python3乱码问题:接口返回数据中文乱码问题解决
2024-10-19 12:00:00
昨天测试接口出现有一个接口中文乱码问题,现象:
1 浏览器请求返回显示正常
2 用代码请求接口返回数据中文显示乱码
3 使用的python3,python3默认unicode编码,中文都是可以正常显示的。直接打印中文,其他接口中的中文都正常
百思不得其解,跟开发确认接口编码方式 ,也是是utf-8. 跟其他接口一样
折腾蛮久,最后的解决思路:
1 把浏览器返回的中文进行utf-8加密
2 对比步骤1的加密串 与 乱码的区别,发现两者的字节码是一样的,只是显示形式不同,一个是b'xxx',另一个‘xxx’。终于找到了解决方式
#-*-coding:utf-8 -*-
'''
dinghanhua
2018-11-09
解决接口返回数据乱码问题
现象:浏览器请求接口数据正常,
python3请求接口,返回数据中文显示乱码。
对比中文utf-8编码和接口返回数据,发现返回数据里字节码前没有加上b
''' '''中文utf-8编码,再解码'''
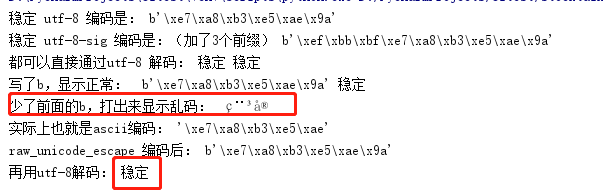
str = '稳定'
print('稳定 utf-8 编码是:',str.encode('utf-8'))
print('稳定 utf-8-sig 编码是:(加了3个前缀)',str.encode('utf-8-sig'))
print('都可以直接通过utf-8 解码:',b'\xe7\xa8\xb3\xe5\xae\x9a'.decode('utf-8'),
b'\xef\xbb\xbf\xe7\xa8\xb3\xe5\xae\x9a'.decode('utf-8')) '''utf-8编码串拷出来为啥显示乱码'''
str = b'\xe7\xa8\xb3\xe5\xae\x9a'
print('写了b,显示正常: ',str,str.decode('utf-8')) str_without_b = '\xe7\xa8\xb3\xe5\xae\x9a'
print('少了前面的b,打出来显示乱码: ', str_without_b)
print('实际上也就是ascii编码:',ascii('稳å®')) '''问题解决方式:用raw_unicode_escape编码'''
str = str_without_b.encode('raw_unicode_escape')
print('raw_unicode_escape 编码后:',str)
print('再用utf-8解码:',str.decode('utf-8'))
the end!
最新文章
- 页面内容排序插件jSort的使用
- Redis菜鸟汇总
- UILabel 的高度根据文字内容调整
- mysql和oracle 分页查询(转)
- 白书 4.1.2 模运算的世界 P291
- vim替换及多行注释命令
- 兼容iOS 10 资料整理笔记-b
- 一篇关于学C++的感想(拿来与大家分享)
- Codeblocks + opencv + Cmake + minGW 环境搭建(一劳永逸版)
- Objective-C的反射
- mysql双机热备的配置步骤
- web学习:Spring2.5+Hibernate3.3+Struts1.3整合小例子
- Python ---------- Tensorflow (二)学习率
- 坑爹的file_exists
- 【Python】 list & dict & str
- c++中的回调
- Metasploit Framework(8)后渗透测试(一)
- Kali学习笔记8:四层发现
- confluence 5.8.6升级到5.10.1
- 机器学习技法笔记:10 Random Forest