MySQL-简要说明
分类
安装发展顺序分为:
- 网状型数据库
- 层次型数据库
- 关系型数据库
- 面向对象数据库
主流:关系型数据库
关系型数据库
事务transaction:
多个操作被当作一个整体对待
• ACID:
A :原子性
C :一致性
I :隔离性
D:持久性
实体Entity:
• 客观存在并可以相互区分的客观事物或抽象事件称为实体。
属性:
• 实体所具有的特征或性质
联系:
• 联系是数据之间的关联集合,是客观存在的应用语义链
联系的类型
• 一对一联系(1:1)
• 一对多联系(1:n)
• 多对多联系(m:n)
数据三要素
• 数据结构
• 数据的操作
• 数据的约束条件
约束:constraint
表中的数据要遵守的限制
• 主键:一个或多个字段的组合,填入的数据必须能在本表中唯一标识本行;必须提供数据,即NOT NULL,一个表只能有一个
• 惟一键:一个或多个字段的组合,填入的数据必须能在本表中唯一标识本行;允许为NULL,一个表可以存在多个
• 外键:一个表中的某字段可填入的数据取决于另一个表的主键或唯一键已有的数据
• 检查:字段值在一定范围内
索引:
• 将表中的一个或多个字段中的数据复制一份另存,并且此些需要按特定次序排序存储
关系型数据库的常见组件
• 数据库:database
• 表:table
行:row
列:column
• 索引:index
• 视图:view
• 用户:user
• 权限:privilege
• 存储过程:procedure,无返回值
• 存储函数:function,有返回值
• 触发器:trigger
• 事件调度器:event scheduler,任务计划
数据库对象
• 数据库的组件(对象):
数据库、表、索引、视图、用户、存储过程、函数、触发器、事件调度器等
• 命名规则:
必须以字母开头
可包括数字和三个特殊字符(# _ $)
不要使用MySQL的保留字
同一database(Schema)下的对象不能同名
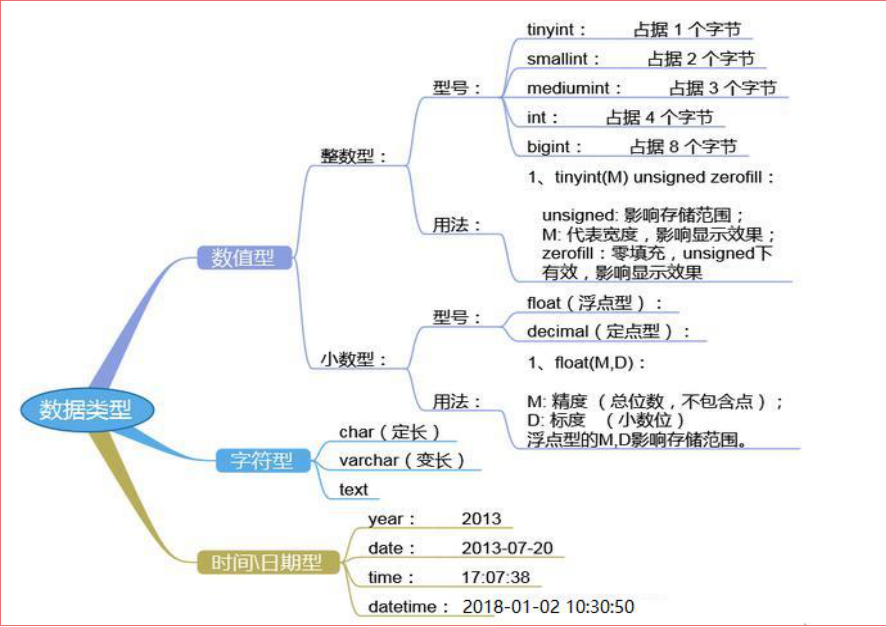
数据类型
MySql支持多种列类型:
• 数值类型
• 日期/时间类型
• 字符串(字符)类型
选择正确的数据类型对于获得高性能至关重要,三大原则:
• 更小的通常更好,尽量使用可正确存储数据的最小数据类型
• 简单就好,简单数据类型的操作通常需要更少的CPU周期
• 尽量避免NULL,包含为NULL的列,对MySQL更难优化
修饰符
所有类型:
• NULL 数据列可包含NULL值
• NOT NULL 数据列不允许包含NULL值
• DEFAULT 默认值
• PRIMARY KEY 主键
• UNIQUE KEY 唯一键
• CHARACTER SET name 指定一个字符集
数值型:
• AUTO_INCREMENT 自动递增,适用于整数类型
• UNSIGNED 无符号
SQL语句分类
• DDL: Data Defination Language 数据定义语言
CREATE,DROP,ALTER
• DML: Data Manipulation Language 数据操纵语言
INSERT,DELETE,UPDATE,SELECT
• DCL:Data Control Language 数据控制语言
GRANT,REVOKE,COMMIT,ROLLBACK
• DQL:Data Query Language 数据查询语言
