Django 项目补充知识(JSONP,前端瀑布流布局,组合搜索,多级评论)
一.JSONP
1浏览器同源策略
通过Ajax,如果在当前域名去访问其他域名时,浏览器会出现同源策略,从而阻止请求的返回
由于浏览器存在同源策略机制,同源策略阻止从一个源加载的文档或脚本获取或设置另一个源加载的文档的属性。
特别的:由于同源策略是浏览器的限制,所以请求的发送和响应是可以进行,只不过浏览器不接受罢了。
浏览器同源策略并不是对所有的请求均制约:
- 制约: XmlHttpRequest
- 不叼: img、iframe、script,link等具有src属性的标签,不鸟同源策略
利用 不鸟同源策略 的标签,发送跨域Ajax请求, <script>标签
同源ajax请求Jquery实现方法:
function Ajax(){
$.ajax({
url: '/get_data/',
type: 'POST',
data: {'k1': 'v1'},
success: function (arg) {
alert(arg);
}
})
}
跨域ajax,例如当前页面设置域名为wangjian.com,请求域名为jasonwang.com,具体代码如下:
function Ajax2(){
$.ajax({
url: 'http://jasonwang.com:8001/api/',
type: 'GET',
data: {'k1': 'v1'},
success: function (arg) {
alert(arg);
}
})
}
虽然被请求域名jasonwang.com可以接受请求,但由于浏览器的同源策略,请求域名wangjian.com无法获取到该资源。报错如下截图:

如何解决此类问题呢,JSONP出场啦,其内部实现原理是借用img,script,link,frame等带有src属性的标签,不受同源策略限制,可以摆脱此限制,不过需要注意的是,只能对get方法生效,由于src等均是痛get方法获取请求,所以对POST方法并无效果。模拟jquery内部事项跨域请求如下:
jasonwang.com此域名后台处理相关代码:
from django.shortcuts import render,HttpResponse
import json
# Create your views here. def api(request):
li = ['alex', 'eric', 'tony']
# "['alex', 'eric', 'tony']"
temp = "fafafa(%s)" %(json.dumps(li))
# fafafa(['alex', 'eric', 'tony'])
return HttpResponse(temp)
wangjian.com此域名前端请求jasonwang.com内部js代码:
function Ajax3(){
// script
// alert(api)
var tag = document.createElement('script');
tag.src = 'http://jasonwang.com:8001/api/';
document.head.appendChild(tag);
document.head.removeChild(tag);
}
function fafafa(arg){
console.log(arg);
}
此时可以实现跨域请求

Jquery内实现便是基于以上原理实现,首先在head创建带有src属性的标签,如script,img等,并将src设定为要跨域的域名,最后添加删除此标签以获取跨域请求的资源
Jquery中应用JSONP方法如下:
function Ajax5(){
// script
// alert(api)
$.ajax({
url: 'http://www.jxntv.cn/data/jmd-jxtv2.html',
type: 'GET',
dataType: 'jsonp',
jsonp: 'callback',
{# jsonpcallback: 'list',#}
success: function (arg) {
console.log(arg);
}
})
}
function list(arg){
console.log(arg);
}
可以简单地将这个理解为JSONP类型请求回调函数,jQuery在我们每次指定Ajax请求方式为JSONP时都会生成这么一个JSONP回调函数。虽然jQuery会自动帮我们生成一个回调函数,但是我们也可以通过设置jsonpCallback参数为jsonp请求定制一个我们自己的回调函数。
2.是否可以发POST请求?
