KafkaProducer源码分析
Kafka常用术语
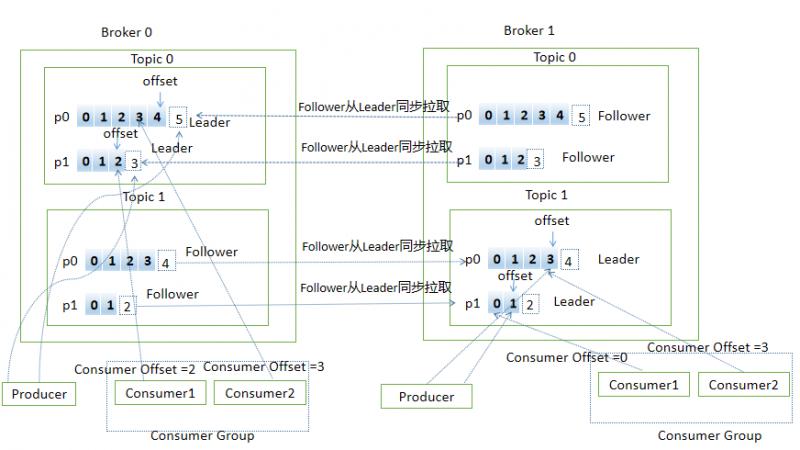
Broker:Kafka的服务端即Kafka实例,Kafka集群由一个或多个Broker组成,主要负责接收和处理客户端的请求
Topic:主题,Kafka承载消息的逻辑容器,每条发布到Kafka的消息都有对应的逻辑容器,工作中多用于区分业务
Partition:分区,是物理概念,代表有序不变的消息序列,每个Topic由一个或多个Partion组成
Replica:副本,Kafka中同一条消息拷贝到多个地方做数据冗余,这些地方就是副本,副本分为Leader和Follower,角色不同作用不同,副本是对Partition而言的,每个分区可配置多个副本来实现高可用
Record:消息,Kafka处理的对象
Offset:消息位移,分区中每条消息的位置信息,是单调递增且不变的值
Producer:生产者,向主题发送新消息的应用程序
Consumer:消费者,从主题订阅新消息的应用程序
Consumer Offset:消费者位移,记录消费者的消费进度,每个消费者都有自己的消费者位移
Consumer Group:消费者组,多个消费者组成一个消费者组,同时消费多个分区来实现高可用(组内消费者的个数不能多于分区个数以免浪费资源)
Reblance:重平衡,消费组内消费者实例数量变更后,其他消费者实例自动重新分配订阅主题分区的过程
下面用一张图展示上面提到的部分概念(用PPT画的图,太费劲了,画了老半天,有好用的画图工具欢迎推荐)
消息生产流程
先来个KafkaProducer的小demo
public static void main(String[] args) throws ExecutionException, InterruptedException {
if (args.length != 2) {
throw new IllegalArgumentException("usage: com.ding.KafkaProducerDemo bootstrap-servers topic-name");
}
Properties props = new Properties();
// kafka服务器ip和端口,多个用逗号分割
props.put("bootstrap.servers", args[0]);
// 确认信号配置
// ack=0 代表producer端不需要等待确认信号,可用性最低
// ack=1 等待至少一个leader成功把消息写到log中,不保证follower写入成功,如果leader宕机同时follower没有把数据写入成功
// 消息丢失
// ack=all leader需要等待所有follower成功备份,可用性最高
props.put("ack", "all");
// 重试次数
props.put("retries", 0);
// 批处理消息的大小,批处理可以增加吞吐量
props.put("batch.size", 16384);
// 延迟发送消息的时间
props.put("linger.ms", 1);
// 用来换出数据的内存大小
props.put("buffer.memory", 33554432);
// key 序列化方式
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value 序列化方式
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建KafkaProducer对象,创建时会启动Sender线程
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
// 往RecordAccumulator中写消息
Future<RecordMetadata> result = producer.send(new ProducerRecord<>(args[1], Integer.toString(i), Integer.toString(i)));
RecordMetadata rm = result.get();
System.out.println("topic: " + rm.topic() + ", partition: " + rm.partition() + ", offset: " + rm.offset());
}
producer.close();
}
实例化
KafkaProducer构造方法主要是根据配置文件进行一些实例化操作
1.解析clientId,若没有配置则由是producer-递增的数字
2.解析并实例化分区器partitioner,可以实现自己的partitioner,比如根据key分区,可以保证相同key分到同一个分区,对保证顺序很有用。若没有指定分区规则,采用默认的规则(消息有key,对key做hash,然后对可用分区取模;若没有key,用随机数对可用分区取模【没有key的时候说随机数对可用分区取模不准确,counter值初始值是随机的,但后面都是递增的,所以可以算到roundrobin】)
3.解析key、value的序列化方式并实例化
4.解析并实例化拦截器
5.解析并实例化RecordAccumulator,主要用于存放消息(KafkaProducer主线程往RecordAccumulator中写消息,Sender线程从RecordAccumulator中读消息并发送到Kafka中)
6.解析Broker地址
7.创建一个Sender线程并启动
...
