elasticsearch-cluster shards
elasticsearch-cluster:
Windows下本地测试用
创建集群就要给集群起名,修改 elasticsearch.yml文件。
cluster.name: es_test //集群名 node.name: node-1 //节点名多个节点名设置不一样node.master: true //是否可为主节点,多个为true时,第一个启动的就为主节点,当主节点宕机时,其它的会自动升级为主节点。network.host: 192.168.201.105 //可通过访问的ip名 http.port: 9200 //http 端口 对外 transport.tcp.port: 9300 //tcp 端口 对内 discovery.zen.ping.unicast.hosts: ["192.168.201.105:9300", "192.168.201.105:9600"] //集群tcp ip:port discovery.zen.minimum_master_nodes: 2 //集群master 节点
修改内存文件jvm.options
-Xms2g -Xmx2g
修改另一个elasticsearch的yml文件,依照上面的格式,cluster名一致。node名往下排。
注意:yml文件中 [name]: [value] 一定要有一个空格在冒号之后,不然不被识别。
这时候启动两个elasticsearch.bat 就形成了集群。
集群操作:
集群
GET _nodes/[nodeId] //获取节点信息GET _nodes/_local //本地节点信息GET _nodes/[ip] //指定ip节点信息
GET /_nodes/stats // 节点统计get /_nodes/hot_threads //节点热线程
GET _cluster/health //查看集群GET _cluster/state //详细集群状况信息GET _cluster/stats //集群统计信息
GET _cluster/pending_tasks //正在等待的任务(新建索引,分配碎片,刷新等)
POST /_cluster/reroute // 重新路由分配分片位置
POST /_cluster/reroute
{
"commands" : [
{
"move" : {
"index" : "myindex2", "shard" : 1,
"from_node" : "node-2", "to_node" : "node-1"
}
},
{
"allocate_replica" : {
"index" : "myindex2", "shard" : 1,
"node" : "node-2"
}
}
]
}
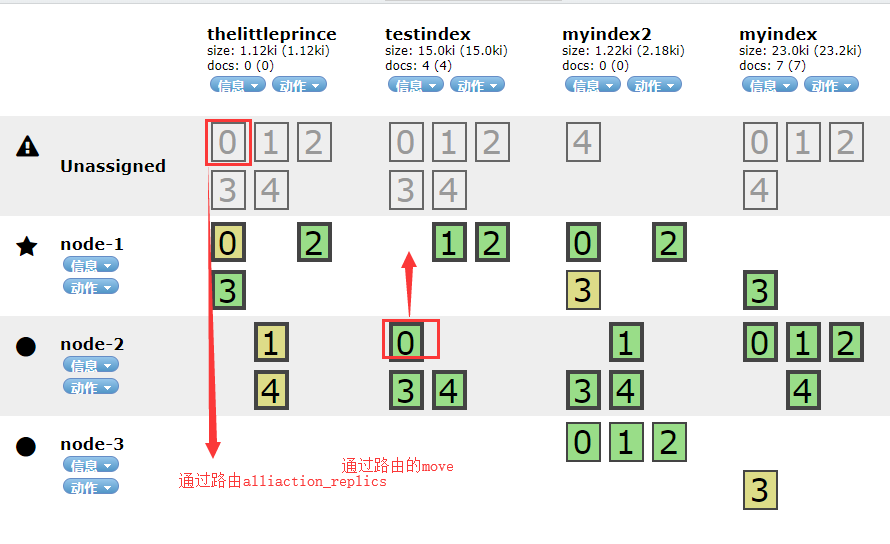
集群后,我们在查找nodes和sharp时会变的很难。不过用_cat可以让我们轻易的看懂这些。
GET _cat/shards/[myindex2] //查看分片 GET /_cat/master?v //查看主数据 GET /_cat/master?help //查看主数据帮助 GET /_cat/nodes?h=ip,port,heapPercent,name //查看节点 GET /_cat/indices //查看index GET /_cat/templates //查看模板
我们用head时可以看到有时我们的集群状况为 yellow,说明不健康。
用命令 get /cluster/health 也可以看到状况。
问题一般是有碎片有问题。我们可通过查找这些indices发现到底是哪个出的问题
get _cat/indices

