Openfire 性能优化
Openfire 是一个XMPP协议的IM Server。
Openfire使用mysql配合它不知所谓几乎无效的的Cache机制就注定无法支撑高并发,
所以第一步,将数据库切换为比较强一点的MongoDB。
但是MongoDB也是有问题的,在高并发时才会发现,MongoDB的锁表十分严重,
经过调查发现,MongoDB也比较坑爹,他是使用“全局锁”的,也就是说,你更新A表的时候,会锁住B表,数据更新后解锁。
所以作为实时查询数据库即使是使用MongoDB的master/slave模式依然不能胜任。
增加解决方案,缓存层,使用redis作为MongoDB的数据缓存,在访问时数据时,首先进入Cache层访问redis,如果没有,再去访问MongoDB,然后再回头填充Redis。
OK,数据源解决了,接下来确认需要在什么地方切入。
1,首先是将用户信息数据切换到MongoDB中。并停止Openfire自己的Roster服务,在管理控制台设置 xmpp.client.roster.active = false
2,AuthProvider,这里是登陆模块,可以继承接口重写一个属于自己的Provider。
重写authenticate方法,将登陆验证请求交给cache层。
3,离线信息的存储在之后也会成为负担,那么继承OfflineMessageStore类,重写属于自己的离线信息策略,将离线信息保存到Redis中。
4,重写状态更新的广播:PresenceUpdateHandler中的broadcastUpdate方法。
好了,这时候Openfire已经被修改的面目全非,但是效率已经不可同日而语了。
这时候还有一个问题,就是Openfire没有消息保障机制,也就是说,网络不稳定的时候,客户端异常断线,信息就会发送到空气中,
需要再发送信息的时候实现“握手机制”来保障信息的可靠性。不细说了,自己百度。
这时候Openfire的在线用户可以飚到6W无压力,但是死活上不去了,又被限制了。
在error.log中会发现类似 “open files too larger” 一类的错误,这些是linux系统参数:最大文件打开数。
在linux下执行ulimit -a就能观察最大的文件打开数,执行ulimit -n 350000设置为35万,然后kill掉openfire退出控制台,重新连接控制台使其生效,重新启动Openfire。
好吧,这时候用户量可以飙6W以上了。
