以股票案例入门基于SVM的机器学习
SVM是Support Vector Machine的缩写,中文叫支持向量机,通过它可以对样本数据进行分类。以股票为例,SVM能根据若干特征样本数据,把待预测的目标结果划分成“涨”和”跌”两种,从而实现预测股票涨跌的效果。
1 通过简单案例了解SVM的分类作用
在Sklearn库里,封装了SVM分类的相关方法,也就是说,我们无需了解其中复杂的算法,即可用它实现基于SVM的分类。通过如下SimpleSVMDemo.py案例,我们来看下通过SVM库实现分类的做法,以及相关方法的调用方式。
1 #!/usr/bin/env python
2 #coding=utf-8
3 import numpy as np
4 import matplotlib.pyplot as plt
5 from sklearn import svm
6 #给出平面上的若干点
7 points = np.r_[[[-1,1],[1.5,1.5],[1.8,0.2],[0.8,0.7],[2.2,2.8],[2.5,3.5],[4,2]]]
8 #按0和1标记成两类
9 typeName = [0,0,0,0,1,1,1]
在第5行里,我们引入了基于SVM的库。在第7行,我们定义了若干个点,并在第9行把这些点分成了两类,比如[-1,1]点是第一类,而[4,2]是第二类。
这里请注意,在第7行定义点的时候,是通过np.r_方法,把数据转换成“列矩阵”,这样做的目的是让数据结构满足fit方法的要求。
10 #建立模型
11 svmTool = svm.SVC(kernel='linear')
12 svmTool.fit(points,typeName) #传入参数
13 #确立分类的直线
14 sample = svmTool.coef_[0] #系数
15 slope = -sample[0]/sample[1] #斜率
16 lineX = np.arange(-2,5,1)#获取-2到5,间距是1的若干数据
17 lineY = slope*lineX-(svmTool.intercept_[0])/sample[1]
在第11行里,我们创建了基于SVM的对象,并指定该SVM模型采用比较常用的“线性核”来实现分类操作。
在第14行,通过fit训练样本。这里fit方法和之前基于线性回归案例中的fit方法是一样的,只不过这里是基于线性核的相关算法,而之前是基于线性回归的相关算法(比如最小二乘法)。训练完成后,通过第14行和第15行的代码,我们得到了能分隔两类样本的直线,包括直线的斜率和截距,并通过第16行和第17行的代码设置了分隔线的若干个点。
18 #画出划分直线
19 plt.plot(lineX,lineY,color='blue',label='Classified Line')
20 plt.legend(loc='best') #绘制图例
21 plt.scatter(points[:,0],points[:,1],c='R')
22 plt.show()
计算完成后,我们通过第19行的plot方法绘制了分隔线,并在第21行通过scatter方法绘制所有的样本点。由于points是“列矩阵”的数据结构,所以是用points[:,0]来获取绘制点的 x坐标,用points[:,1]来获取y坐标,最后是通过第22行的show方法绘制图形。运行上述代码,我们能看到如下图13.8的效果,从中我们能看到,蓝色的边界线能有效地分隔两类样本。
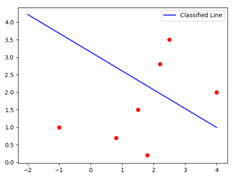
从这个例子中我们能看到,SVM的作用是,根据样本,训练出能划分不同种类数据的边界线,由此实现“分类”的效果。而且,在根据训练样本确定好边界线的参数后,还能根据其它没有明确种类样本,计算出它的种类,以此实现“预测”效果。
2 数据标准化处理
标准化(normalization)处理是将特征样本按一定算法进行缩放,让它们落在某个范围比较小的区间,同时去掉单位限制,让样本数据转换成无量纲的纯数值。
在用机器学习方法进行训练时,一般需要进行标准化处理,原因是Sklearn等库封装的一些机器学习算法对样本有一定的要求,如果有些特征值的数量级偏离大多数特征值的数量级,或者有特征值偏离正态分布,那么预测结果会不准确。
需要说明的是,虽然在训练前对样本进行了标准化处理,改变了样本值,但由于在标准化的过程中是用同一个算法对全部样本进行转换,属于“数据优化”,不会对后继的训练起到不好的作用。
这里我们是通过sklearn库提供的preprocessing.scale方法实现标准化,该方法是让特征值减去平均值然后除以标准差。通过如下ScaleDemo.py案例,我们实际用下preprocessing.scale方法。
1 #!/usr/bin/env python
2 #coding=utf-8
3 from sklearn import preprocessing
4 import numpy as np
5
6 origVal = np.array([[10,5,3],
7 [8,6,12],
8 [14,7,15]])
9 #计算均值
10 avgOrig = origVal.mean(axis=0)
11 #计算标准差
12 stdOrig=origVal.std(axis=0)
13 #减去均值,除以标准差
14 print((origVal-avgOrig)/stdOrig)
