环境介绍
硬件环境
CPU 4 MEM 4G 磁盘 60G
软件环境
OS:centos6.5版本 64位
Hadoop:hadoop2.5.2 64位
JDK: JDK 1.8.0_91
主机配置规划
Hadoop01 172.16.1.156 (NameNode)
Hadoop02 172.16.1.157 (DataNode)
Hadoop03 172.16.1.158 (DataNode)
设置主机名
这里主机名修改不是必须条件,但是为了操作简单,建议将主机名设置一下,需要修改调整各台机器的hosts文件配置,命令如下:
如果没有足够的权限,可以切换用户为root
三台机器统一增加以下host配置:

配置免密码登录SSH
ssh-keygen -t rsa
2)将id_dsa.pub(公钥)追加到授权key中:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
3)将认证文件复制到另外两台DataNode节点上:
scp ~/.ssh/authorized_keys 172.16.1.157:~/.ssh/
scp ~/.ssh/authorized_keys 172.16.1.158:~/.ssh/
ssh hadoop02或ssh hadoop03
各节点安装JDK
(1)检查jdk版本、卸载openjdk版本
查看目前安装openjdk信息:rpm -qa|grep java

卸载以上三个文件(需要root权限,登录root权限卸载)
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
rpm -e --nodeps tzdata-java-2013g-1.el6.noarch
(2)选择版本是jdk-8u91-linux-x64.gz
(3)解压安装:
(4)重命名jdk为jdk1.8(用mv命令)
(5) 配置环境变量:vi /etc/profile加入以下三行
#JAVA_HOME
export JAVA_HOME=/home/hadoop/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH
(6)执行source /etc/profile使环境变量的配置生效
(7)执行Java –version查看jdk版本,验证是否成功
(8)将hadoop01机器上安装好JDK复制到另外两台节点上
Hadoop安装
Hadoop。
hadoop-2.5.2.tar.gz
/home/hadoop/software
解压
tar -zvxf hadoop-2.5.2.tar.gz -C /home/hadoop/
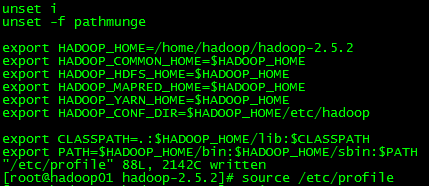
添加环境变量
vi /etc/profile,尾部添加如下
export JAVA_HOME=/home/hadoop/jdk1.8
export HADOOP_HOME=/home/hadoop/hadoop-2.5.2
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export CLASSPATH=.:$JAVA_HOME/lib:$HADOOP_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
设置环境变量立即生效
source /etc/profile
配置Hadoop文件
(1) core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-2.5.2/hadoop_tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
(2)hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:
/home/hadoop/hadoop-2.5.2
/dfs/name</value>
<description>namenode上存储hdfs元数据</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/
/dfs/data</value>
<description>datanode上数据块物理存储位置</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
注:访问namenode的
webhdfs
使用50070端口,访问datanode的webhdfs使用50075端口。要想不区分端口,直接使用namenode的IP和端口进行所有webhdfs操作,就需要在所有datanode上都设置hdfs-site.xml中dfs.webhdfs.enabled为true。
(3)mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
jobhistory是Hadoop自带一个历史服务器,记录Mapreduce历史作业。默认情况下,jobhistory没有启动,可用以下命令启动:
sbin/mr-jobhistory-daemon.sh start historyserver
(4)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8088</value>
</property>
</configuration>
(5)修改slaves文件,添加datanode节点hostname到slaves文件中
hadoop01
hadoop02
(6)