XMPP服务器的测试工具,比较简单的可以使用tsung来实现,简单的配置,模拟成千上万的用户登陆,并且可以模拟HTTP等其他请求。
接下来就是单台服务器容量的问题了,我们服务器是Dell R710, 64G内存 16核CPU,15000转硬盘。
服务器在这种架构下在线用户数据在29W左右,几乎已经是单台Openfire封顶了。
开始考虑集群,不过Openfire的几种集群都测试过,效果不理想,有一个神马war包的插件,弄上去时好时坏,放弃。
还有一个oracle的集群插件,不过在高压下多台Openfire直接脱离集群,自己玩自己的了。。。日。
如果到了十万二十万左右的在线用户级别,就放弃掉Openfire,可以尝试使用tigase试试,或者和我们一样,自己写通讯服务器。
以下内容参考文章:http://blog.csdn.net/jinzhencs/article/details/50404574
其他设置以及优化
插件
- Subscription插件:自动同意好友请求,添加插件后在服务器设置最下面设置方式。
服务器设置
- 把没用的一些设置关掉,例如HTTP绑定等等
优化
- 修改打开最大文件数目:ulimit –n 65535
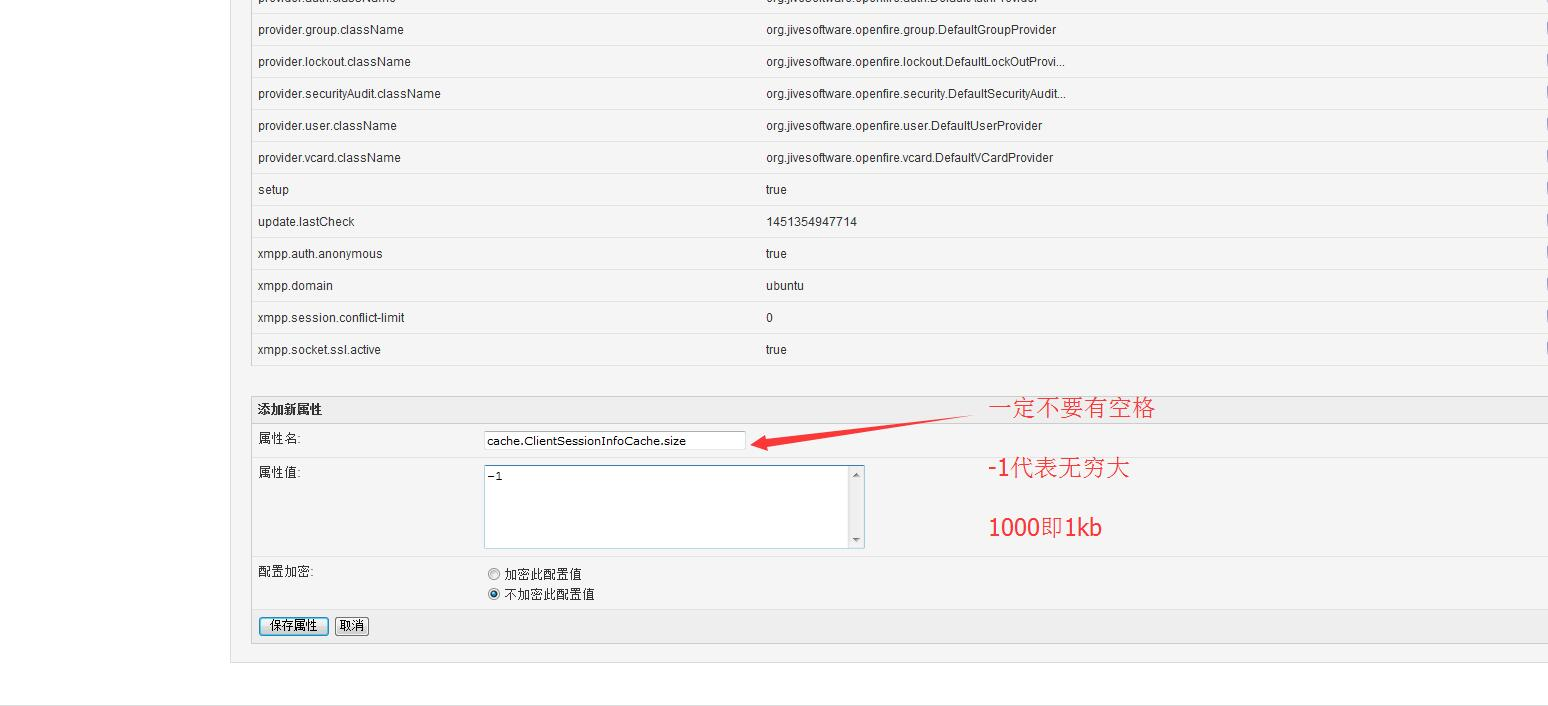
- 设置服务器缓存大小,系统属性加入:
// 注意不能有空格,特别是 size后面
// -1代表无穷大 100000000即是95M
ClientSessionInfoCache: cache.ClientSessionInfoCache.size
Roster: cache.username2roster.size
user: cache.userCache.size
group: cache.group.size
groupMeta: cache.groupMeta.size
offline message: cache.offlinemessage.size
offlinePresence: cache.offlinePresence.size
Last Activity Cache: cache.lastActivity.size
VCard: cache.VCard.size
// 以上都是高压下容易飘红的


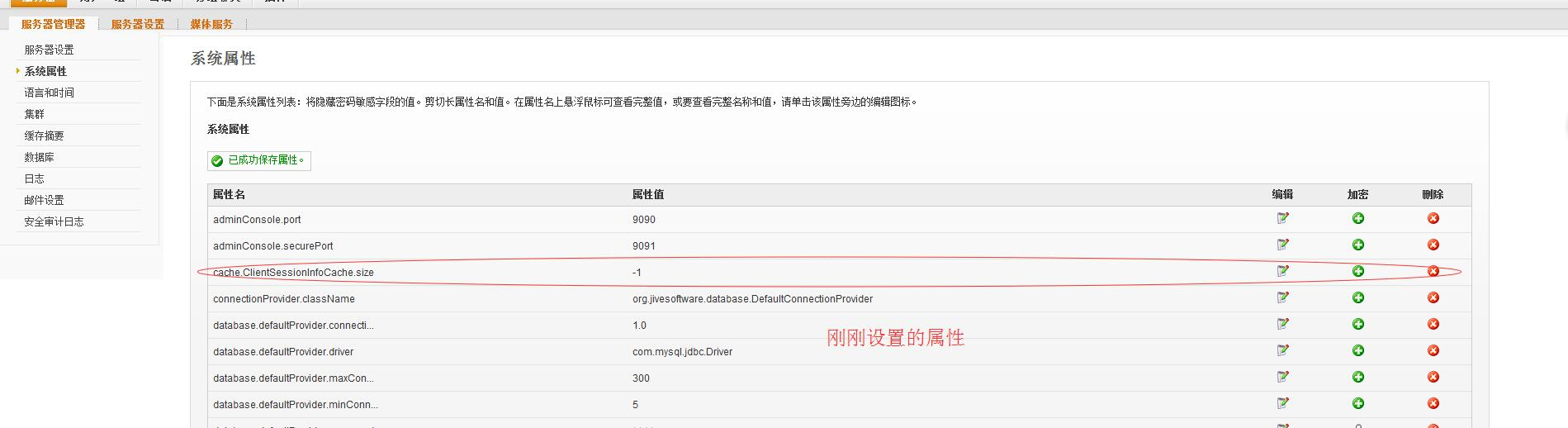
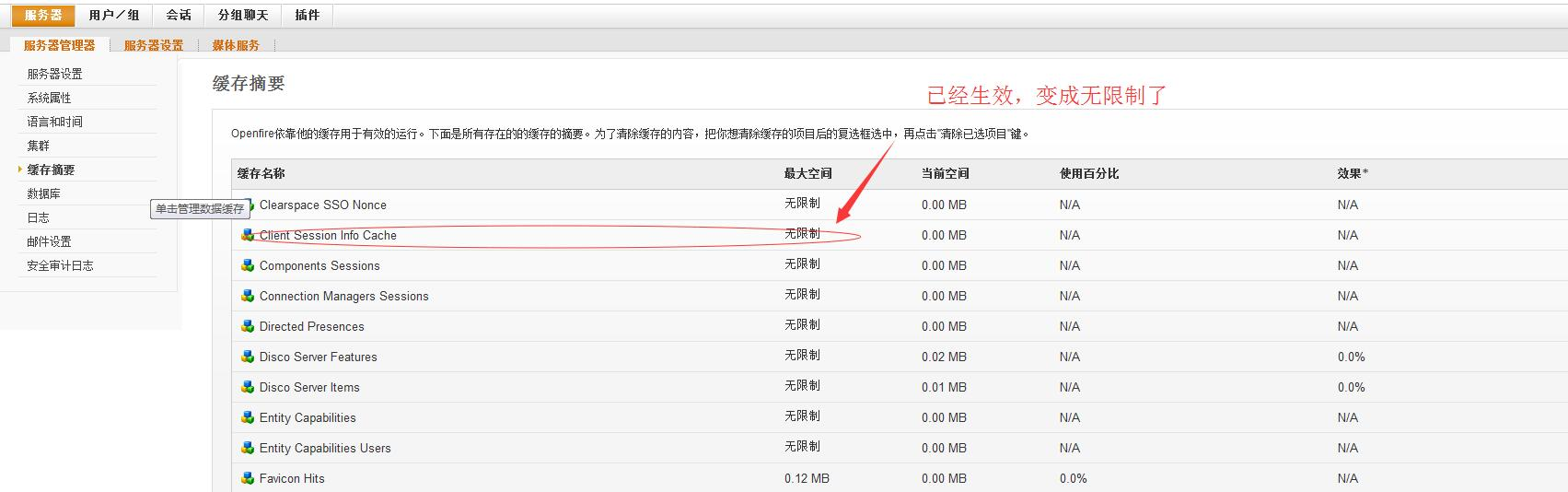
要重启openfire服务才能更新过来哦
未来需要优化的几个点:
