案,下文中会做详细介绍
k:int型,用于指定分层设色的色阶数量
vmin:None或float,用于指定分层设色的数值范围下限,默认为None即以对应数据中的最小值为下限
vmax:None或float,用于指定分层设色的数值范围上限,默认为None即以对应数据中的最大值为上限
legend_kwds:字典型,传入与图例相关的个性化参数
classification_kwds:字典型,传入与分层设色相关的个性化参数
missing_kwds:字典型,传入与缺失值处理相关的个性化参数,用于对缺失值部分的视觉映射做个性化设置
同样的,我们以实际例子出发,这里我们使用新冠肺炎疫情数据,数据来源:https://github.com/BlankerL/DXY-COVID-19-Data ,同样地你可以在本文开头列出的Github仓库中对应本文的路径下找到下文所使用的数据,首先我们先对原数据做一些预处理,以得到每个省份最新一次更新记录的数据:
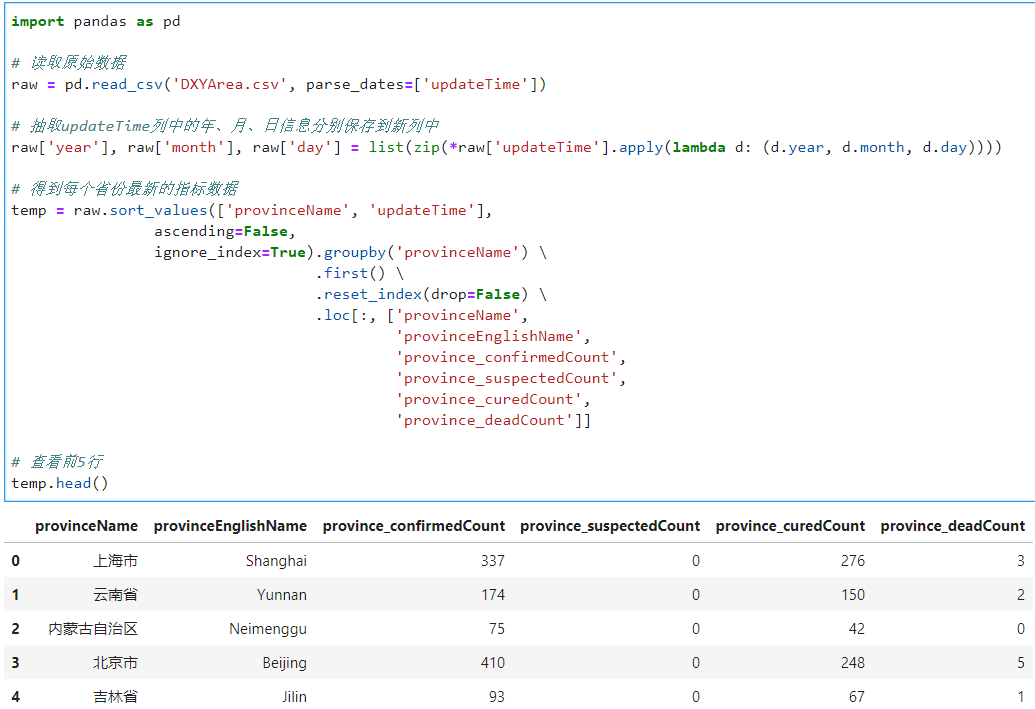 图21
图21
这样就得到我们所需的数据。
2.2.1 地区分布图与分层设色
地区分布图(Choropleth Map),指的是依据指定属性进行层次划分,并将对应的层次映射到对应几何对象的色彩之上,下面我们先将上面处理好的表格数据与china相关联,因为geopandas支持pandas的连接操作,所以我们使用pd.merge()以省级单位名称为键来连接两张表(由于连接之后的表格会变成pandas.DataFrame,所以这里将其转换回GeoDataFrame):
data_with_geometry = pd.merge(left=temp.replace('澳门', '澳门特别行政区'),
right=china,
left_on='provinceName',
right_on='OWNER',
how='right'
).loc[:, ['provinceName',
'provinceEnglishName',
'province_confirmedCount',
'province_suspectedCount',
'province_curedCount',
'province_deadCount',
'geometry'
]]
# 将数据从DataFrame转换为GeoDataFrame
data_with_geometry = gpd.GeoDataFrame(data_with_geometry, crs='EPSG:4326')
data_with_geometry.head()
 图22
图22
有了数据,我们先很“愚蠢鲁莽”地直接将province_confirmedCount即地区确诊数作为映射值传入参数column,并选择cmap为经典的Reds红色渐变配色,以及调整一些前文中我们已经很熟悉的参数,看看得到什么样的结果:
 图23
图23
为什么会得到这样奇怪的结果?让我们逐一来分析一下问题所在:
- 台湾省跑哪里去了?