15 scaledVal=preprocessing.scale(origVal)
16 #直接输出preprocessing.scale后的结果
17 print(scaledVal)
在第6行里,我们初始化了一个长宽各为3的矩阵,在第10行,通过mean方法计算了该矩阵的均值,在第12行则通过std方法计算标准差。
第14行是用原始值减去均值,再除以标准差,在第17行,是直接输出preprocessing.scale的结果。第14行和第17行的输出结果相同,均是下值,从中我们验证了标准化的具体做法。
1 [[-0.26726124 -1.22474487 -1.37281295]
2 [-1.06904497 0. 0.39223227]
3 [ 1.33630621 1.22474487 0.98058068]]
3 预测股票涨跌
在之前的案例中,我们用基于SVM的方法,通过一维直线来分类二维的点。据此可以进一步推论:通过基于SVM的方法,我们还可以分类具有多个特征值的样本。
比如可以通过开盘价、收盘价、最高价、最低价和成交量等特征值,用SVM的算法训练出这些特征值和股票“涨“和“跌“的关系,即通过特征值划分指定股票“涨”和“跌”的边界,这样的话,一旦输入其它的股票特征数据,即可预测出对应的涨跌情况。在如下的PredictStockBySVM.py案例中,我们给出了基于SVM预测股票涨跌的功能。
1 #!/usr/bin/env python
2 #coding=utf-8
3 import pandas as pd
4 from sklearn import svm,preprocessing
5 import matplotlib.pyplot as plt
6 origDf=pd.read_csv('D:/stockData/ch13/6035052018-09-012019-05-31.csv',encoding='gbk')
7 df=origDf[['Close', 'Low','Open' ,'Vol','Date']]
8 #diff列表示本日和上日收盘价的差
9 df['diff'] = df["Close"]-df["Close"].shift(1)
10 df['diff'].fillna(0, inplace = True)
11 #up列表示本日是否上涨,1表示涨,0表示跌
12 df['up'] = df['diff']
13 df['up'][df['diff']>0] = 1
14 df['up'][df['diff']<=0] = 0
15 #预测值暂且初始化为0
16 df['predictForUp'] = 0
第6行里,我们从指定文件读取了包含股票信息的csv文件,该csv格式的文件其实是从网络数据接口获取得到的,具体做法可以参考前面博文。
从第9行里,我们设置了df的diff列为本日收盘价和前日收盘价的差值,通过第12行到第14行的代码,我们设置了up列的值,具体是,如果当日股票上涨,即本日收盘价大于前日收盘价,则up值是1,反之如果当日股票下跌,up值则为0。
在第16行里,我们在df对象里新建了表示预测结果的predictForUp列,该列的值暂且都设置为0,在后继的代码里,将根据预测结果填充这列的值。
17 #目标值是真实的涨跌情况
18 target = df['up']
19 length=len(df)
20 trainNum=int(length*0.8)
21 predictNum=length-trainNum
22 #选择指定列作为特征列
23 feature=df[['Close', 'High', 'Low','Open' ,'Volume']]
24 #标准化处理特征值
25 feature=preprocessing.scale(feature)
在第18行里,我们设置训练目标值是表示涨跌情况的up列,在第20行,设置了训练集的数量是总量的80%,在第23行则设置了训练的特征值,请注意这里去掉了日期这个不相关的列,而且,在第25行,对特征值进行了标准化处理。
26 #训练集的特征值和目标值
27 featureTrain=feature[1:trainNum-1]
28 targetTrain=target[1:trainNum-1]
29 svmTool = svm.SVC(kernel='liner')
30 svmTool.fit(featureTrain,targetTrain)
在第27行和第28行里,我们通过截取指定行的方式,得到了特征值和目标值的训练集,在第26行里,以线性核的方式创建了SVM分类器对象svmTool。
在第30行里,通过fit方法,用特征值和目标值的训练集训练svmTool分类对象。从上文里我们已经看到,训练所用的特征值是开盘收盘价、最高最低价和成交量,训练所用的目标值是描述涨跌情况的up列。在训练完成后,svmTool对象中就包含了能划分股票涨跌的相关参数。
31 predictedIndex=trainNum
32 #逐行预测测试集
33 while predictedIndex<length:
34 testFeature=feature[predictedIndex:predictedIndex+1]
35 predictForUp=svmTool.predict(testFeature)
36 df.ix[predictedIndex,'predictForUp']=predictForUp