SELECT
DML语句
DML: INSERT, DELETE, UPDATE(增删改)
INSERT:
• 一次插入一行或多行数据
UPDATE:
• 注意:一定要有限制条件,否则将修改所有行的指定字段
• 限制条件:
WHERE
LIMIT
DELETE:
• 注意:一定要有限制条件,否则将清空表中的所有数据
• 限制条件:
WHERE
LIMIT
多表查询
• 交叉连接:笛卡尔乘积
• 内连接:
等值连接:让表之间的字段以“等值”建立连接关系;
不等值连接
自然连接:去掉重复列的等值连接
自连接
• 外连接:
左外连接:
FROM tb1 LEFT JOIN tb2 ON tb1.col=tb2.col
右外连接
FROM tb1 RIGHT JOIN tb2 ON tb1.col=tb2.col
子查询:
• 在查询语句嵌套着查询语句,性能较差
• 基于某语句的查询结果再次进行的查询
视图
视图:VIEW,虚表,保存有实表的查询结果
创建方法:
CREATE VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
查看视图定义:
SHOW CREATE VIEW view_name
删除视图:
DROP VIEW [IF EXISTS]
view_name [, view_name] ...
[RESTRICT | CASCADE]
视图中的数据事实上存储于“基表”中,因此,其修改操作也会针对基表实现;
其修改操作受基表限制
函数
系统函数和自定义函数
自定义函数 (user-defined function UDF)
保存在mysql.proc表中
创建UDF:
CREATE [AGGREGATE] FUNCTION function_name(parameter_name
type,[parameter_name type,...])
RETURNS {STRING|INTEGER|REAL}
runtime_body
说明:
• 参数可以有多个,也可以没有参数
• 必须有且只有一个返回值
查看函数列表:
SHOW FUNCTION STATUS;
查看函数定义:
SHOW CREATE FUNCTION function_name
删除UDF:
DROP FUNCTION function_name
调用自定义函数语法:
SELECT function_name(parameter_value,...)
存储过程
存储过程保存在mysql.proc表中
创建存储过程:
CREATE PROCEDURE sp_name ([ proc_parameter [,proc_parameter ...]])
routime_body• 其中:proc_parameter : [IN|OUT|INOUT] parameter_name type
• 其中IN表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出;
param_name表示参数名称;type表示参数的类型
查看存储过程列表:
SHOW PROCEDURE STATUS
查看存储过程定义:
SHOW CREATE PROCEDURE sp_name
调用存储过程:
CALL sp_name ([ proc_parameter [,proc_parameter ...]])