细心的你一定会发现,我们的宝岛台湾不见了,这并不是我们的几何对象中缺失了它,一个中国一寸土地都不可缺少,真正使得它消失的原因在于我们的原始数据中其实缺失香港和台湾的数据,我们前面连接过程使用的右连接的方法使得我们保留了所有的土地,但是台湾和香港由于数据缺失,对应数据位置是NaN,因此在数值映射到色彩的过程中变成了默认的白色,这时候missing_kwds参数就起到大用处了:
fig, ax = plt.subplots(figsize=(12, 12))
# 新增缺失值处理参数
ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax,
column='province_confirmedCount',
cmap='Reds',
missing_kwds={
"color": "lightgrey",
"edgecolor": "black",
"hatch": "////"
})
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax.axis('off')
fig.savefig('图24.png', dpi=300)
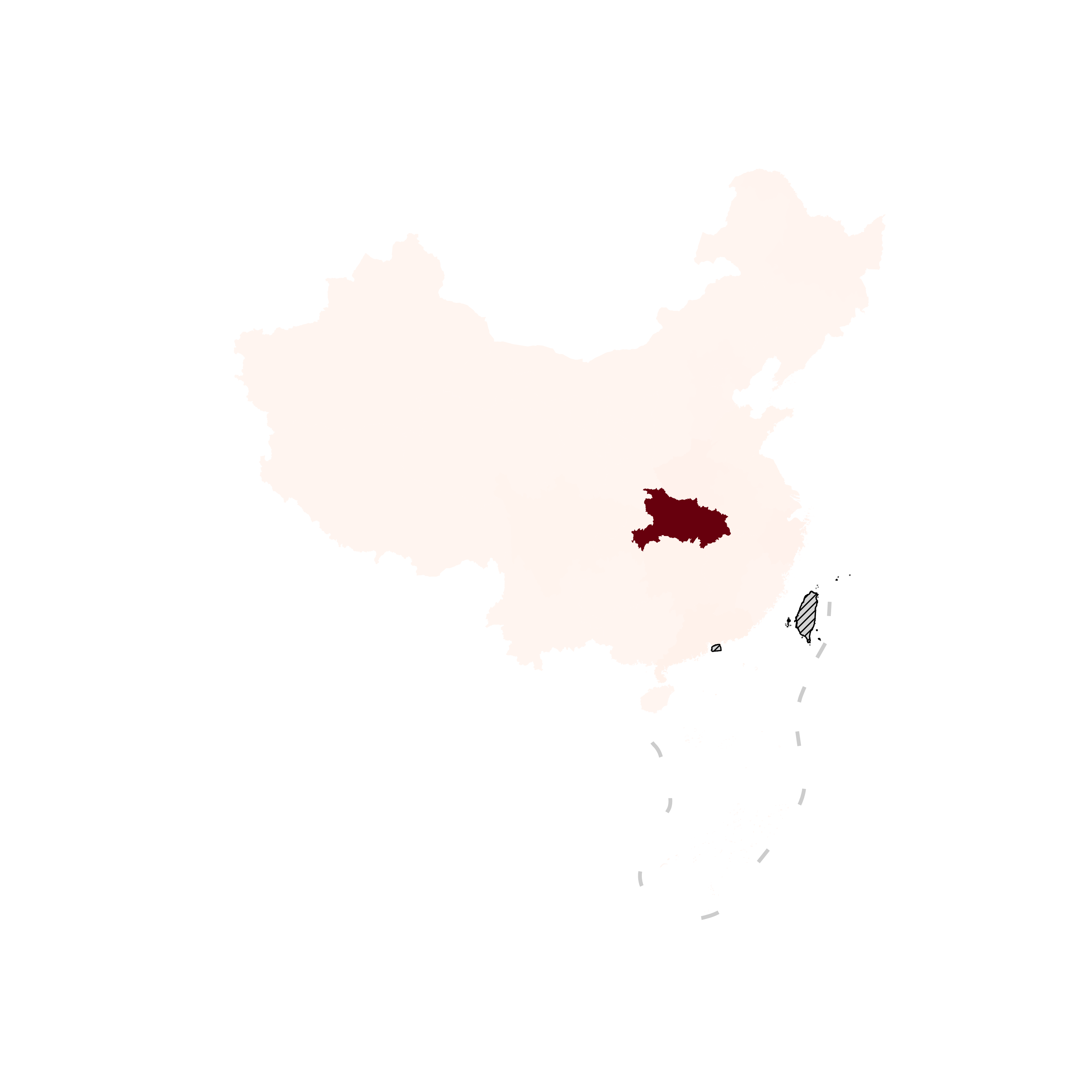 图24
图24
在字典格式的missing_kwds参数中,我们用color设置了缺失值区域的底色,用edgecolor设置了缺失值区域的线条颜色,并且用hatch设置了阴影填充样式,这样一来哪些地方缺失数据记录就一目了然了。
- 为什么只有湖北省颜色这么深?