不能发POST
<script src='http://www.jxntv.cn/data/jmd-jxtv2.html?callback=qwerqweqwe&_=1454376870403'>
==> 最终全部都会转换成GET请求
扩展:
跨域Ajax ->
JSONP
CORS-跨站资源共享,浏览器版本要求
随着技术的发展,现在的浏览器可以支持主动设置从而允许跨域请求,即:跨域资源共享(CORS,Cross-Origin Resource Sharing),其本质是设置响应头,使得浏览器允许跨域请求。
二.瀑布流式布局实现方法:
瀑布流 ,又称瀑布流式布局。是比较流行的一种网站页面布局,视觉表现为参差不齐的多栏布局,随着页面滚动条向下滚动,这种布局还会不断加载数据块并附加至当前尾部。最早采用此布局的网站是Pinterest,逐渐在国内流行开来。国内大多数清新站基本为这类风格。
绝对定位方式的瀑布流布局:
一、布局
1、包围块框的容器:
<div class="container">
<div class="column"> </div>
<div class="column"> </div>
<div class="column"> </div>
<div class="column"> </div>
</div>
2.将容器分割成几列,每一列添加信息,形成类似瀑布流式的前端展现效果,一下为容器样式
<style>
.container{
width: 980px;
margin: 0 auto;
}
.container .column{
float: left;
width: 245px;
}
.container .item img{
width: 245px;
}
</style>
3.通过Django自定义tag对后台传给前端的图片列表信息分离处理。
模版语言中自定义函数:
simple_tag
参数:可以传多个参数 hanshu 1 2 3
条件:
模版语言
{% if hanshu 1 2 3 %}
filter
参数:传一个 hanshu|"1,2,3"
条件:
模版语言
{% if 123|hanshu %}
自定义templatetags,代码如下:
from django import template
from django.utils.safestring import mark_safe
from django.template.base import resolve_variable, Node, TemplateSyntaxError register = template.Library() @register.filter
def detail1(value,arg): """
查看余数是否等于remainder arg="1,2"
:param counter:
:param allcount:
:param remainder:
:return:
"""
allcount, remainder = arg.split(',')
allcount = int(allcount)
remainder = int(remainder)
if value%allcount == remainder:
return True
return False
自定义tag分配照片信息
{% load xx %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
<style>
.container{
width: 980px;
margin: 0 auto;
}
.container .column{
float: left;
width: 245px;
}
.container .item img{
width: 245px;
}
</style>
</head>
<body>
<div class="container">
<div class="column">
{% for i in img_list %}
{% if forloop.counter|detail1:"4,1" %}
<div class="item">
{{ forloop.counter }}
<img src="/static/{{ i.src }}">
</div>
{% endif %}
{% endfor %}
</div>
<div class="column">
{% for i in img_list %}
{% if forloop.counter|detail1:"4,2" %}
<div class="item">
{{ forloop.counter }}
<img src="/static/{{ i.src }}">
</div>
{% endif %}
{% endfor %}
</div>
<div class="column">
{% for i in img_list %}
{% if forloop.counter|detail1:"4,3" %}
<div class="item">
{{ forloop.counter }}
<img src="/static/{{ i.src }}">
</div>
{% endif %}
{% endfor %}
</div>
<div class="column">
{% for i in img_list %}
{% if forloop.counter|detail1:"4,0" %}
<div class="item">
{{ forloop.counter }}
<img src="/static/{{ i.src }}">
</div>
{% endif %}
{% endfor %}
</div>
</div>
</body>
</html>
前端html
三.组合搜索
组合条件搜索在很多网站都可以看到,比如购物网站京东,多条件搜索查询,下面来看下low版本的组合搜索实例,展示效果如下:
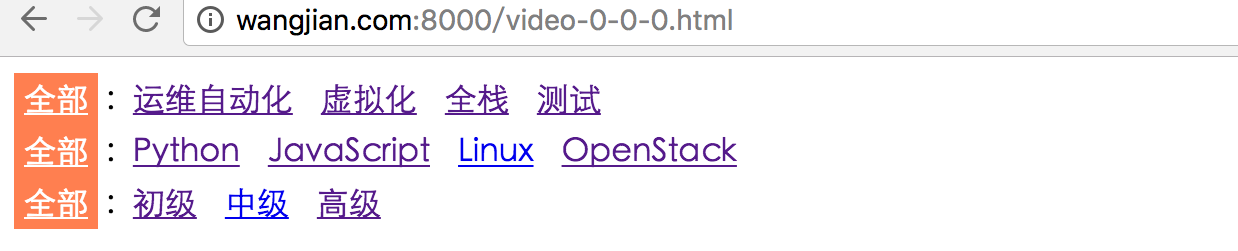
首先来看下数据库是如何设计实现的:
定义技术方向Directon,技术分类,语言Classification表,技术视频Video表,其中技术方向与技术分类进行多对多关联,技术视频对技术分类进行外键关联,视频表与技术分类无直接关联关系
具体代码如下:
class Video(models.Model):
status_choice = (
(0, u'下线'),
(1, u'上线'),
)
level_choice = (
