【NLP_Stanford课堂】语言模型1
2024-08-26 20:12:02
一、语言模型
旨在:给一个句子或一组词计算一个联合概率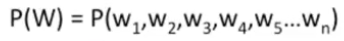
作用:
- 机器翻译:用以区分翻译结果的好坏
- 拼写校正:某一个拼错的单词是这个单词的概率更大,所以校正
- 语音识别:语音识别出来是这个句子的概率更大
- 总结或问答系统
相关任务:在原句子的基础上,计算一个新词的条件概率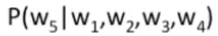 ,该概率与P(w1w2w3w4w5)息息相关。
,该概率与P(w1w2w3w4w5)息息相关。
任何一个模型计算以上两个概率的,我们都称之为语言模型LM。
二、如何计算概率
方法:依赖概率的链式规则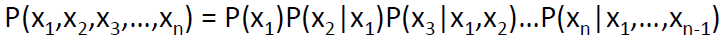
从而有:

问题:如何预估这些概率
方法一:计数和细分

但是不可能做到!
原因:句子数量过于庞大;永远不可能有足够的数据来预估这些(语料库永远不可能是完备的)
方法二:马尔可夫假设
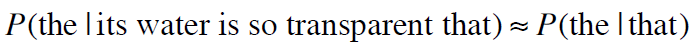
或者:
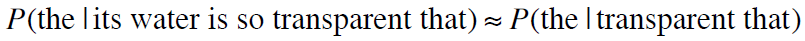
即:
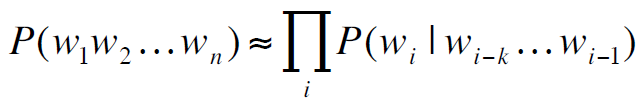
所以:
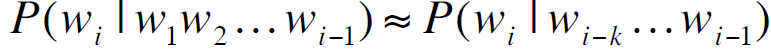
三、马尔可夫模型
1. Unigram model
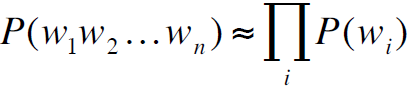
其假设词是相互独立的
2. Bigram model
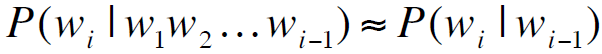
3. N-gram models
但是并不有效,因为语言本身存在长距离依存关系
比如"The computer which ......crashed" 单词crash本身其实是依赖于主语computer的,但是中间隔了一个很长的从句,在马尔可夫模型中就很难找到这样的依存关系
但是在实际应用中,发现N-gram可以一定程度上解决这个问题
四、预估N-gram概率
以bigram为例。
最大似然估计:
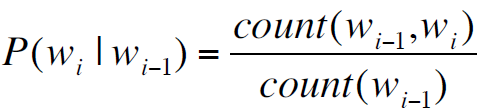 ,即,
,即,
分子表示wi紧跟着wi-1出现的计数,分母表示wi-1出现的计数
举例如下:
语料库: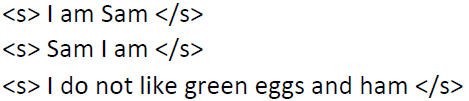
计算bigram概率:
结果: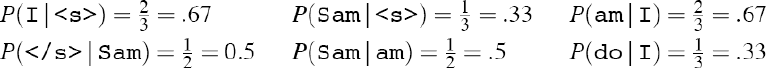
更复杂的举例如下:
一语料库中有9222个句子,这里我们只计数其中8个我们想要关注的单词
其中每个单词后面紧跟着的单词计数如下:
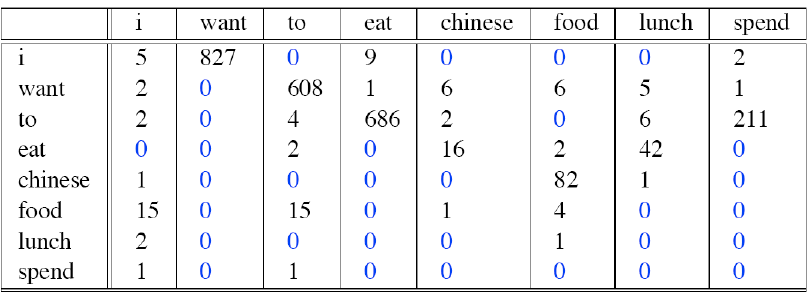
接下来我们需要做的是归一化:
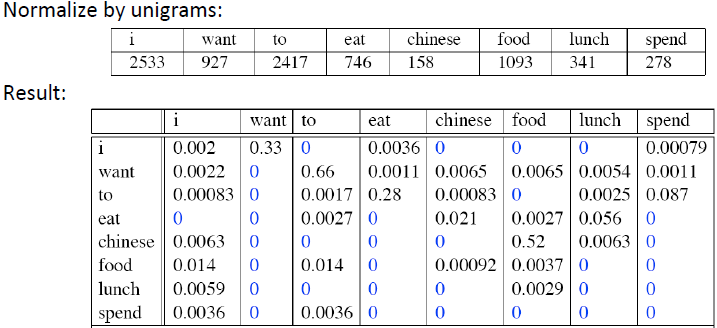
其中有些为0,是因为偶然性或者结构语法上的原因
在获得每个bigram之后,就可以预估一个句子的概率了
举例如下:

其中<s>是一个句子开始的标记,</s>是一个句子结束的标记
实际中,在计算概率时使用log,如下:
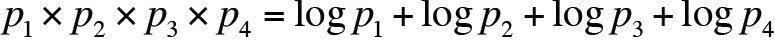
原因:
1. 避免计数下溢,多个小于0的数相乘之后可能得到的数会非常非常小,甚至接近于0
2. 使用log之后可以将乘法转换成加法,计算更快
其他语言模型:
- SRILM
- Google N-Grams
- Google Book N-Grams
最新文章
- js中json对象的深拷贝
- 【转】Eclipse中创建并运行Servlet项目
- python 拼写检查代码(怎样写一个拼写检查器)
- 百度地图API详解之事件机制,function“闭包”解决for循环和监听器冲突的问题:
- jumpserver v0.4.0 基于 CenOS7 的安装详解
- resteasy上传文件写法
- 很详细的Django入门详解
- HTML5跳转页面并传值以及localStorage的用法
- SoupUI 5.1.2(专业版)下载(含破解文件)
- Python自学:第三章 使用del语句删除元素
- iOS移动开发CoreDate讲解
- 好系统重装助手教你清理win7系统中DNS缓存
- 【IDEA&&Eclipse】4、IntelliJ IDEA上操作GitHub
- Win10系列:C#应用控件基础1
- LOJ 2737 「JOISC 2016 Day 3」电报 ——思路+基环树DP
- C/C++ typedef用法详解(真的很详细)
- EZ 2018 04 21 NOIP2018 模拟赛(十) -LoliconAutomaton的退役赛
- office 2010 正在配置Microsoft Office ...
- IOS中的网络编程详解
- 原生DOM操作vs框架虚拟DOM比较
热门文章
- 【算法笔记】B1028 人口普查
- vue脚手架初始化的项目 npm run build 无效,没有反应
- 小数据池 is 和 == ,以及再谈编码
- Linux误挂载到根目录出现问题!!!!!!!!!!!!!!!
- maven的resources插件
- my32_ error 1872 Slave failed to initialize relay log info structure from the repository
- Java基础21-构造函数之间的调用
- AutoFac之 Named and Keyed 方式注入
- 数据库~大叔通过脚本生成poco实体
- Coursera 机器学习 第9章(下) Recommender Systems 学习笔记