的确,这样的地图给我们的感觉就是:湖北省很严重,其他地方没什么区别嘛,我们在图24的基础上加上数值-色彩参考:
fig, ax = plt.subplots(figsize=(12, 12))
ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax,
column='province_confirmedCount',
cmap='Reds',
missing_kwds={
"color": "lightgrey",
"edgecolor": "black",
"hatch": "////"
},
legend=True)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax.axis('off')
fig.savefig('图25.png', dpi=300)
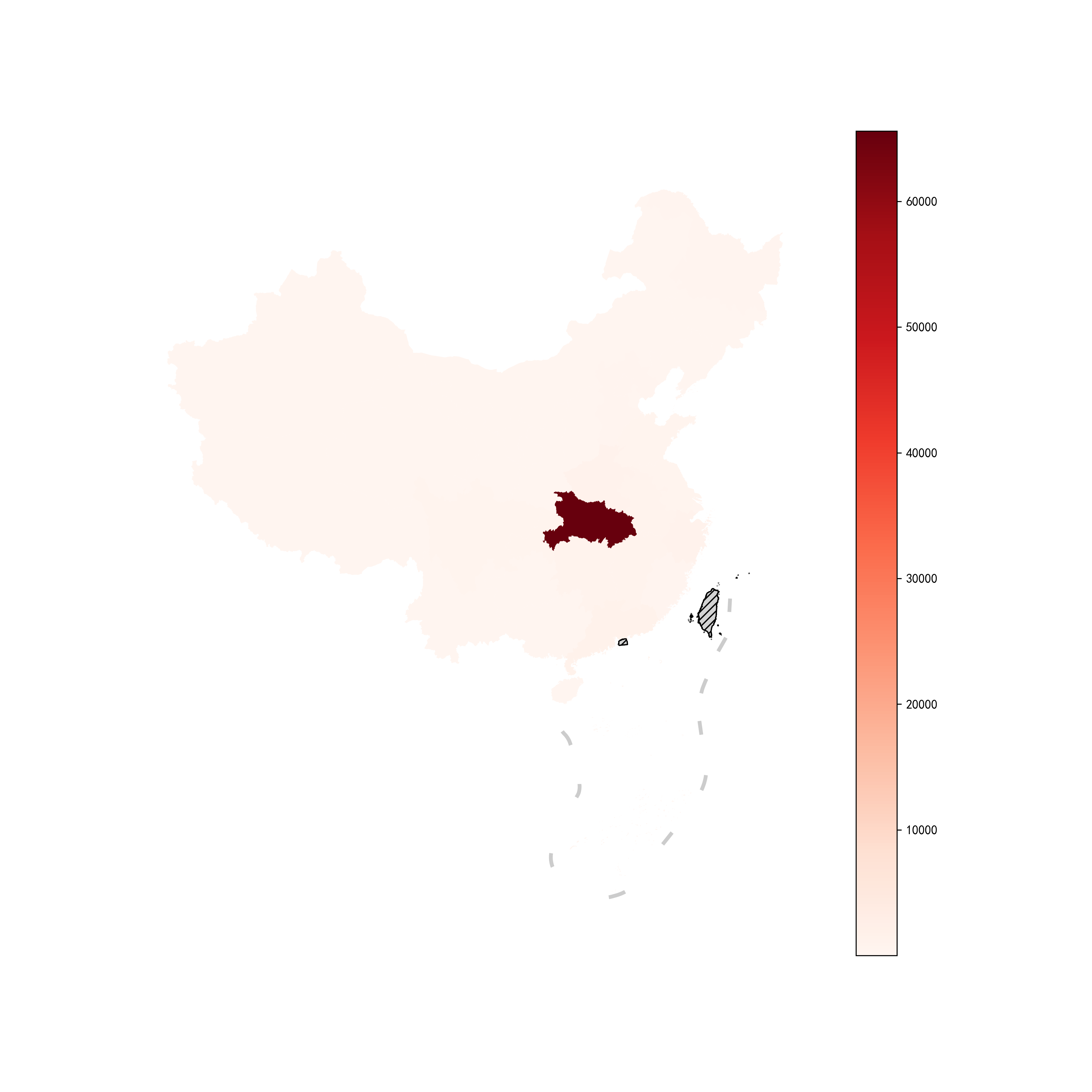 图25
图25
这下我们搞清楚了,原来是因为湖北省的数据过于大,使得数值在均匀向有序色阶上映射时,除湖北省之外的其他数据都被压缩到非常浅色的区域,这时就到了本小结的主题——分层设色,这里就涉及到相关的核心参数scheme以及k,其中scheme决定了数据分层的方法,其通过调用第三方包mapclassify中用于给数据分层的方法),来实现geopandas中的分层设色,譬如下面我们在图25的基础上,使用我们喜闻乐见的自然断点法对应的'NaturalBreaks'作为参数,选择分段数量k=5,来看看会有什么样的效果:
fig, ax = plt.subplots(figsize=(12, 12))
ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax,
column='province_confirmedCount',