(1, u'初级'),
(2, u'中级'),
(3, u'高级'),
)
status = models.IntegerField(verbose_name='状态', choices=status_choice, default=1)
level = models.IntegerField(verbose_name='级别', choices=level_choice, default=1)
classification = models.ForeignKey('Classification', null=True, blank=True)
weight = models.IntegerField(verbose_name='权重(按从大到小排列)', default=0)
title = models.CharField(verbose_name='标题', max_length=32)
summary = models.CharField(verbose_name='简介', max_length=32)
img = models.ImageField(verbose_name='图片', upload_to='./static/images/Video/')
href = models.CharField(verbose_name='视频地址', max_length=256)
create_date = models.DateTimeField(auto_now_add=True)
class Meta:
db_table = 'Video'
verbose_name_plural = u'视频'
def __str__(self):
return self.title
class Direction(models.Model):
weight = models.IntegerField(verbose_name='权重(按从大到小排列)', default=0)
name = models.CharField(verbose_name='名称', max_length=32)
classification = models.ManyToManyField('Classification')
class Meta:
db_table = 'Direction'
verbose_name_plural = u'方向(视频方向)'
def __str__(self):
return self.name
class Classification(models.Model):
weight = models.IntegerField(verbose_name='权重(按从大到小排列)', default=0)
name = models.CharField(verbose_name='名称', max_length=32)
class Meta:
db_table = 'Classification'
verbose_name_plural = u'分类(视频分类)'
def __str__(self):
return self.name
视频方向Direction类和视频分类Classification多对多关系,因为一个视频方向可以有多个分类,一个视频分类也可以有多个视频方向视频分类
Classification视频分类和视频Video类是一对多关系,因为一个分类肯定有好多视频
- 视频Video类中level_choice 与视频也是一对多关系,因为这个也就这三个分类,所以我选择把他放在内存里面取,因为这个时不常用的选项
URL映射关系:
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
# url(r'^student/', views.student),
url(r'^video-(?P<direction_id>\d+)-(?P<classfication_id>\d+)-(?P<level_id>\d+).html', views.video),
输入的url为:http://wangjian.com:8000/video-0-0-0.html
中间第一个0代表视频方向,第二个0代表视频分类,第三个0是视频等级,
0代表全部,然后递增,当选择运维自动化,第一个0就会变成1,当二行的python被选中,第二个0变为1
下面那些都是一样的原理
前端代码
前端HTML,有用到django的simple_tag,从总体效果图可以看出,前端主要分为两部分,选择部分和视频展示部分
1、选择部分
{% load xx %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
<style>
.condition a{
display: inline-block;
padding: 5px;
}
.condition a.active{
background-color: coral;
color: white;
}
</style>
</head>
<body>
<div class="condition">
<div>
{% all_menu current_url 1 %} :
{% for i in dList %}
{% ac1 current_url i.id i.name %}
{% endfor %}
</div>
<div>
{% all_menu current_url 2 %} :
{% for i in cList %}
{% ac2 current_url i.id i.name %}
{% endfor %}
</div>
<div>
{% all_menu current_url 3 %} :
{% for i in lList %}
{% ac3 current_url i.0 i.1 %}
{% endfor %}
</div>
</div>
</body>
</html>
中间主要是用simple_tag来做的前端代码
rom django import template
from django.utils.safestring import mark_safe register = template.Library()
@register.simple_tag
def action1(current_url, nid):
# /video-2-1-3.html
url_list = current_url.split('-')