1.加大服务器内存 20G变成150G
2.之前源码修改的是3.10.2,之后把新版本的源码下载下来重新修改,而后打包部署.
以解决3.10.2遗留的BUG(现在4.0beta版本出来了,可能过段时间会开源,改了很多bug)
3.根据需求定制openfire,即去除无用的组件,出去无用的消耗资源的一些cache或hashMap,变量之类
4.移出session,把session存入到redis中。
5.除了session,其他的很多cache(服务器缓存)全部移入redis。
openfire不使用mysql,使用redis作为数据库存储数据,再做个mysql持久化及主从就行了。
论坛有牛人说过:openfire使用了它那不知所谓的cache(其实就是HashMap),就注定无法支撑数十万连接。
(强哥说了:HashMap存储超过几万后,会有问题,好像是jdk自带的问题) 另外一个最重要的优化的方面,就是保证连上服务器的是 有用 的用户。
譬如我们服务器之前连了10W,但是其实真正用户绑定并使用XX系统的只有1W,但是10W个客户端却是连着的。 (举例子,之前我们的系统就好比进入淘宝后台自动登录旺旺,那么进淘宝多少人就有多少人登录了旺旺,但是其实真正使用旺旺的只有十分之一甚至更少,我们只需要让用户在需要旺旺对话的时候才连接服务器的话,那么瞬间服务器压力能减少 90% 这是比任何优化方案都有效的解决方法。是从业务本身去思考并优化,这个需要集思广益。)
最新文章
- Javascript作用域研究(with)
- 团队项目——站立会议DAY12
- sql server使用中遇到的问题记录
- Html-Css-iframe的自适应高度方案
- html5 视频播放
- 网站图片优化-解码JPEG
- ASP.NET 批量更新
- 过滤字段中HTML标签
- EF 更新指定的字段
- PC问题-使用BAT方法设置IP地址
- 辗转相除法_欧几里得算法_java的实现(求最大公约数)
- 外键约束列并没有导致大量建筑指数library cache pin/library cache lock
- [读书笔记]python3.5实现socket通讯(TCP)
- 回文质数 Prime Palindromes
- java程序使用memcached
- canvas雪花
- frp 初探
- yansir的原生js库
- 查看局域网指定IP的电脑名
- The Applications of RT-Thread RTOS