cmap='Reds',
missing_kwds={
"color": "lightgrey",
"edgecolor": "black",
"hatch": "////"
},
legend=True,
scheme='NaturalBreaks',
k=5)
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax.axis('off')
fig.savefig('图26.png', dpi=300)
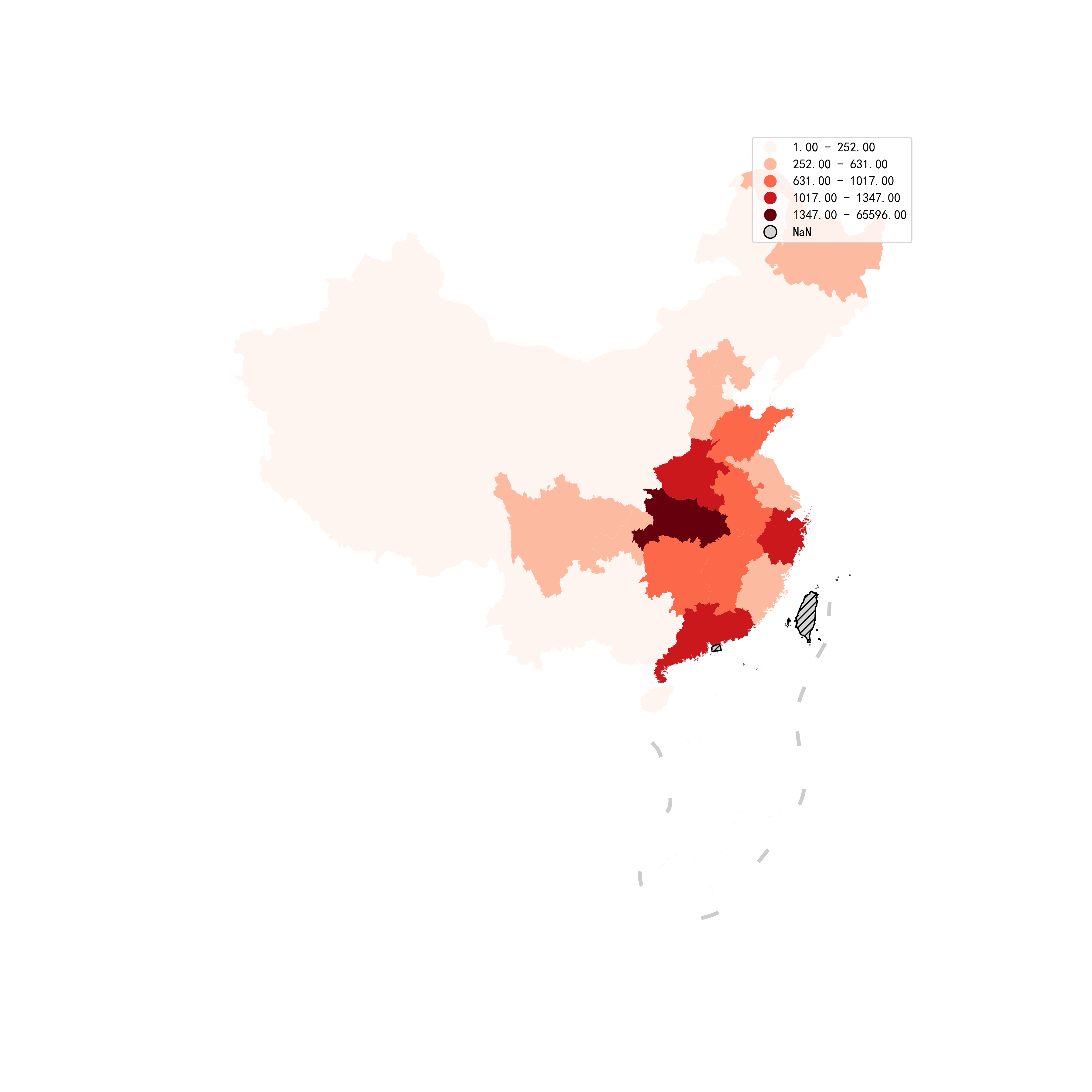 图26
图26
这时可以看到,区域颜色的分布更加温和,也使得我们看出了不同地区在疫情严重程度上的区别,且因为这时变成了离散的分层,所以图例也由比色卡变为更为标准的分类图例,但是这个图例默认在右上角,对地图造成了较为明显的遮挡,下面我们在图26的基础上,利用参数legend_kwds,以及missing_kwds参数下的label,对其进行美化:
fig, ax = plt.subplots(figsize=(12, 12))
ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax,
column='province_confirmedCount',
cmap='Reds',
missing_kwds={
"color": "lightgrey",
"edgecolor": "black",
"hatch": "////",
"label": "缺失值"
},
legend=True,
scheme='NaturalBreaks',
k=5,
legend_kwds={
'loc': 'lower left',
'title': '确诊数量分级',
'shadow': True
})