37 predictedIndex = predictedIndex+1
在第33行的while循环里,我们通过predictedIndex索引值,依次遍历测试集。
在遍历过程中,通过第35行的predict方法,用训练好的svmTool分类器,逐行预测测试集中的股票涨跌情况,并在第36行里,把预测结果设置到df对象的predictForUp列中。
38 #该对象只包含预测数据,即只包含测试集
39 dfWithPredicted = df[trainNum:length]
40 #开始绘图,创建两个子图
41 figure = plt.figure()
42 #创建子图
43 (axClose, axUpOrDown) = figure.subplots(2, sharex=True)
44 dfWithPredicted['Close'].plot(ax=axClose)
45 dfWithPredicted['predictForUp'].plot(ax=axUpOrDown,color="red", label='Predicted Data')
46 dfWithPredicted['up'].plot(ax=axUpOrDown,color="blue",label='Real Data')
47 plt.legend(loc='best') #绘制图例
48 #设置x轴坐标标签和旋转角度
49 major_index=dfWithPredicted.index[dfWithPredicted.index%2==0]
50 major_xtics=dfWithPredicted['Date'][dfWithPredicted.index%2==0]
51 plt.xticks(major_index,major_xtics)
52 plt.setp(plt.gca().get_xticklabels(), rotation=30)
53 plt.title("通过SVM预测603505的涨跌情况")
54 plt.rcParams['font.sans-serif']=['SimHei']
55 plt.show()
由于在之前的代码里,我们只设置测试集的predictForUp列,并没有设置训练集的该列数据,所以在第39行里,用切片的手段,把测试集数据放置到dfWithPredicted对象中,请注意这里切片的起始和结束值是测试集的起始和结束索引值。至此完成了数据准备工作,在之后的代码里,我们将用matplotlib库开始绘图。
在第43行里,我们通过subplots方法设置了两个子图,并通过sharex=True让这两个子图的x轴具有相同的刻度和标签。在第44行代码里,在axClose子图中,我们用plot方法绘制了收盘价的走势。在第45行代码里,在axUpOrDown子图中,我们绘制了预测到的涨跌情况,而在第46行里,还是在axUpOrDown子图里,绘制了这些天的股票真实的涨跌情况。
在第49行到第52行的代码里,我们设置了x标签的文字以及旋转角度,这样做的目的是让标签文字看上去不至于太密集。在第53行里,我们设置了中文标题,由于要显示中文,所以需要第54行的代码,最后在55行通过show方法展示了图片。运行上述代码,能看到如下图所示的效果。
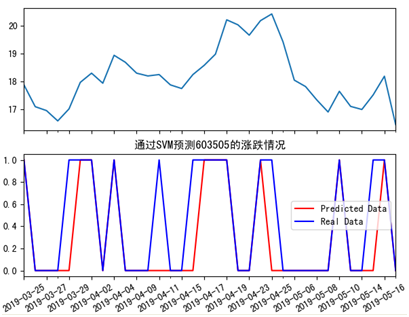
其中上图展示了收盘价,下图的蓝色线条表示真实的涨跌情况,0表示跌,1表示上涨,而红色则表示预测后的结果。
4 结论
对比一下,虽有偏差,但大体相符。综上所述,本案例是数学角度,演示了通过SVM分类的做法,包括如果划分特征值和目标值,如何对样本数据进行标准化处理,如何用训练数据训练SVM,还有如何用训练后的结果预测分类结果。
5 总结和版权说明
本文是给程序员加财商系列,之前还有两篇博文
有不少网友转载和想要转载我的博文,本人感到十分荣幸,这也是本人不断写博文的动力。关于本文的版权有如下统一的说明,抱歉就不逐一回复了。
1 本文可转载,无需告知,转载时请用链接的方式,给出原文出处,别简单地通过文本方式给出,同时写明原作者是hsm_computer。
2 在转载时,请原文转载 ,谢绝洗稿。否则本人保留追究法律责任的权利。
最新文章
- Windows Server 2008 R2安装子域控制器
- ubuntu下安装python各类运维用模块(以后补充用途)
- X3850M2安装CertOS 7 KVM 2--VNC
- Mina传输大数组,多路解码,粘包问题的处理
- Java基本语法笔记
- ACL
- 使用Android Studio打Andorid apk包的流程
- VS2010+Opencv+SIFT以及出现的问题-关于代码sift_3_c的说明
- ZOJ 3494 (AC自动机+高精度数位DP)
- jmeter笔记1
- tomcat server获取用户的请求地址
- Kakfa揭秘 Day6 Consumer源码解密
- nyist 61 传纸条 nyist 712 探 寻 宝 藏(双线程dp问题)
- C# 获取计算机 信息
- ubuntu 下添加sublime text 启动图标
- Android:ListViewAdapter
- java第一课 面向对象的编程概念
- 20181225-Linux Shell Bash环境下自动化创建ssh互信脚本
- 四则运算-ppt演示
- POJ 3280 Cheapest Palindrome【DP】