然后再查看index的哪个碎片有问题。
GET _cat/shards/myindex2
参考文章
https://blog.csdn.net/laoyang360/article/details/78443006
https://www.cnblogs.com/o-andy-o/p/5067184.html
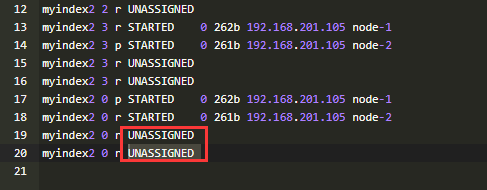
GET _cat/shards?h=index,shard,prirep,state,unassigned.reason
)INDEX_CREATED:由于创建索引的API导致未分配。 )CLUSTER_RECOVERED :由于完全集群恢复导致未分配。 )INDEX_REOPENED :由于打开open或关闭close一个索引导致未分配。 )DANGLING_INDEX_IMPORTED :由于导入dangling索引的结果导致未分配。 )NEW_INDEX_RESTORED :由于恢复到新索引导致未分配。 )EXISTING_INDEX_RESTORED :由于恢复到已关闭的索引导致未分配。 )REPLICA_ADDED:由于显式添加副本分片导致未分配。 )ALLOCATION_FAILED :由于分片分配失败导致未分配。 )NODE_LEFT :由于承载该分片的节点离开集群导致未分配。 )REINITIALIZED :由于当分片从开始移动到初始化时导致未分配(例如,使用影子shadow副本分片)。 )REROUTE_CANCELLED :作为显式取消重新路由命令的结果取消分配。 )REALLOCATED_REPLICA :确定更好的副本位置被标定使用,导致现有的副本分配被取消,出现未分配。
GET /_cluster/allocation/explain //可快速查找未分配的分片的原因
2)CLUSTER_RECOVERED的原因是副分片的数量过多,没法分配到别的地方。如下图所示
myindex2 除非再添加两个从节点,这样就可以分配这些多余的节点。
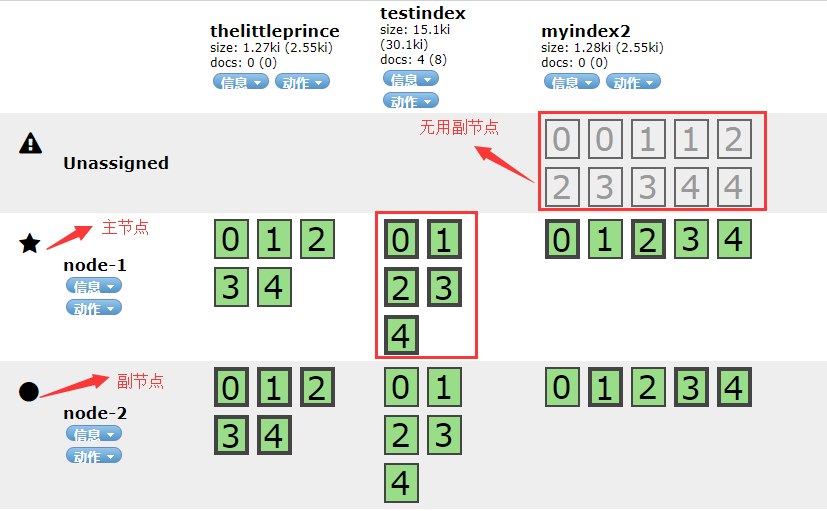
对于多余的节点我们可以清除掉,也可以扩张副节点。
PUT /myindex2/_settings
{
"number_of_replicas" : 1
}
参考文章: https://blog.csdn.net/qq_34021712/article/details/79330028
最新文章
- C#中的WebBrowser控件的使用
- nginx访问不了zabbix安装配置界面
- sublime使用小技巧——自动保存后缀名与自动匹配语法
- linux bash 笔记
- BZOJ1864[ZJOI2006]三色二叉树[树形DP]
- mysql小误区关于set global sql_slave_skip_counter=N命令
- tomcat的安装
- Android ViewDragHelper源码解析
- CentOS7安装Zabbix
- LeetCode OJ 35. Search Insert Position
- 一个初学者的辛酸路程-Python基础-3
- (转载)Java多线程的监控分析工具(VisualVM)
- ubuntu配置小飞机
- Codeforces Round #502 (in memory of Leopoldo Taravilse, Div. 1 + Div. 2)
- gflags命令行参数解析
- 优化 --cache
- Entity Framework定义外键,限制通过migration命令自动更改字段名称
- caffe深度学习进行迭代的时候loss曲线开始震荡原因
- RBAC简介
- day72