url_list[1] = str(nid) return '-'.join(url_list) @register.simple_tag
def action2(current_url, nid):
# /video-2-1-3.html
url_list = current_url.split('-')
url_list[2] = str(nid) return '-'.join(url_list) @register.simple_tag
def action3(current_url, nid):
# /video-2-1-3.html
url_list = current_url.split('-')
url_list[3] = str(nid) + '.html' return '-'.join(url_list) @register.simple_tag
def ac1(current_url, nid, name):
# # /video-2-1-3.html
url_list = current_url.split('-')
old = url_list[1]
if old == str(nid):
temp = '<a class="active" href="%s">%s</a>'
else:
temp = '<a href="%s">%s</a>' url_list[1] = str(nid)
tag = temp %('-'.join(url_list),name) return mark_safe(tag) @register.simple_tag
def ac2(current_url, nid, name):
# # /video-2-1-3.html
url_list = current_url.split('-')
old = url_list[2]
if old == str(nid):
temp = '<a class="active" href="%s">%s</a>'
else:
temp = '<a href="%s">%s</a>' url_list[2] = str(nid)
tag = temp %('-'.join(url_list),name) return mark_safe(tag) @register.simple_tag
def ac3(current_url, nid, name):
# # /video-2-1-3.html
url_list = current_url.split('-')
old = url_list[3]
if old == str(nid) + '.html':
temp = '<a class="active" href="%s">%s</a>'
else:
temp = '<a href="%s">%s</a>' url_list[3] = str(nid) + '.html'
tag = temp %('-'.join(url_list),name) return mark_safe(tag) @register.simple_tag
def all_menu(current_url,index):
"""
获取当前url,video-1-1-2.html
:param current_url:
:param item:
:return:
"""
url_part_list = current_url.split('-')
if index == 3:
if url_part_list[index] == "0.html":
temp = "<a href='%s' class='active'>全部</a>"
else:
temp = "<a href='%s'>全部</a>" url_part_list[index] = "0.html"
else:
if url_part_list[index] == "0":
temp = "<a href='%s' class='active'>全部</a>"
else:
temp = "<a href='%s'>全部</a>" url_part_list[index] = "0" href = '-'.join(url_part_list) temp = temp % (href,)
return mark_safe(temp) @register.filter
def detail1(value,arg): """
查看余数是否等于remainder arg="1,2"
:param counter:
:param allcount:
:param remainder:
:return:
"""
allcount, remainder = arg.split(',')
allcount = int(allcount)
remainder = int(remainder)
if value%allcount == remainder:
return True
return False
相关simple_tag
2、视频展示区域
<h3>视频:</h3>
{% for item in video_list %}
<a class="item" href="{{ item.href }}">
<img src="/{{ item.img }}" width="300px" height="400px">
<p>{{ item.title }}</p>
<p>{{ item.summary }}</p>
</a>
{% endfor %}
关键来啦关键来啦,最主要的处理部分在这里,往这看,往这看,往这看,主要的事情说三遍哈
视频后台逻辑处理部分
from django.shortcuts import render
from app01 import models
# Create your views here. def video(request,**kwargs):
print(kwargs)
print(request.path_info)
# 当前请求的路径
current_url = request.path_info
# 从url中获取所有的视频方向分类id
direction_id = kwargs.get('direction_id','0')
# 获取url中的视频分类id
classfication_id = kwargs.get('classfication_id', '0')
# 从数据库获取视频时的filter条件字典
q = {}
# 方向是0
if direction_id == '0':