this.sender = newSender(logContext, kafkaClient, this.metadata);
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
...
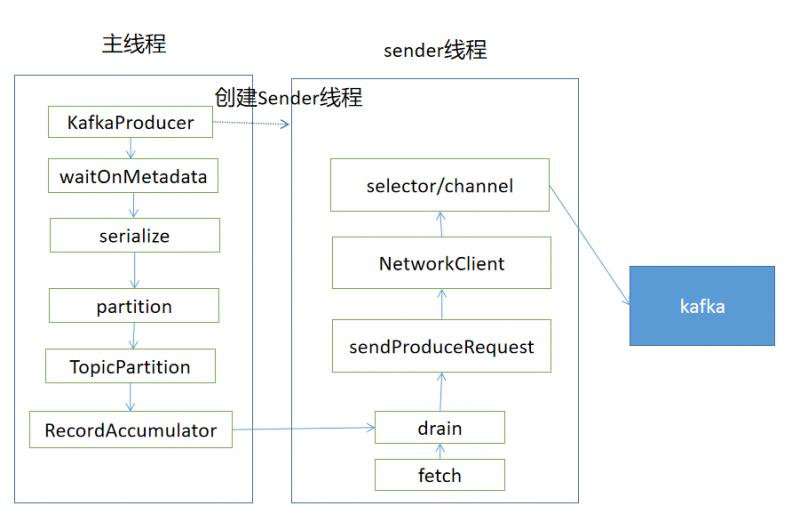
消息发送流程
消息的发送入口是KafkaProducer.send方法,主要过程如下
KafkaProducer.send
KafkaProducer.doSend
// 获取集群信息
KafkaProducer.waitOnMetadata
// key/value序列化
key\value serialize
// 分区
KafkaProducer.partion
// 创建TopciPartion对象,记录消息的topic和partion信息
TopicPartition
// 写入消息
RecordAccumulator.applend
// 唤醒Sender线程
Sender.wakeup
RecordAccumulator
RecordAccumulator是消息队列用于缓存消息,根据TopicPartition对消息分组
重点看下RecordAccumulator.applend追加消息的流程
// 记录进行applend的线程数
appendsInProgress.incrementAndGet();
// 根据TopicPartition获取或新建Deque双端队列
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
...
private Deque<ProducerBatch> getOrCreateDeque(TopicPartition tp) {
Deque<ProducerBatch> d = this.batches.get(tp);
if (d != null)
return d;
d = new ArrayDeque<>();
Deque<ProducerBatch> previous = this.batches.putIfAbsent(tp, d);
if (previous == null)
return d;
else
return previous;
}
// 尝试将消息加入到缓冲区中
// 加锁保证同一个TopicPartition写入有序
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 尝试写入
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, Deque<ProducerBatch> deque) {
// 从双端队列的尾部取出ProducerBatch
ProducerBatch last = deque.peekLast();
if (last != null) {
// 取到了,尝试添加消息
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, time.milliseconds());
// 空间不够,返回null
if (future == null)
last.closeForRecordAppends();
else
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false);
}
// 取不到返回null
return null;
}
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
// 空间不够,返回null
if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) {
return null;
} else {
// 真正添加消息
Long checksum = this.recordsBuilder.append(timestamp, key, value, headers);
...
FutureRecordMetadata future = ...
