CDH5.13快速体验
2024-10-08 04:52:56
相对于易用性很差Apache Hadoop,其他商业版Hadoop的性能易用性都有更好的表现,如Cloudera、Hortonworks、MapR以及国产的星环,下面使用CDH(Cloudera Distribution Hadoop)快速体验下。
首先从,从Cloudera官网下载部署好的虚拟机环境https://www.cloudera.com/downloads/quickstart_vms/5-13.html.html,解压后用虚拟机打开,官方推荐至少8G内存2cpu,由于笔记本性能足够,我改为8G内存8cpu启动,虚拟机各种账号密码都是cloudera
打开虚拟机的浏览器访问http://quickstart.cloudera/#/
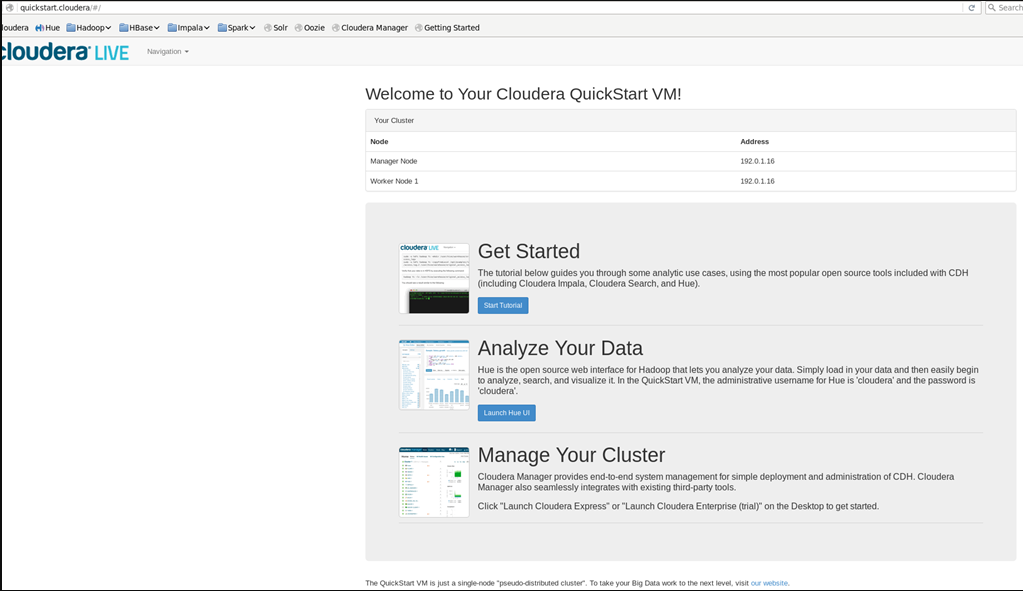 点击Get Started以体验
点击Get Started以体验

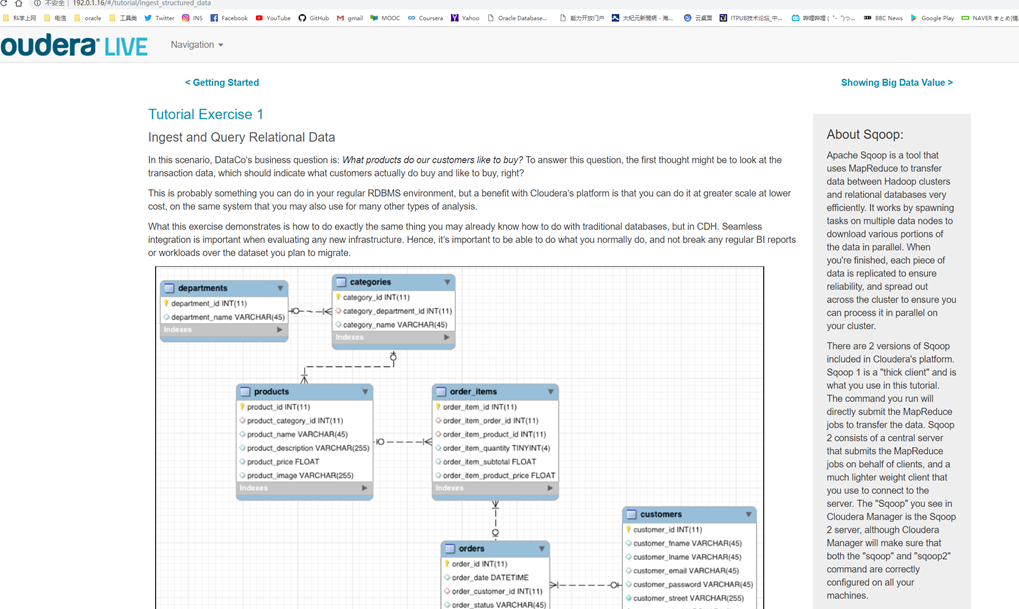
Tutorial Exercise 1:导入、查询关系数据
利用sqoop工具将mysql数据导入HDFS中
[cloudera@quickstart ~]$ sqoop import-all-tables \
> -m 1 \
> --connect jdbc:mysql://quickstart:3306/retail_db \
> --username=retail_dba \
> --password=cloudera \
> --compression-codec=snappy \
> --as-parquetfile \
> --warehouse-dir=/user/hive/warehouse \
> --hive-import
Warning: /usr/lib/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
19/04/29 18:31:46 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6-cdh5.13.0
19/04/29 18:31:46 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
19/04/29 18:31:46 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override
19/04/29 18:31:46 INFO tool.BaseSqoopTool: delimiters with --fields-terminated-by, etc.