#从数据库中获取分类
cList = models.Classification.objects.values('id', 'name')
# 分类是0,如果视频分类id也为0,即全部分类,那就什么都不用做,因为已经全取出来了
if classfication_id == '0':
# video-0-0
pass
else:
# video-0-1
# 如果视频分类不是全部,过滤条件为视频分类id在[url中的视频分类id]
q['classification__id'] = classfication_id
else:
# 方向选择某一个方向,
# 如果分类是0
#从数据库中获取当前视频方向对象
obj = models.Direction.objects.get(id=direction_id)
#找出当前视频对象相关分类对象
temp = obj.classification.all().values('id','name')
#用lambda 函数将已经选择分类对象的id通过map方法形成列表
id_list = list(map(lambda x:x['id'],temp))
print(id_list)
#获取所有相关视频分类的id及name字段
cList = obj.classification.all().values('id','name') if classfication_id == '0':
# video-1-0
# 根据风向ID,找到所属的分类ID print(id_list)
#如果视频方向不为0,视频分类为0,过滤条件为视频分类id in [已经选择的视频分类id]
q['classification__id__in'] = id_list
else:
# video-1-1
# 当前分类如果在获取的所有分类中,则方向下的所有对应的分类显示
if int(classfication_id) in id_list:
q['classification__id'] = classfication_id
# 当前分类如果不在获取的所有分类中,则返回获取的视频方向对应的视频分类
else:
q['classification__id__in'] = id_list
url_list = current_url.split('-')
url_list[2] = "0"
current_url = '-'.join(url_list)
print(current_url)
level_id = kwargs.get('level_id',None)
if level_id != '0':
# 过滤条件增加视频等级
q['level'] = level_id
print(q) # 根据过滤条件取出相对应的视频
result = models.Video.objects.filter(**q)
#
dList = models.Direction.objects.values('id', 'name') lList = models.Video.level_choice
# level_choice = (
# (1, u'初级'),
# (2, u'中级'),
# (3, u'高级'),
# )
return render(request, 'video.html', {"dList":dList,
'cList': cList,
'lList': lList,
'current_url': current_url,
'video_list':result,
})
四.多级评论实现方法
评论树形构建思路,首先多级评论表应该具备以下类似数据结构:
1 qqq None
2 360 1
3 ali 1
4 baidu 2
5 baidu None
6 baidu None
7 baidu 6
8 baidu 5
将以上结构通过字典构造出相互关联嵌套的数据字典如下:
dic = {
"1 qqq None":{
"2 360 1": {
"4 baidu 2": {}
},
"3 ali 1": {}
},
"5 baidu None": {
"8 baidu 5": {}
},
"6 baidu None": {
"7 baidu 6": {}
}
}
那么问题来了如何从原生数据结构转换为特定数据结构的字典呢?
看上面的字典,我们能通过for循来获取他有多少层吗?当然不行,我们不知道他有多少层就没有办法进行找,或者通过while循环,最好是用递归进行一层一层的查找!
我们在前端展示的时候需要知道,那条数据是那一层的,不可能是垒下去的!因为他们是有层级关系的!
我们用后端来实现:咱们给前端返回一个字典这样是不行的,咱们在后端把层级关系建立起来~返回的时候直接返回一个完整的HTML
转换为字典之后就有层级关系了我们可以通过递归来实现了!上面再没有转换为字典的时候层级关系就不是很明确了!
在循环的过程中不断的创建字典,先建立最顶级的,然后在一层一层的建立
先通过一个简单的例子看下:
#!/usr/bin/env python
#-*- coding:utf-8 -*- data = [
(None,'A'),
('A','A1'),
('A','A1-1'),
('A1','A2'),
('A1-1','A2-3'),
('A2-3','A3-4'),
('A1','A2-2'),
('A2','A3'),
('A2-2','A3-3'),
('A3','A4'),
(None,'B'),
('B','B1'),
('B1','B2'),
('B1','B2-2'),
('B2','B3'),
(None,'C'),
('C','C1'), ] def tree_search(d_dic,parent,son):
#一层一层找,先拨第一层,一层一层往下找
for k,v in d_dic.items():
#举例来说我先遇到A,我就把A来个深度查询,A没有了在找B
if k == parent:#如果等于就找到了parent,就吧son加入到他下面
d_dic[k][son] = {} #son下面可能还有儿子
#这里找到就直接return了,你找到就直接退出就行了
return
else:
#如果没有找到,有可能还有更深的地方,的需要剥掉一层
tree_search(d_dic[k],parent,son) data_dic = {} for item in data:
# 每一个item代表两个值一个父亲一个儿子
parent,son = item
#先判断parent是否为空,如果为空他就是顶级的,直接吧他加到data_dic