// future和回调callback进行关联
thunks.add(new Thunk(callback, future));
...
return future;
}
}
// 尝试applend失败(返回null),会走到这里。如果tryApplend成功直接返回了
// 从BufferPool中申请内存空间,用于创建新的ProducerBatch
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// 注意这里,前面已经尝试添加失败了,且已经分配了内存,为何还要尝试添加?
// 因为可能已经有其他线程创建了ProducerBatch或者之前的ProducerBatch已经被Sender线程释放了一些空间,所以在尝试添加一次。这里如果添加成功,后面会在finally中释放申请的空间
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
return appendResult;
}
// 尝试添加失败了,新建ProducerBatch
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
// 将buffer置为null,避免在finally汇总释放空间
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
finally {
// 最后如果再次尝试添加成功,会释放之前申请的内存(为了新建ProducerBatch)
if (buffer != null)
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
// 将消息写入缓冲区
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,serializedValue, headers, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
// 缓冲区满了或者新创建的ProducerBatch,唤起Sender线程
this.sender.wakeup();
}
return result.future;
Sender发送消息线程
主要流程如下
Sender.run
Sender.runOnce
Sender.sendProducerData
// 获取集群信息
Metadata.fetch
// 获取可以发送消息的分区且已经获取到了leader分区的节点
RecordAccumulator.ready
// 根据准备好的节点信息从缓冲区中获取topicPartion对应的Deque队列中取出ProducerBatch信息
RecordAccumulator.drain
// 将消息转移到每个节点的生产请求队列中
Sender.sendProduceRequests
// 为消息创建生产请求队列
Sender.sendProducerRequest
KafkaClient.newClientRequest
// 下面是发送消息
KafkaClient.sent
NetWorkClient.doSent
Selector.send
// 其实上面并不是真正执行I/O,只是写入到KafkaChannel中
// poll 真正执行I/O
KafkaClient.poll
通过源码分析下Sender线程的主要流程
KafkaProducer的构造方法在实例化时启动一个KafkaThread线程来执行Sender
// KafkaProducer构造方法启动Sender
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
// Sender->run()->runOnce()
long currentTimeMs = time.milliseconds();
// 发送生产的消息
long pollTimeout = sendProducerData(currentTimeMs);
// 真正执行I/O操作
client.poll(pollTimeout, currentTimeMs);
// 获取集群信息
Cluster cluster = metadata.fetch();
// 获取准备好可以发送消息的分区且已经获取到leader分区的节点
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// ReadyCheckResult 包含可以发送消息且获取到leader分区的节点集合、未获取到leader分区节点的topic集合
public final Set<Node> 的节点;
public final long nextReadyCheckDelayMs;
public final Set<String> unknownLeaderTopics;
ready方法主要是遍历在上面介绍RecordAccumulator添加消息的容器,Map<TopicPartition, Deque>,从集群信息中根据TopicPartition获取leader分区所在节点,找不到对应leader节点但有要发送的消息的topic添加到unknownLeaderTopics中。同时把那些根据TopicPartition可以获取leader分区且消息满足发送的条件的节点添加到的节点中
// 遍历batches
for (Map.Entry<TopicPartition, Deque<ProducerBatch>> entry : this.batches.entrySet()) {
TopicPartition part = entry.getKey();
Deque<ProducerBatch> deque = entry.getValue();
// 根据TopicPartition从集群信息获取leader分区所在节点
Node leader = cluster.leaderFor(part);
synchronized (deque) {
if (leader == null && !deque.isEmpty()) {
// 添加未找到对应leader分区所在节点但有要发送的消息的topic
unknownLeaderTopics.add(part.topic());
} else if (!readyNodes.contains(leader) && !isMuted(part, nowMs)) {
....
if (sendable && !backingOff) {
// 添加准备好的节点
readyNodes.add(leader);
} else {
...
}
然后对返回的unknownLeaderTopics进行遍历,将topic加入到metadata信息中,调用metadata.requestUpdate方法请求更新metadata信息
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
result.unknownLeaderTopics);
this.metadata.requestUpdate();
对已经准备好的节点进行最后的检查,移除那些节点连接没有就绪的节点,主要根据KafkaClient.ready方法进行判断
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
// 调用KafkaClient.ready方法验证节点连接是否就绪
if (!this.client.ready(node, now)) {
// 移除没有就绪的节点
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
}
}
下面开始创建生产消息的请求
// 从RecordAccumulator中取出TopicPartition对应的Deque双端队列,然后从双端队列头部取出ProducerBatch,作为要发送的信息
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
把消息封装成ClientRequest
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,requestTimeoutMs, callback);
调用KafkaClient发送消息(并非真正执行I/O),涉及到KafkaChannel。Kafka的通信采用的是NIO方式
// NetworkClient.doSent方法
String destination = clientRequest.destination();
RequestHeader header = clientRequest.makeHeader(request.version());
...