19/04/29 18:31:46 WARN tool.BaseSqoopTool: It seems that you're doing hive import directly into default (many more lines suppressed) Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=87
CPU time spent (ms)=3690
Physical memory (bytes) snapshot=443174912
Virtual memory (bytes) snapshot=1616969728
Total committed heap usage (bytes)=352845824
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
19/04/29 18:38:27 INFO mapreduce.ImportJobBase: Transferred 46.1328 KB in 85.1717 seconds (554.6442 bytes/sec)
19/04/29 18:38:27 INFO mapreduce.ImportJobBase: Retrieved 1345 records.
[cloudera@quickstart ~]$ hadoop fs -ls /user/hive/warehouse/
Found 6 items
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:32 /user/hive/warehouse/categories
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:33 /user/hive/warehouse/customers
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:34 /user/hive/warehouse/departments
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:35 /user/hive/warehouse/order_items
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:36 /user/hive/warehouse/orders
drwxrwxrwx - cloudera supergroup 0 2019-04-29 18:38 /user/hive/warehouse/products
[cloudera@quickstart ~]$ hadoop fs -ls /user/hive/warehouse/categories/
Found 3 items
drwxr-xr-x - cloudera supergroup 0 2019-04-29 18:31 /user/hive/warehouse/categories/.metadata
drwxr-xr-x - cloudera supergroup 0 2019-04-29 18:32 /user/hive/warehouse/categories/.signals
-rw-r--r-- 1 cloudera supergroup 1957 2019-04-29 18:32 /user/hive/warehouse/categories/6e701a22-4f74-4623-abd1-965077105fd3.parquet
[cloudera@quickstart ~]$
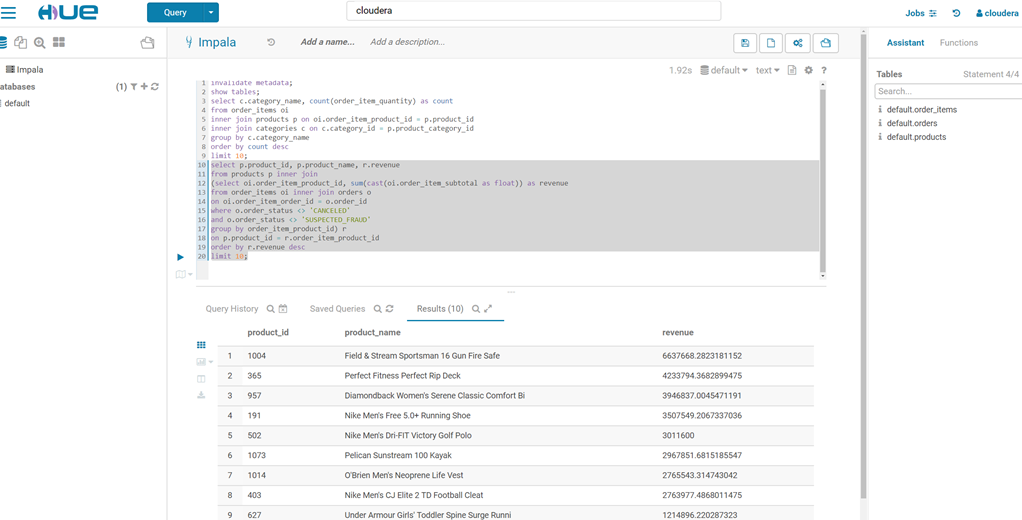
然后访问http://quickstart.cloudera:8888/,来访问表(invalidate metadata;是用来刷新元数据的)
Tutorial Exercise 2 :外部表方式导入访问日志数据到HDFS并查询
通过hive建表
CREATE EXTERNAL TABLE intermediate_access_logs (
ip STRING,
date STRING,
method STRING,
url STRING,
http_version STRING,
code1 STRING,
code2 STRING,
dash STRING,
user_agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex' = '([^ ]*) - - \\[([^\\]]*)\\] "([^\ ]*) ([^\ ]*) ([^\ ]*)" (\\d*) (\\d*) "([^"]*)" "([^"]*)"',
'output.format.string' = "%1$$s %2$$s %3$$s %4$$s %5$$s %6$$s %7$$s %8$$s %9$$s")
LOCATION '/user/hive/warehouse/original_access_logs'; CREATE EXTERNAL TABLE tokenized_access_logs (
ip STRING,
date STRING,
method STRING,
url STRING,
http_version STRING,
code1 STRING,
code2 STRING,
dash STRING,
user_agent STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/user/hive/warehouse/tokenized_access_logs'; ADD JAR /usr/lib/hive/lib/hive-contrib.jar; INSERT OVERWRITE TABLE tokenized_access_logs SELECT * FROM intermediate_access_logs;
