十二、Hadoop学习笔记————Hive的基本原理
2024-10-15 23:37:08
一般用户用CLI(命令行界面)接口,元数据库含有表结构

单用户、多用户、远程服务
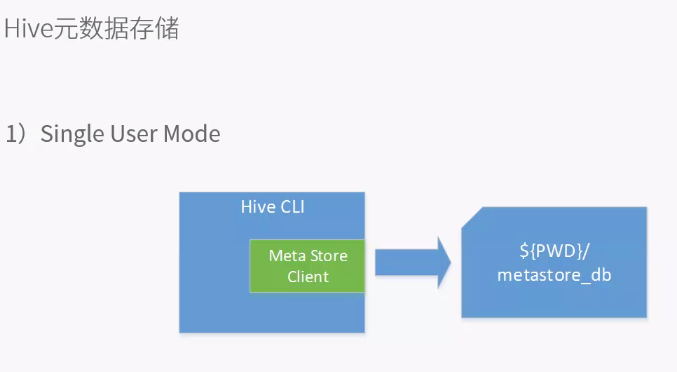
生成db文件,只能单客户端使用数据库

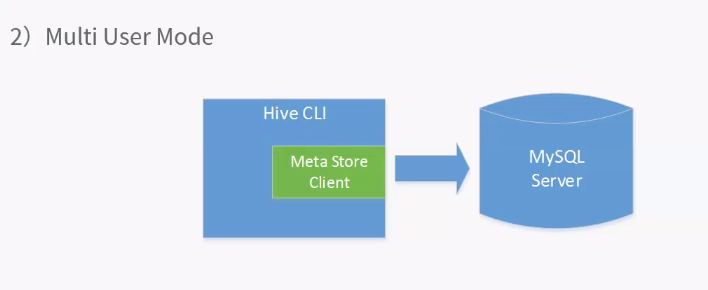
多用户是最常用的使用模式

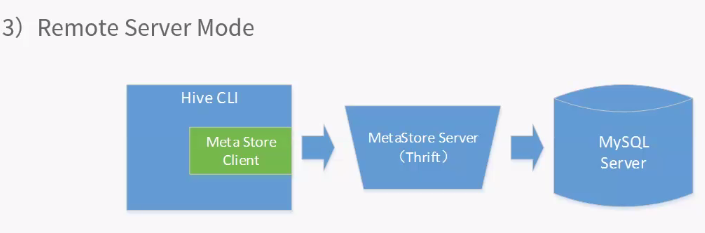
配置与多用户一致

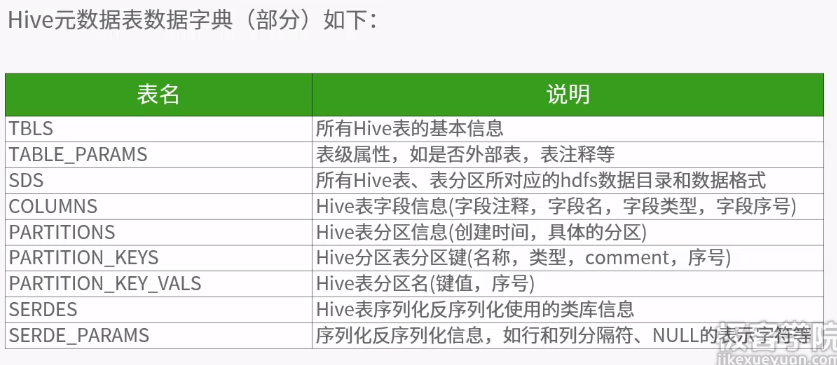

数据格式用户自定义
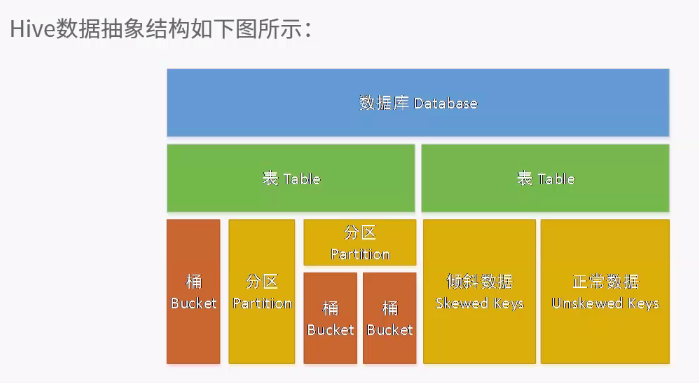

所有的表都存于改配置路径下,除了外部表



外部表指定location则可,删除一个表只会删除元数据(元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能),表中的数据不会删除