如果已经配置了JAVA_HOME环境变量,hadoop-env.sh与yarn-env.sh这两个文件不用修改,因为里面配置就是:
export JAVA_HOME=${JAVA_HOME}
如果没有配置JAVA_HOME环境变量,需要分别在hadoop-env.sh和yarn-env.sh中
添加
JAVA_HOME
运行Hadoop
格式化
启动Hadoop
start-dfs.sh
start-yarn.sh
可以用一条命令:
停止Hadoop
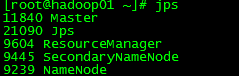
JPS查看进程
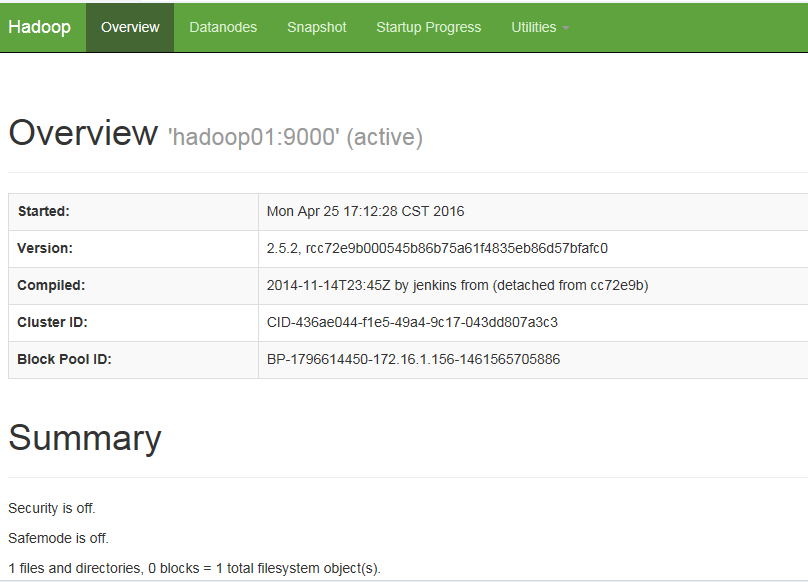
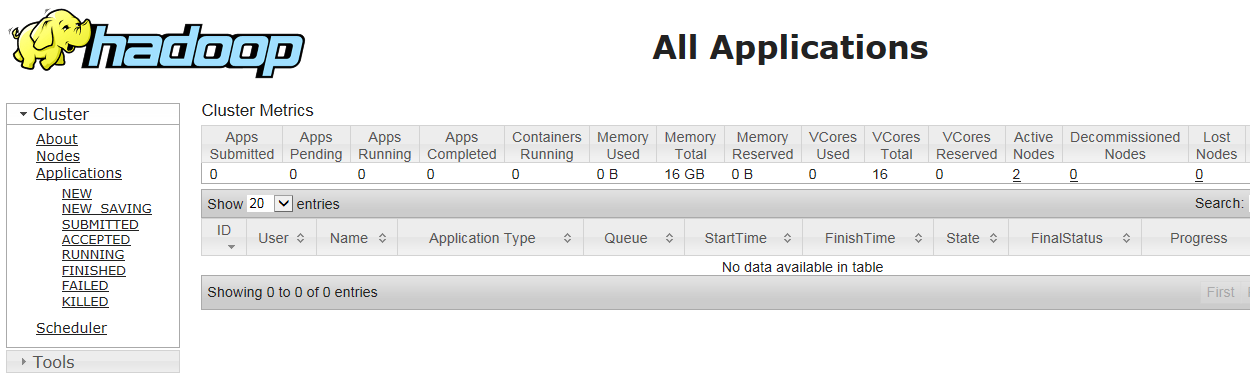
通过浏览器查看集群运行状态
http://172.16.1.156:50070
http://172.16.1.156:8088/
http://172.16.1.156:19888
jobhistory是Hadoop自带一个历史服务器,记录Mapreduce历史作业。默认情况下,jobhistory没有启动,可用以下命令启动:
sbin/mr-jobhistory-daemon.sh start historyserver
测试Hadoop
vi wordcount.txt
输入内容为:
hello you
hello me
hello everyone
2)建立目录
hadoop fs -mkdir /data/wordcount
hadoop fs –mkdir /output/
目录/data/wordcount用来存放Hadoop自带WordCount例子的数据文件,运行这个MapReduce任务结果输出到/output/wordcount目录中。
3)上传文件
hadoop fs -put wordcount.txt/data/wordcount/
4)执行wordcount程序
hadoop jar usr/local/program/Hadoop-2.5.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.1.jar wordcount /data/wordcount /output/wordcount/
5)查看结果
hadoop fs -text /output/wordcount/part-r-00000
[root@m1mydata]# hadoop fs -text /output/wordcount/part-r-00000
everyone 1
hello 3
me 1
you 1
搭建中遇到问题总结
问题一:
在配置环境变量过程可能遇到输入命令ls命令不能识别问题:
ls -bash: ls: command not found
原因:在设置环境变量时,编辑profile文件没有写正确,将export PATH=$JAVA_HOME/bin:$PATH中冒号误写成分号 ,导致在命令行下ls等命令不能够识别。
解决方案:
export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
问题二:
在主机上启动hadoop集群,然后使用jps查看主从机上进程状态,能够看到主机上的resourcemanager和各个从机上的nodemanager,但是过一段时间后,从机上的nodemanager就没有了,主机上的resourcemanager还在。
原因是防火墙处于开启状态:
注:nodemanager启动后要通过心跳机制定期与RM通信,否则RM会认为NM死掉,会停止NM服务。
service 方式
开启: service iptables start
关闭: service iptables stop
最新文章
- 安装Java的IDE Eclipse时出现java.net.SocketException,出现错误Installer failed,show.log
- SSIS excel2003文件导入列名显示为F1,F2 - FN
- JavaScript 回调函数中的 return false 问题
- JQuery思维导图
- The prefix "mx" for element "mx:WindowedApplication" is not bound.
- 解决win7资源监视器不能开启
- 屏幕分辨率与FPS
- CentOS 6.X版本升级PHP
- C++ 中字符串标准输入的学习及实验
- HTTP Header 入门详解
- SQL Server 影响dbcc checkdb的 8 种因素
- lucene 编辑距离
- Python 科学计算-介绍
- python之旅七【第七篇】面向对象之类成员
- mysql数据库中,通过mysqldump工具仅将某个库的所有表的定义进行转储
- MYSQL建表问题(转)
- JMeter脚本增强之集合点
- 使用 ECS 实例创建 FTP 站点 linux
- 【ASP.NET】必须知道的ASP.NET核心处理
- Fiori Launchpad Tile点击后跳转的调试技巧
热门文章
- Joker
- GoBelieve JS IM SDK接入备忘
- iOS之查看代码运行的时间
- 安装VMware,出现没有虚拟网络适配器的问题
- js/javascript计时器方法及使用场景
- js实现图片点击弹出放大效果
- 【CodeForces 915 C】Permute Digits(思维+模拟)
- ABAP术语-HTML
- C# register global hotkey ,onekey 注册多个全局热键以及单个全局热键
- 01 shell编程规范与变量