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax.axis('off')
fig.savefig('图27.png', dpi=300)
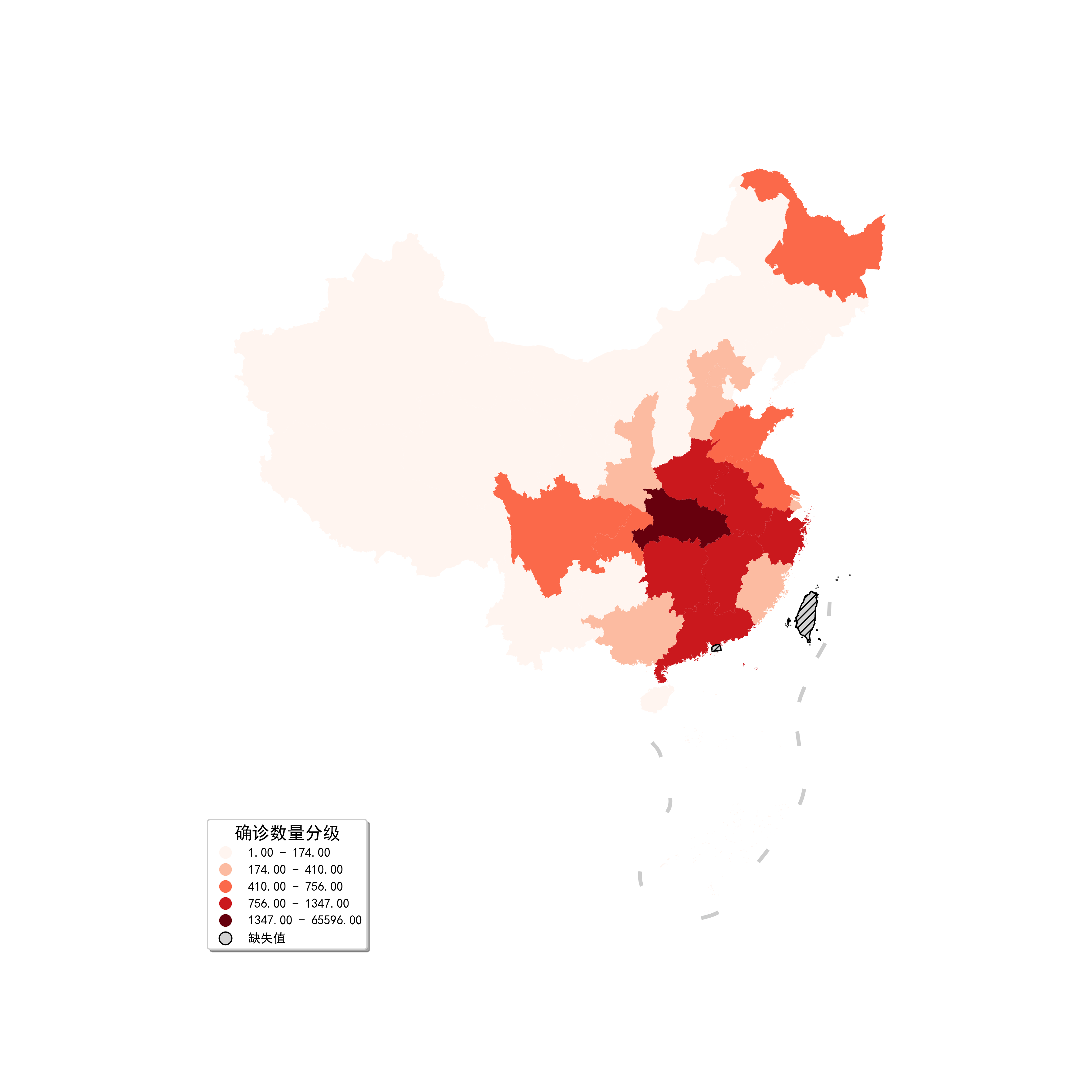 图27
图27
至此我们的地图已经比最开始美观了很多,再为其添加大标题、小标题和数据说明文字,这样一张谈不上好看但还凑合的疫情地图便制作完毕:
fig, ax = plt.subplots(figsize=(12, 12))
ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax,
column='province_confirmedCount',
cmap='Reds',
missing_kwds={
"color": "lightgrey",
"edgecolor": "black",
"hatch": "////",
"label": "缺失值"
},
legend=True,
scheme='NaturalBreaks',
k=5,
legend_kwds={
'loc': 'lower left',
'title': '确诊数量分级',
'shadow': True
})
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax.axis('off')
plt.suptitle('新型冠状肺炎累计确诊数量地区分布', fontsize=24) # 添加最高级别标题
plt.title('截至2020年02月27日', fontsize=18) # 添加大标题
plt.tight_layout(pad=4.5) # 调整不同标题之间间距
ax.text(-2800000, 1000000, '* 原始数据来源:丁香园,\n其中台湾及香港数据缺失') # 添加数据说明