 impala中刷新元数据后访问表
impala中刷新元数据后访问表
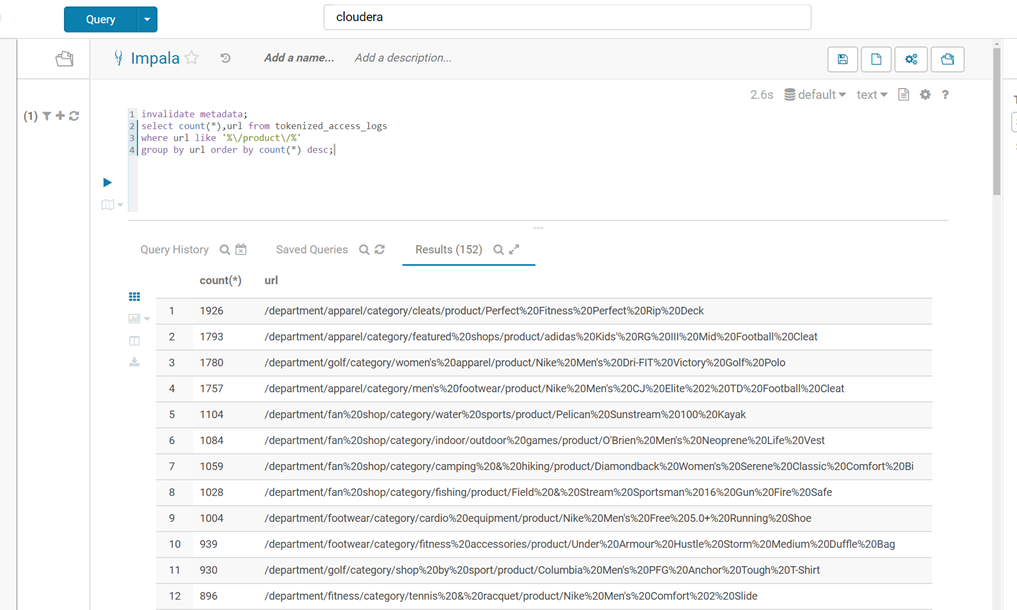
Tutorial Exercise 3:使用spark进行关联分析
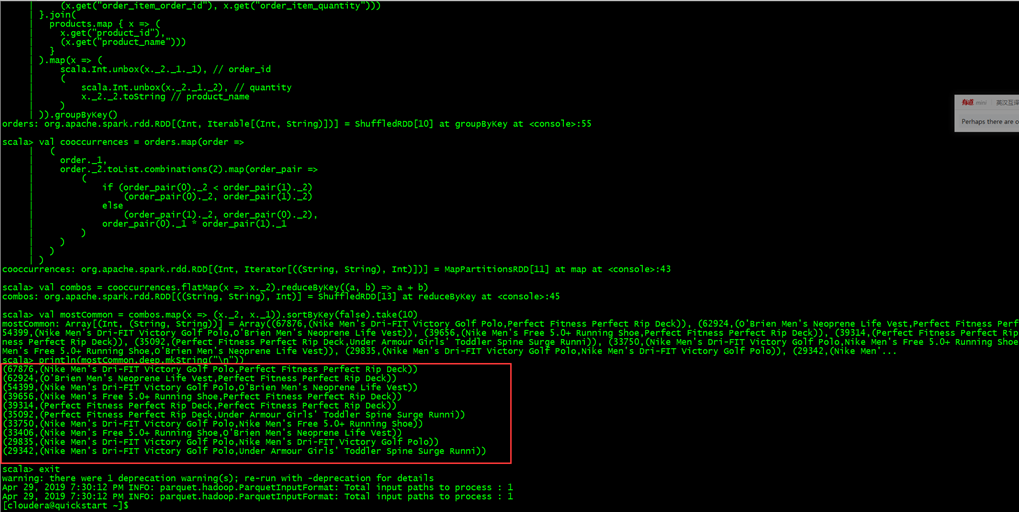
Tutorial Exercise 4:利用flume收集日志,并用solr做全文索引
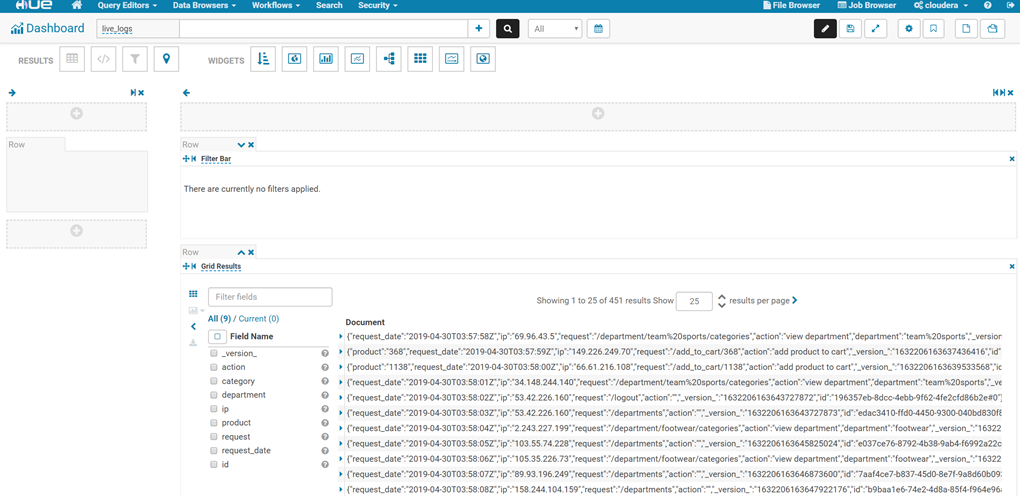
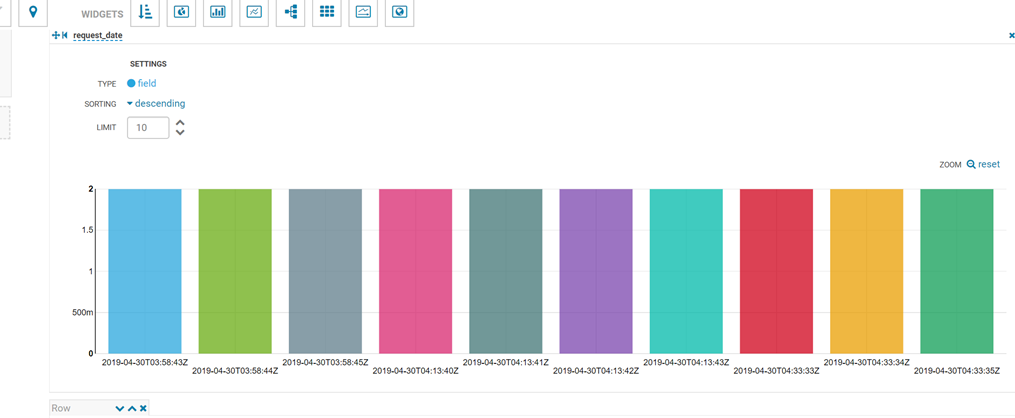
Tutorial Exercise 5:可视化
 Tutorial is over!
Tutorial is over!
最新文章
- UESTC 764 失落的圣诞节 --RMQ/线段树
- Android 设计中的.9.png
- 软件需求分析之NABCD模型
- MySQL rename database如何做?
- c# 清空txt文本文件的值
- 3223: Tyvj 1729 文艺平衡树 - BZOJ
- careercup-排序和查找 11.5
- spring 整合JDBC
- Python学习之四【变量】
- layer iframe层的使用,传参
- WPF WebBrowser Memory Leak 问题及临时解决方法
- 关于常用mysql的文件
- Mini2440 通过 SPI 操作 OLED (裸板下使用 SPI 控制器)
- 通过Jekins执行bat脚本始终无法完成
- 华为交换机SNMP OID
- 阿里云OSS不同账号之间的迁移
- hdu 2795 Billboard 线段树+二分
- hdoj1160 DP--LIS
- 基于jQuery带进度条全屏图片轮播代码
- Optimal Milking---poj2112(多重匹配+Floyd+二分)
热门文章
- socket缓冲区以及阻塞模式(七)
- Urllib 库使用
- Associatively Segmenting Instances and Semantics in Point Clouds
- nexus php composer 私服搭建
- nginx日志说明
- 爬虫,爬取景点信息采用pandas整理数据
- JavaScript 系列--JavaScript一些奇淫技巧的实现方法(二)数字格式化 1234567890转1,234,567,890;argruments 对象(类数组)转换成数组
- http与tcp,udp的区别
- docker-compose之跳板机jumpserver部署
- navicat for Mysql查询数据不能直接修改