Send send = request.toSend(destination, header);
InFlightRequest inFlightRequest = new InFlightRequest(clientRequest,header,isInternalRequest,request,send,now);
this.inFlightRequests.add(inFlightRequest);
selector.send(send);
...
// Selector.send方法
String connectionId = send.destination();
KafkaChannel channel = openOrClosingChannelOrFail(connectionId);
if (closingChannels.containsKey(connectionId)) {
this.failedSends.add(connectionId);
} else {
try {
channel.setSend(send);
...
到这里,发送消息的工作准备的差不多了,调用KafkaClient.poll方法,真正执行I/O操作
client.poll(pollTimeout, currentTimeMs);
用一张图总结Sender线程的流程
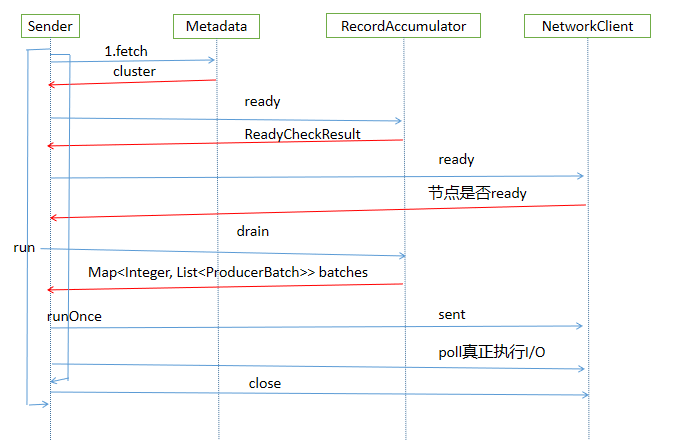
通过上面的介绍,我们梳理出了Kafka生产消息的主要流程,涉及到主线程往RecordAccumulator中写入消息,同时后台的Sender线程从RecordAccumulator中获取消息,使用NIO的方式把消息发送给Kafka,用一张图总结
后记
这是本公众号第一次尝试写源码相关的文章,说实话真不知道该如何下笔,代码截图、贴整体代码等感觉都被我否定了,最后采用了这种方式,介绍主要流程,把无关代码省略,配合流程图。
上周参加了华为云kafka实战课程,简单看了下kafka的生产和消费代码,想简单梳理下,然后在周日中午即8.17开始阅读源码,梳理流程,一直写到了晚上12点多,还剩一点没有完成,周一早晨早起完成了这篇文章。当然这篇文章忽略了很多更细节的东西,后面会继续深入,勇于尝试,不断精进,加油!
参考资料
华为云实战
极客时间kafka专栏
最新文章
- [原]Ubuntu 14.04编译Android Kernel
- Eclipse反编译工具Jad及插件JadClipse配置
- Git+Gradle+Eclipse构建项目
- university, school, college, department, institute的区别
- 深入理解ClassLoader(四)—类的父委托加载机制
- Tortoisegit 记住用户名和密码
- FastReport的WCF托管到Windows服务的配置文件
- iOS TextView输入长度限制 设置placeholder
- bzoj 3622 已经没有什么好害怕的了 类似容斥,dp
- 并查集(union-find set)与Kruskal算法
- helm一键 安装mariadb-ha(详细)
- MySQL用户授权【转】
- kafka安装和部署
- 术语CDATA,其实可以理解为一种特殊的转移字符
- Java和Python安装和编译器使用
- UVa 12186 Another Crisis (DP)
- Connection Manager ->> Multiple Flat File Connection & Multiple File Connection
- android之 Activity跳转出现闪屏
- PHP案例:学生信息管理系统
- Java and unsigned int, unsigned short, unsigned byte, unsigned long, etc. (Or rather, the lack thereof)