fig.savefig('图28.png', dpi=300)
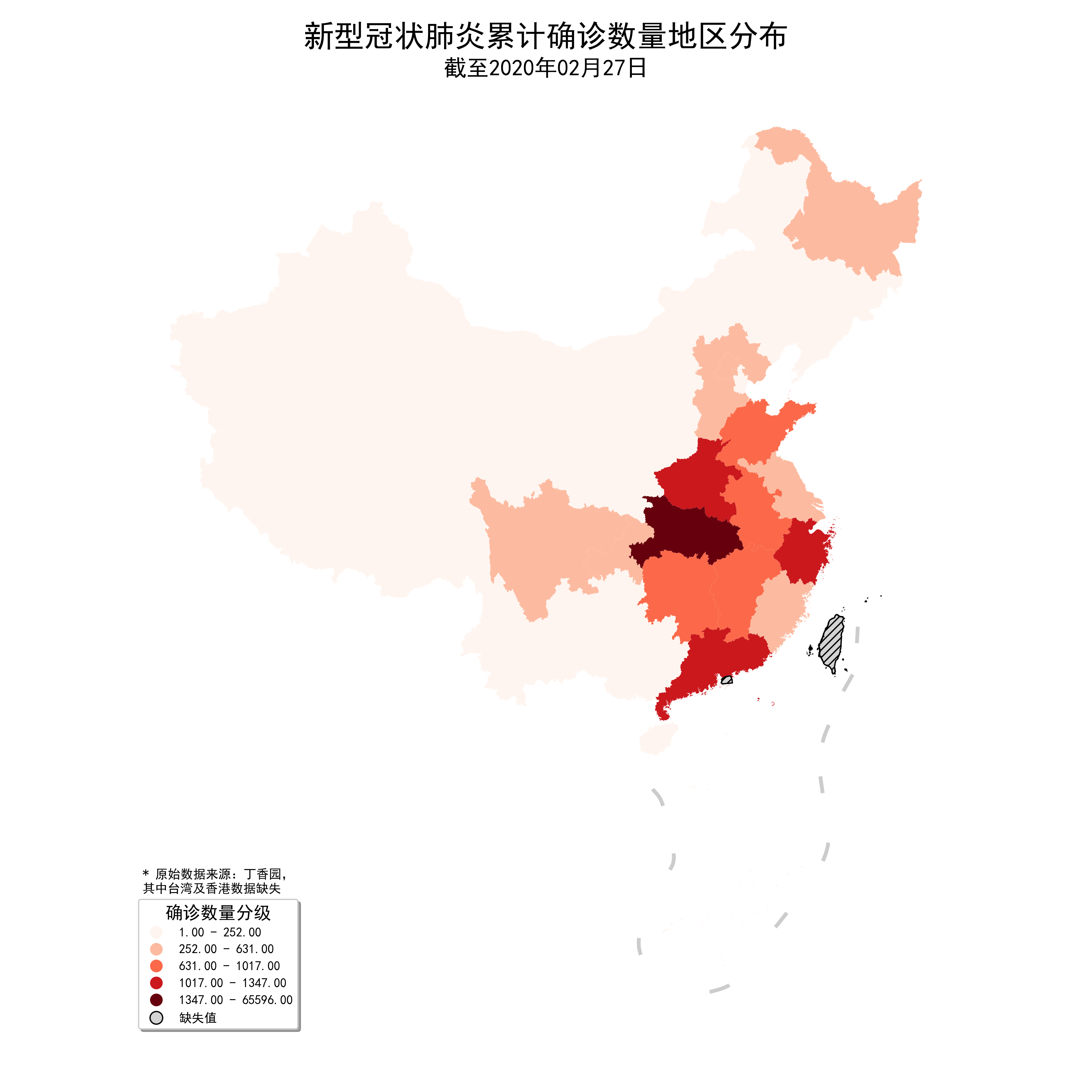 图28
图28
2.2.2 搭配matplotlib实现创作
geopandas虽然自带了如此丰富的地图绘制功能,但很多时候作图仅仅靠它是不够的,想要实现更加个性化的效果,需要结合matplotlib中丰富的功能,如下图是我随意结合matplotlib中的若干功能实现的个性化可视化,叠加了较多元素,由于篇幅有限,代码不在此放出,你可以去文章开头的Github仓库查看本文所有代码,尝试用你喜欢的颜色来对地图调色:
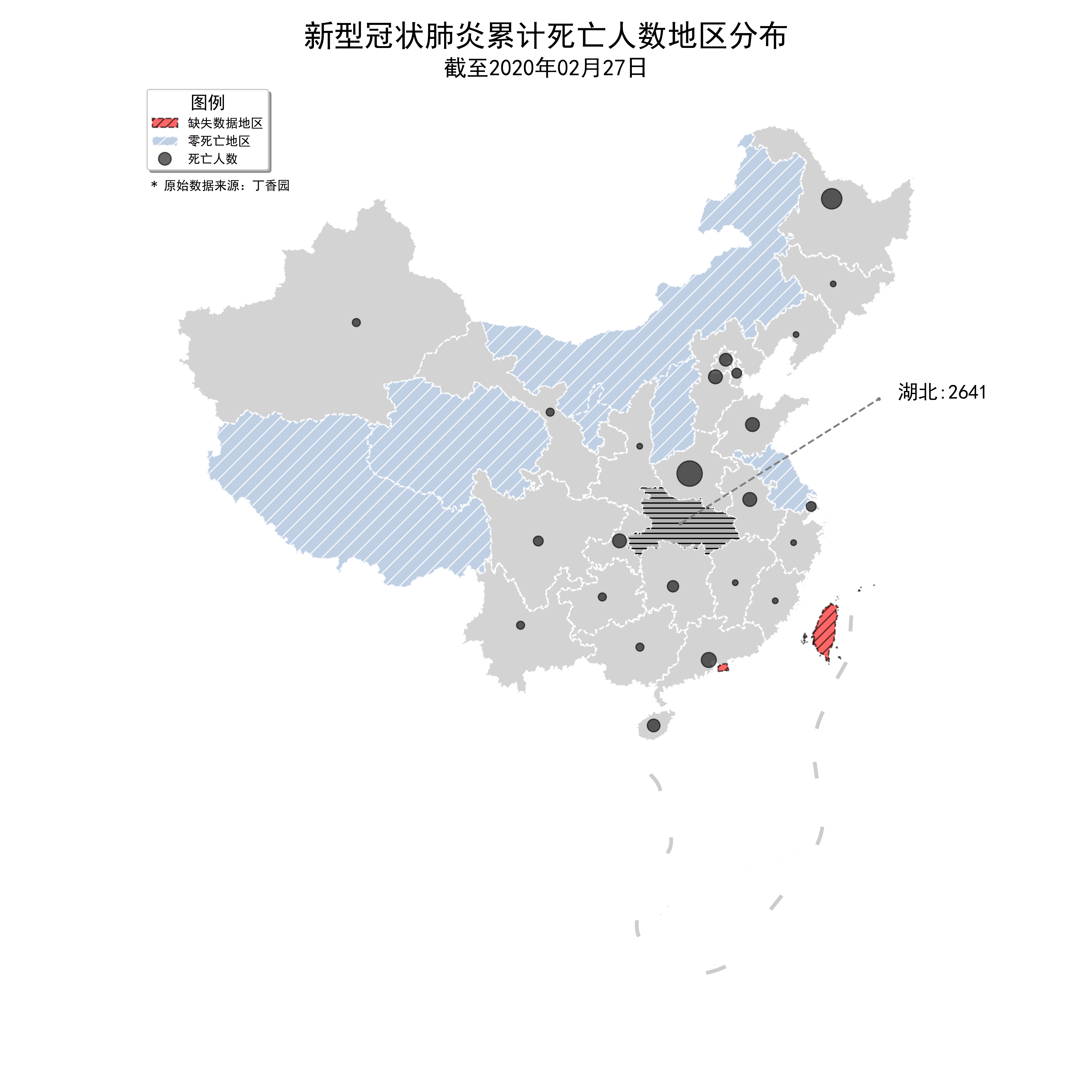 图29
图29
2.2.3 在模仿中学习
成为数据可视化专家不是一件容易的事,但我们可以先从模仿其他大师的优秀作品出发,譬如图30来自于Github仓库https://github.com/Z3tt/TidyTuesday ,这个仓库包含了众多基于R的优秀作品,而图30就是其中之一,对澳洲大火造成的影响进行可视化:
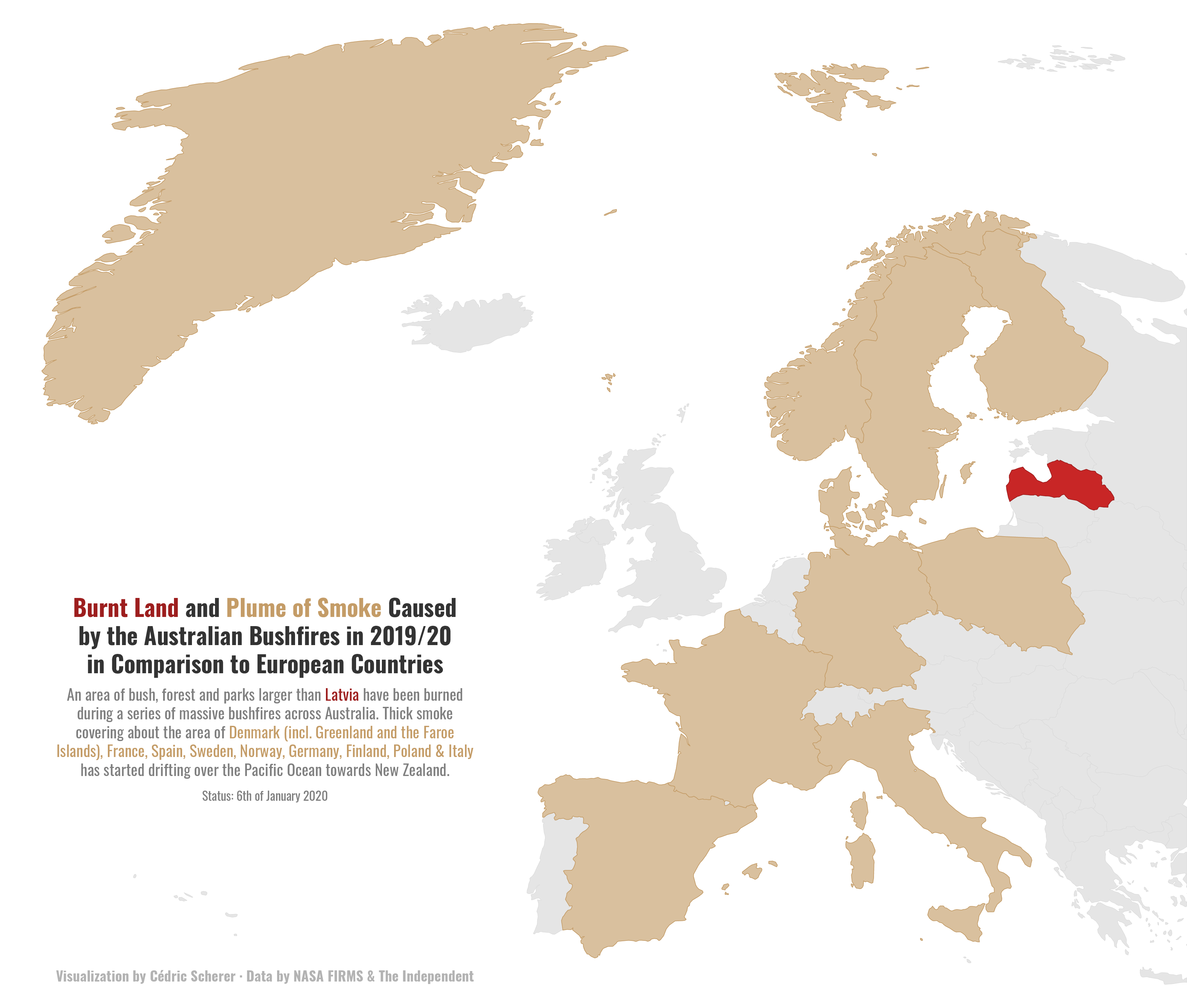 图30
图30
而下面的图31就是我利用geopandas对图30的大致模仿,其中字体部分原始的R脚本中使用ggtext实现方便的富文本生成,而Python中我暂时没找到类似功能的轮子,所以这里文字部分比较简陋:
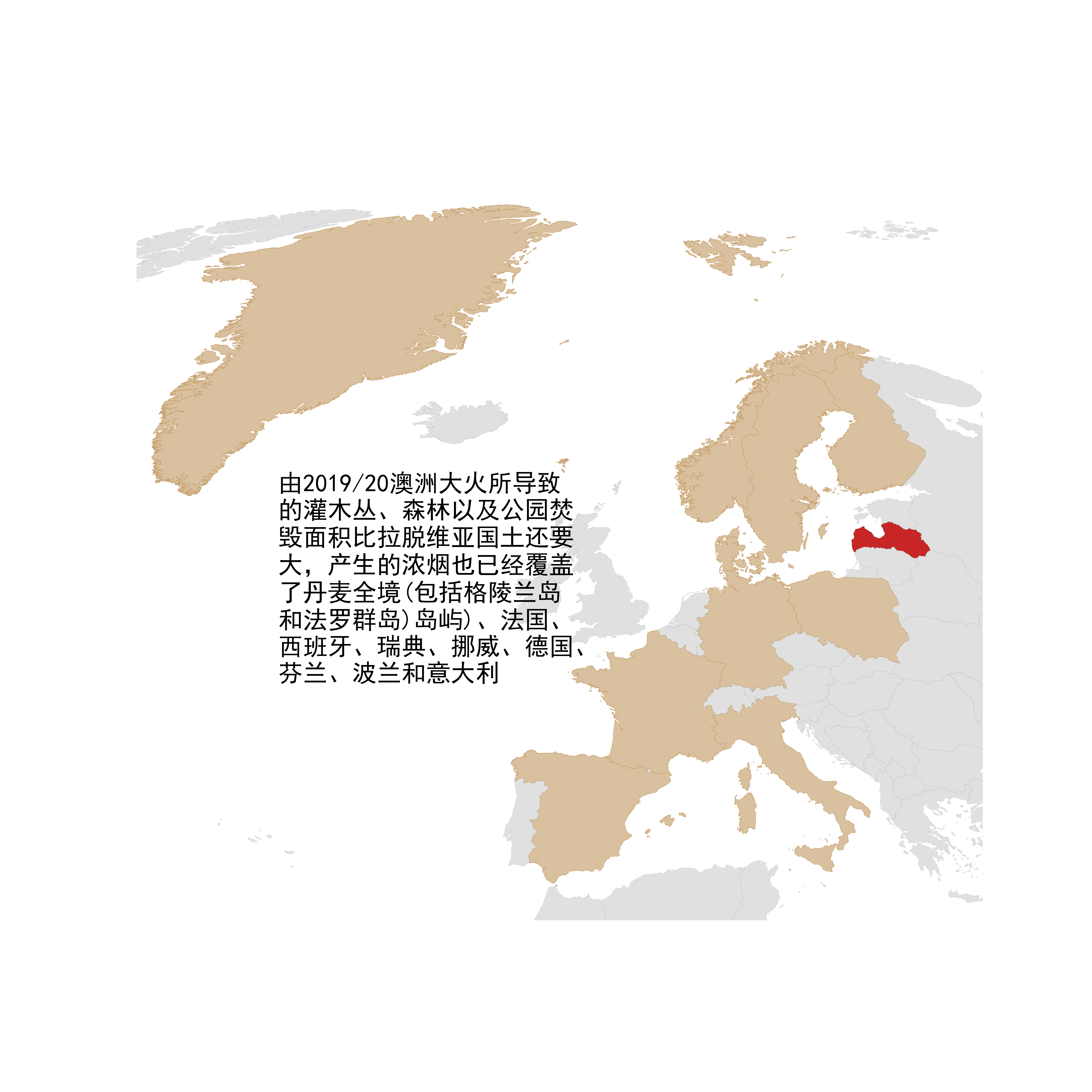 图31
图31
对应的代码如下,其中使用到的矢量数据是我搜集到的精度较高的世界地图数据:
world = gpd.read_file('world')
world['SOVEREI']