if parent is None:
data_dic[son] = {} #这里如果为空,那么key就是他自己,他儿子就是一个空字典
else:
'''
如果不为空他是谁的儿子呢?举例来说A3他是A2的儿子,但是你能直接判断A3的父亲是A2你能直接判断他是否在A里面吗?你只能到第一层.key
所以咱们就得一层一层的找,我们知道A3他爹肯定在字典里了,所以就得一层一层的找,但是不能循环找,因为你不知道他有多少层,所以通过递归去找
直到找到位置
'''
tree_search(data_dic,parent,son) #因为你要一层一层找,你的把data_dic传进去,还的把parent和son传进去 for k,v in data_dic.items():
print(k,v)
执行结果:
('A', {'A1': {'A2': {'A3': {'A4': {}}}, 'A2-2': {'A3-3': {}}}, 'A1-1': {'A2-3': {'A3-4': {}}}})
('C', {'C1': {}})
('B', {'B1': {'B2-2': {}, 'B2': {'B3': {}}}})
2、前端返回
当咱们把这个字典往前端返回的时候,前端模板里是没有一个语法递归的功能的,虽然咱们的层级关系已经出来了!所以咱们需要自定义一个模板语言然后拼成一个html然后返回给前端展示!
2.1、配置前端吧数据传给simple_tag
{% extends "base.html" %}
{% build_comment_tree article.comment_set.select_related %}
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: Jason Wang from django import template
from django.utils.safestring import mark_safe
from app01.models import UserInfo
from collections import OrderedDict register = template.Library() def tree_search(d_dic,comment_obj):#这里不用传父亲和儿子了因为他是一个对象,可以直接找到父亲和儿子
for k,v_dic in d_dic.items():
if k == comment_obj.parent_comment:#如果找到
d_dic[k][comment_obj] = {}#如果找到父亲了,你的把自己存放在父亲下面,并把自己当做key,value为一个空字典
return
else:#如果找不到递归查找
tree_search(d_dic[k],comment_obj) def generate_comment_html(sub_comment_dic,margin_left_val):
#先创建一个html默认为空
html = ''
for k,v_dic in sub_comment_dic.items():#循环穿过来的字典
html += '<li class="items collapsable">'
html += '<span class="folder" style="background: None" id="comment_folder_3">'
html += "<div class='comment-R comment-R-top' style='background-color: rgb(246, 246, 246);'>"
html += "<div class='pp' style='border-top: 1px dotted '>"
html += "<a style='margin-left:"+ str(margin_left_val) + "px'" + "class='name'>"+convert(k.user_id)+"</a>"
html += "<span id='reply_id_" + str(k.article_id) + "' "+"target='" + str(k.id) + "' "+'>' + k.content + "</span>"
html += "<div class='comment-line-top' > <div class='comment-state'>" +\
"<a class='ding' lang='8678853' href='javascript:;'>" +\
"<b>顶</b>" +\
"<span class='ding-num'>[3]</span>" +\
"</a>" +\
"<a class='cai' lang='8678853' href='javascript:;'>" +\
"<b>踩</b>" +\
"<span class='cai-num'>[0]</span>" +\
"</a>" +\
"<span class='line-huifu'>|</span>" +\
"<a class='see-a' href='javascript:;' lang='13071214' linkid='8678853'>举报</a>" +\
'<span class="line-huifu">|</span>' +\
'<a class="see-a huifu-a" href="javascript:;" id="huifuBtn13071214" lang="13071214" usernick="connertt" linkid="8678853"' +\
"onclick=reply(%s,%s,'%s')>回复</a>" %(k.article_id,k.id,convert(k.user_id)) +\
'</div>' +\
'</div>'
html += "<span style='border-bottom: 1px dotted'></span>"
html += "<br>"
html += "</div>"
html += "</div>"
html += '</span>'
html += '</li>'
#上面的只是把第一层加了他可能还有儿子,所以通过递归继续加
if v_dic:
html += generate_comment_html(v_dic,margin_left_val+25)
return html @register.simple_tag
