大数据 - hadoop基础概念 - HDFS
Hadoop之HDFS的概念及用法
1、概念介绍
Hadoop是Apache旗下的一个项目。他由HDFS、MapReduce、Hive、HBase和ZooKeeper等成员组成。
HDFS是一个高度容错的分布式文件系统。他能够提高吞吐量的数据访问,适合存储海量的大文件。
HDFS由四部分构成:HDFS client、NameNode、DataNode、Secondary NameNode。
2、NameNode
用于维护集群内元数据,也就是保存文件存储位置,集群存储方式为一个大文件存储在多个服务器中,而且为了维护健壮性,一个文件有多个备份,这些备份位置都需要存储在NameNode中。
。。。待编辑
a
sdf
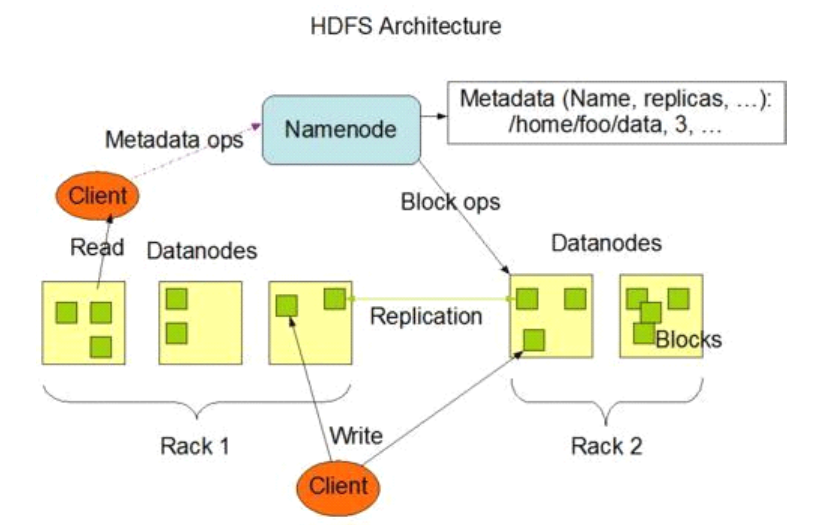
2、操作(此版本为Hadoop2.7,网上说的另一种editlog和fsimage的存储方式为更早版本)
a) 启动HDFS
从fsimage文件中读取元数据信息到内存中。
b) 读文件
1. 扫描HDFS中的元素据信息。客户端访问NameNode,NameNode把DataNode存放数据的位置等信息(存储的元数据信息),从内存中取来。
2. 客户端下载文件。客户端根据NameNode提供的元数据信息,与DataNode简历RPC通信,进行IO操作。
c) 写文件
1. 客户端与NameNode建立通信。判断存储空间的剩余量,判断所存放的文件的存放分布方式。
2. NameNode元数据信息落盘。生成一个editlog文件,保存元数据信息和元数据的操作。
3. 客户端与DadaNode建立通信。进行IO操作
d) NameNode数据固化
NameNode在空闲的时候,会把editlog中的元数据信息和操作信息,合并到fsimage(二进制信息,读写快速)文件中。
每次HDFS启动时,NameNode都会把未合并到fsimage中的数据信息,合并过去。
SecondartNameNode通过RPC通信,把editlog中的元数据信息和操作信息,合并到fsimage文件中,并推送给NameNode。
最新文章
- 【网络】VPN
- javascript eval函数解析json数据时为什加上圆括号eval("("+data+")")
- 在CentOS 6.4中编译安装gcc 4.8.1
- Selenium Grid Configuration
- CSS语法与用法小字典
- 20145129 《Java程序设计》第4周学习总结
- 剑指Offer35 两个链表第一个公共结点
- android service总结
- win2003 sp2+iis 6.0上部署.net 2.0和.net 4.0网站的方法
- Codeforces Round #313 A Currency System in Geraldion
- 关于knob.js进度插件的使用
- jsp提交表单问题
- 【JAVAWEB学习笔记】05_jQuery基础
- ssm maven spring AOP读写分离
- Linux之vi编辑器
- linux系统下saltstack的安装和配置
- jsp (2)
- Learning-Python【23】:面向对象三大特性
- TI 开发板安装USB转串口驱动
- [Error] 'exit' was not declared in this scope的解决方法
热门文章
- 利用window.name+iframe跨域获取接口数据
- LARS 最小角回归算法简介
- 学习笔记(一)HTML基础
- Python----unittest discover()方法与执行顺序
- python----数据驱动@ddt.file_data结合yaml文件的使用
- 磁盘当前目录下存在文件 c1.txt,其中存放了一段英文文字。请编程实现将c1.txt中英文文字全部转换为答谢字母,并保存到c2.txt中。要求:c2.txt文件前面保存的是c1.txt文案中的原始文字,后面紧跟着的是转换后的文字
- React 的组件与 this.props对象
- Java获取本地IP地址和主机名
- APP下载在微信无法打开 该如何处理
- SharePoint CU、Hotfix和SP版本的区别