smoke_list = ['Denmark', 'France', 'Spain', 'Sweden', 'Norway', 'Germany', 'Finland', 'Poland', 'Italy', 'Greenland']
burnt_list = ['Latvia']
fig, ax = plt.subplots(figsize=(8, 8))
crs = '+proj=moll +lon_0=0 +x_0=0 +y_0=0 +ellps=WGS84 +datum=WGS84 +units=m +no_defs'
# 绘制过烟区域
ax = world[world['SOVEREI'].isin(smoke_list)] \
.to_crs(crs) \
.plot(ax=ax,
facecolor='#d9c09e',
edgecolor='#c49c67',
linewidth=0.2)
# 绘制拉脱维亚
ax = world[world['SOVEREI'].isin(burnt_list)] \
.to_crs(crs) \
.plot(ax=ax,
facecolor='#c82626',
edgecolor='#9d1e1e',
linewidth=0.2)
# 绘制剩余国家
ax = world[-(world['SOVEREI'].isin(smoke_list) | world['SOVEREI'].isin(burnt_list))] \
.to_crs(crs) \
.plot(ax=ax,
facecolor='lightgrey',
edgecolor='grey',
linewidth=0.05,
alpha=0.7)
ax.set_xlim([-3200000, 2300000])
ax.set_ylim([4100000, 9000000])
ax.axis('off')
# 添加文字
plt.text(-3*10**6, 5.5*10**6,
'''
由2019/20澳洲大火所导致