CALL sp_name说明:当无参时,可以省略"()",当有参数时,不可省略"()”
存储过程修改:
• ALTER语句修改存储过程只能修改存储过程的注释等无关紧要的东西,不能修改
• 存储过程体,所以要修改存储过程,方法就是删除重建
删除存储过程:
DROP PROCEDURE [IF EXISTS] sp_name
存储过程优势:
• 存储过程把经常使用的SQL语句或业务逻辑封装起来,预编译保存在数据库中,
• 当需要时从数据库中直接调用,省去了编译的过程
• 提高了运行速度
• 同时降低网络数据传输量
存储过程与自定义函数的区别:
• 存储过程实现的过程要复杂一些,而函数的针对性较强
• 存储过程可以有多个返回值,而自定义函数只有一个返回值
• 存储过程一般独立的来执行,而函数往往是作为其他SQL语句的一部分来使用
流程控制
存储过程和函数中可以使用流程控制来控制语句的执行
流程控制:
• IF:用来进行条件判断。根据是否满足条件,执行不同语句
• CASE:用来进行条件判断,可实现比IF语句更复杂的条件判断
• LOOP:重复执行特定的语句,实现一个简单的循环
• LEAVE:用于跳出循环控制
• ITERATE:跳出本次循环,然后直接进入下一次循环
• REPEAT:有条件控制的循环语句。当满足特定条件时,就会跳出循环语句
• WHILE:有条件控制的循环语句
触发器
触发器的执行不是由程序调用,也不是由手工启动,而是由事件来触发、激活从而实现执行
创建触发器:
CREATE
[DEFINER = { user | CURRENT_USER }]
TRIGGER trigger_name
trigger_time trigger_event
ON tbl_name FOR EACH ROW
trigger_body说明:
• trigger_name:触发器的名称
• trigger_time:{ BEFORE | AFTER },表示在事件之前或之后触发
• trigger_event::{ INSERT |UPDATE | DELETE },触发的具体事件
• tbl_name:该触发器作用在表名
查看触发器:
SHOW TRIGGERS
删除触发器:
DROP TRIGGER trigger_name;
Mysql客户端
mysql客户端可用选项:
-A, --no-auto-rehash 禁止补全
-u, --user= 用户名,默认为root
-h, --host= 服务器主机,默认为localhost
-p, --passowrd= 用户密码,建议使用-p,默认为空密码
-P, --port= 服务器端口
-S, --socket= 指定连接socket文件路径
-D, --database= 指定默认数据库
-C, –compress 启用压缩
-e “SQL“ 执行SQL命令
-V, –version 显示版本
-v –verbose 显示详细信息
--print-defaults 获取程序默认使用的配置
DML语言 (增删改)
DML:INSERT(增加),DELETE(删除),UPDATE(修改)
//默认是直接修改物理数据的,无法撤回
为了防止修改表的时候一不小心全改了,我们要加一个安全机制
cd /etc/my.cnf.d/
vim /mysql-clients.cnf
在mysql项加上safe-updates
加上后,我们在更改的时候不加where语句是不能运行的
//也可用 mysql -U
//直接定义别名就可
待续…
最新文章
- Android之消息机制Handler,Looper,Message解析
- nginx 启动、重启、关闭
- Azure Blob
- 泛型,动态创建List<T> (转摘)
- hql 关联查询
- C#简单一句代码,实现pictureBox的照片另存为磁盘文件不出错
- Git客户端(Windows系统)的使用(Putty)(转)
- P1345 [USACO5.4]奶牛的电信Telecowmunication
- 用javah 导出类的头文件, 常见的错误及正确的使用方法
- Spring实战拆书--SpringBean
- Timer定时执行
- libpcap 库使用(一)
- JS实现PC、Android、IOS端的点击按钮复制内容功能
- df值自由度学习[转载]
- Data Center Drama 欧拉回路的应用
- Three Pieces CodeForces - 1065D (BFS)
- 【转】WCF入门教程二[WCF应用的通信过程]
- flask中Flask()和Blueprint() flask中的g、add_url_rule、send_from_directory、static_url_path、static_folder的用法
- javaweb(二十三)——jsp自定义标签开发入门
- CentOS 6.5 下安装 Sun JDK 1.7