def build_comment_tree(comment_list):
"""
把评论传过来只是一个列表格式(如下),要把列别转换为字典,在把字典拼接为html
:param comment_list:
:return:
"""
comment_dic = OrderedDict()
# print(comment_list)
for comment_obj in comment_list:
# print(comment_obj)
if comment_obj.parent_comment_id is None:
comment_dic[comment_obj] = {}
else:
tree_search(comment_dic,comment_obj) margin_left = 0
# print(comment_dic.items())
html = ''
for k,v in comment_dic.items():
html += '<li class="items collapsable">'
html += '<span class="folder" style="background: None" id="comment_folder_3">'
html += "<div class='comment-R comment-R-top' style='background-color: rgb(246, 246, 246);'>"
html += "<div class='pp' style='border-top: 1px dotted '>"
#第一层的html
html += "<a class='name'>"+convert(k.user_id)+"</a>"
html += "<span id='reply_id_" + str(k.article_id) + "' "+"target='" + str(k.id) + "' "+'>' + k.content + "</span>"
html += "<div class='comment-line-top' > <div class='comment-state'>" +\
"<a class='ding' lang='8678853' href='javascript:;'>" +\
"<b>顶</b>" +\
"<span class='ding-num'>[3]</span>" +\
"</a>" +\
"<a class='cai' lang='8678853' href='javascript:;'>" +\
"<b>踩</b>" +\
"<span class='cai-num'>[0]</span>" +\
"</a>" +\
"<span class='line-huifu'>|</span>" +\
"<a class='see-a jubao' href='javascript:;' lang='13071214' linkid='8678853'>举报</a>" +\
'<span class="line-huifu">|</span>' +\
'<a class="see-a huifu-a" href="javascript:;" id="huifuBtn13071214" lang="13071214" usernick="connertt" linkid="8678853" ' +\
"onclick=reply(%s,%s,'%s')>回复</a>" %(k.article_id,k.id,convert(k.user_id)) +\
'</div>' +\
'</div>'
html += "<span style='border-bottom: 1px dotted'></span>"
html += "<br>"
html += "</div>"
html += "</div>"
html += '</span>'
html += '</li>'
#通过递归把他儿子加上
html += generate_comment_html(v,margin_left+15) print(html)
return mark_safe(html)
>>> models.UserInfo.objects.create(username='jason',pwd='56789',user_type_id='1')
<UserInfo: UserInfo object>
>>> models.UserInfo.objects.values()
<QuerySet [{'pwd': '56789', 'username': 'jason', 'id': 1, 'user_type_id': 1}]>
>>> models.UserInfo.objects.values().get(id=1)
{'pwd': '56789', 'username': 'jason', 'id': 1, 'user_type_id': 1}
>>> models.UserInfo.objects.update(pwd=F('pwd')+1)
1
>>> models.UserInfo.objects.values().get(id=1)
{'pwd': '56790', 'username': 'jason', 'id': 1, 'user_type_id': 1}
>>>
最新文章
- 一.Jmeter+Ant+Jenkins搭建持续集成接口性能自动化测试
- 使用PowerShell解三道测试开发笔试题
- C语言代写
- JAVA EE 第一阶段考试
- 几种RAID技术比较
- MATLAB r2014a 下载+安装+激活
- perl中调用cgi
- python入门之一python安装及程序运行
- Gate One——用web展示Terminal(安装)
- C++数组做参数
- UWP 圆形菜单
- (第十三周)Final Review会议
- npm常用模块
- Nextcloud私有云盘在Centos7下的部署笔记
- Android判断网络是否打开,并打开设置网络界面
- Win7/Win8安装"我们无法创建新的分区,也找不到现有的分区"的解决方法
- 用Python编写一个简单的Http Server
- js判断鼠标滚轴方向(向上或向下)
- [网站公告]1月10日1:00-7:00阿里云RDS维护会造成30秒闪断
- HOJ 13845 Atomic Computer有向无环图的动态规划