的灌木丛、森林以及公园焚
毁面积比拉脱维亚国土还要
大,产生的浓烟也已经覆盖
了丹麦全境(包括格陵兰岛
和法罗群岛)岛屿)、法国、
西班牙、瑞典、挪威、德国、
芬兰、波兰和意大利
''',
fontdict={
'color': 'black',
'weight': 'bold',
'size': 13
})
plt.savefig('图31.png', dpi=500)
以上就是本文的全部内容,如有笔误望指出,接下来的文章我将会继续介绍更高级的地图可视化方法,敬请期待!
最新文章
- Collection集合的功能及总结
- jquery1.7.2的源码分析(二)
- Hibernate第一个例子
- Put-Me-Down项目Postmortem2
- Linear regression with one variable算法实例讲解(绘制图像,cost_Function ,Gradient Desent, 拟合曲线, 轮廓图绘制)_矩阵操作
- Java知多少(完结篇)
- JavaScript获取后台C#变量以及调用后台方法
- hdu 4046 Panda 树状数组
- nginx之location配置
- always NetWork Performance measure Tools
- [iOS UI进阶 - 2.3] 彩票Demo v1.3
- 对于百川SDK签名验证的问题
- cocos2d-x游戏开发系列教程-中国象棋05-开始游戏
- React 深入系列3:Props 和 State
- RxJava(四) concatMap操作符用法详解
- 外媒评李开复的《AI·未来》:四大浪潮正在席卷全球
- 小梵同学 GO!
- 数据库_Redis 入门基础到高级
- vue之router钩子函数
- Video Frame Synthesis using Deep Voxel Flow 论文笔记