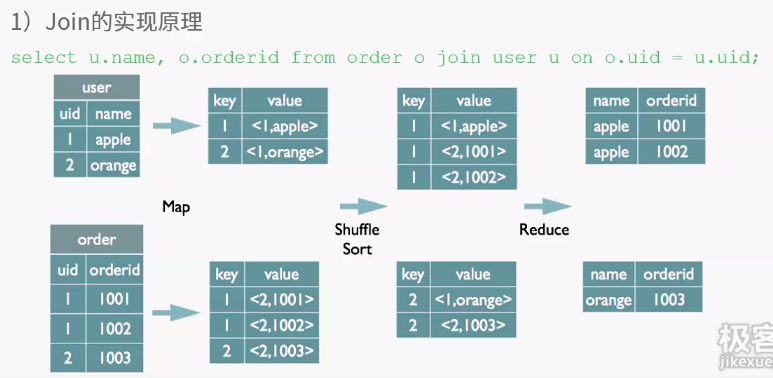
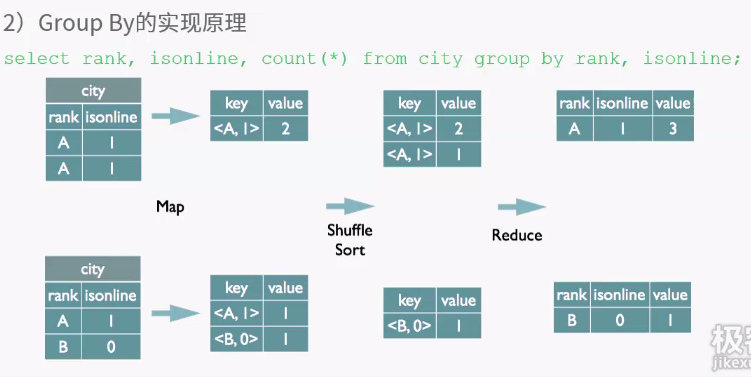
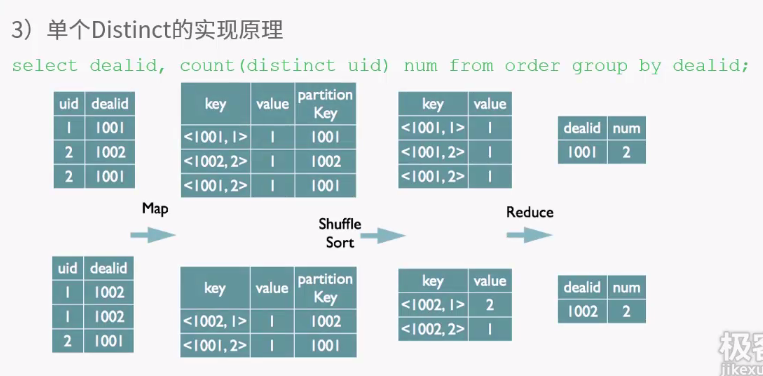
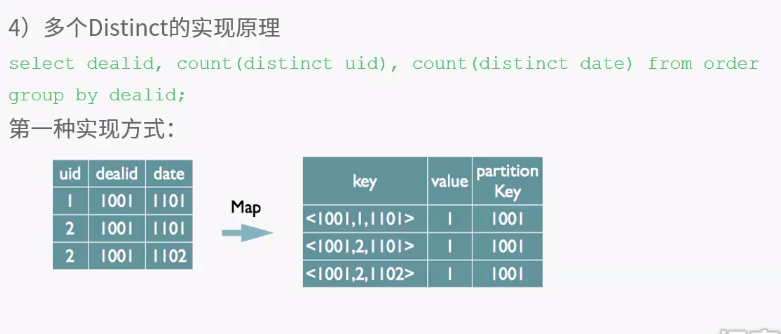
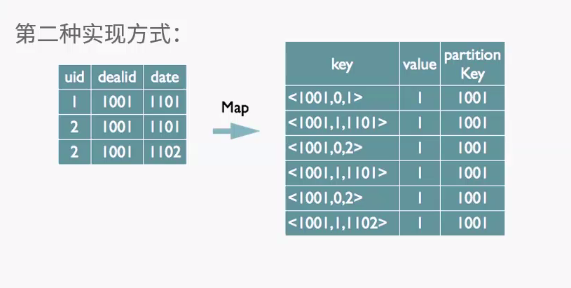
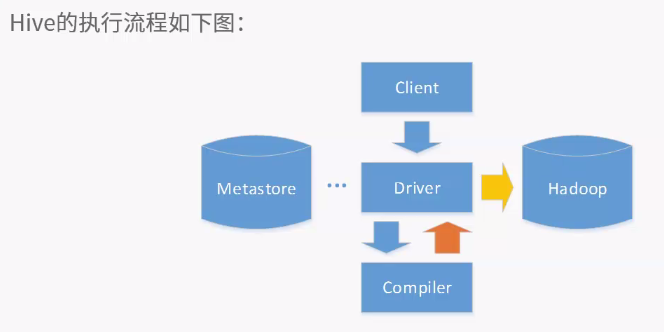
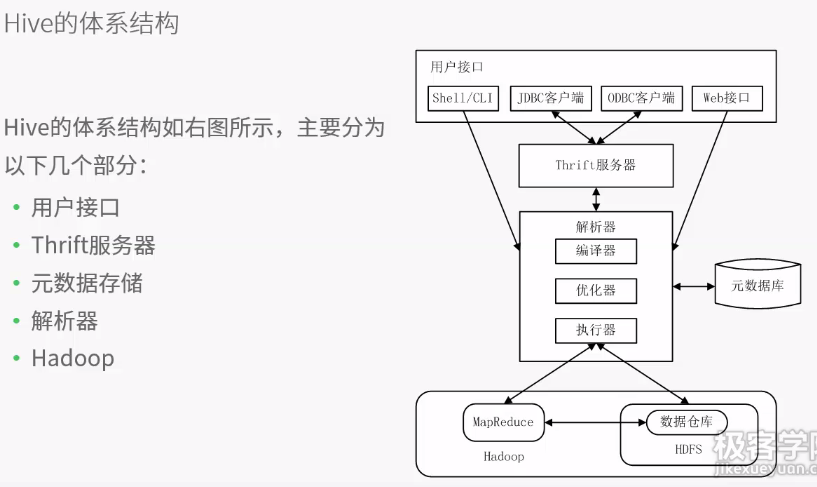
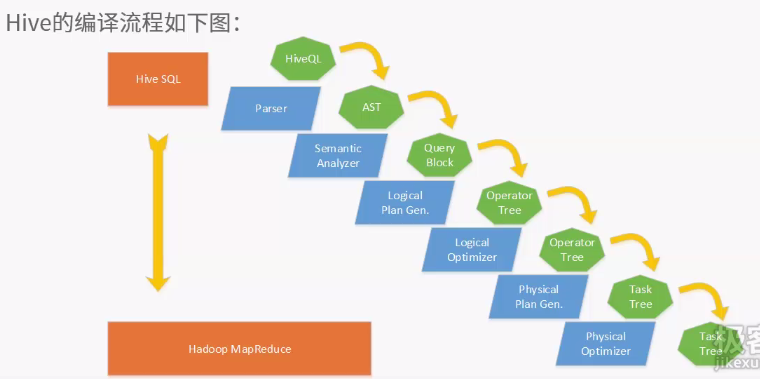
客户端提供查询语序,给hive,hive交给driver处理,分为四步
1.编译机编译,从metastore中获取元数据,生成逻辑计划
2.执行物理计划
3.Driver进行优化
4.执行器执行时对物理计划分解为job,并提交给jobtracker,



最新文章
- 烂泥:jira7.2安装、中文及破解
- a:link,a:visited,a:hover,a:active
- Oracle 中 call 和 exec的区别
- 与(and)&&
- EF中的那些批量操作
- 关于前置式递增和后置式递增的小知识(++x与x++)
- 大话C#之属性
- VS2013 调试MVC源码[MVC5.2.3+MVC4Web项目]
- XML文件序列化和反序列化的相关内容
- Oracle XE修改默认HTTP端口8080
- Object -C self -- 笔记
- Keil C51 与 ARM 并存的方法
- LaTeX 一个段落加边框
- 【搞事情】VS2015下的openGL初始化
- JAVA RPC (六) 之thrift反序列化RPC消息体
- python 的基础 学习 第三
- 22.2、react生命周期与react脚手架(二)
- R apply() 函数和 tapply() 函数
- Go Example--组合函数
- koa2+log4js+sequelize搭建的nodejs服务