对HashMap的理解(三):ConcurrentHashMap
HashMap不是线程安全的。在并发插入元素的时候,有可能出现环链表,让下一次读操作出现死循环。
避免HashMap的线程安全问题有很多方法,比如改用HashTable或Collections.synchronizedMap. (Hashtable是对hashmap中的方法加上了Synchronize,会锁定整个map)
但这两者有着共同的问题:性能。无论读操作还是写操作,它们都会给整个集合加锁,导致同一时间的其他操作为之阻塞。如图。
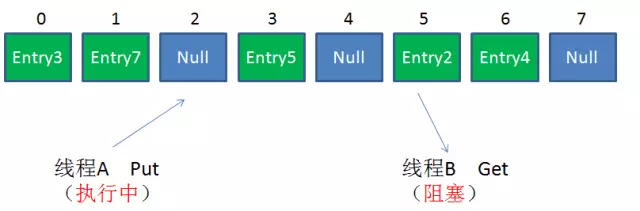
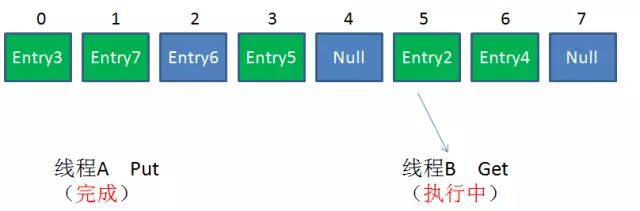
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下,HashTable的效率非常低。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。
那么在并发环境下,如何能够兼顾线程安全和运行效率呢?这时候ConcurrentHashMap就应运而生了。ConcurrentHashMap的锁分段技术可有效提升并发访问率
Hashtable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁。假如容器里有多把锁,每一把锁用于锁容器中的一部分数据,那么当多线程访问容器里不同数据段的数据时,线程之间就不会存在锁竞争,从而可以有效提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。首先将数据分成一段一段地存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个数据段时,其他段的数据也能被其他线程访问。
对于ConcurrentHashMap,最关键的是要理解一个概念:Segment
Segment是什么呢?Segment本身就相当于一个HashMap对象。
同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。
单一的Segment结构如下:
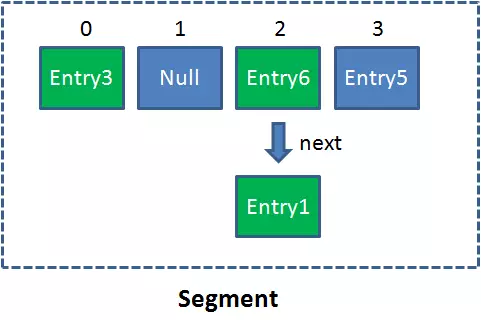
像这样的Segment对象,在ConcurrentHashMap集合中有多少个呢?有2的N次方个,共同保存在一个名为segments的数组当中。
因此整个ConcurrentHashMap的结构如下:
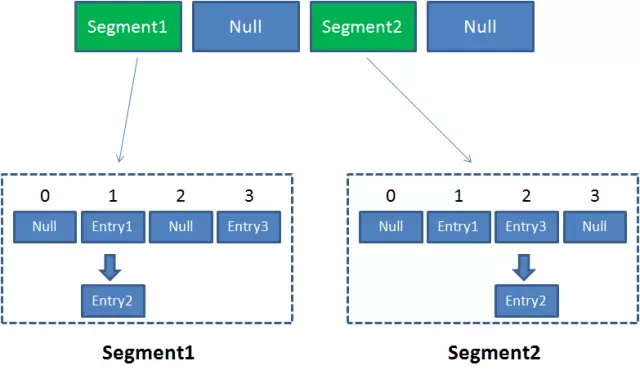
可以说,ConcurrentHashMap是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。
这样的二级结构,和数据库的水平拆分有些相似。
每一个Segment就好比一个自治区,读写操作高度自治,Segment之间互不影响。
(一)、ConcurrentHashMap并发读写的几种情形:
Case1:不同Segment的并发写入
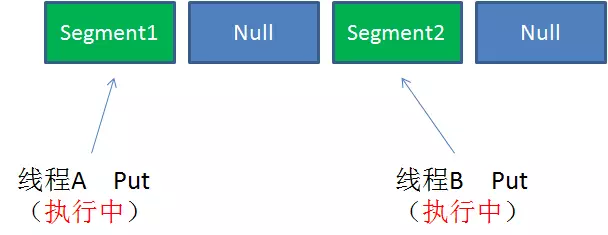
不同Segment的写入是可以并发执行的。
Case2:同一Segment的一写一读
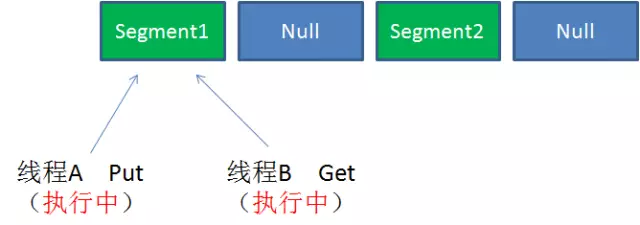
同一Segment的写和读是可以并发执行的。
Case3:同一Segment的并发写入
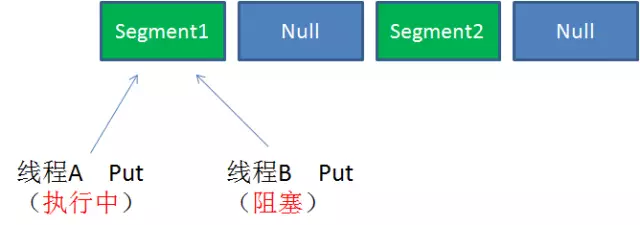
Segment的写入是需要上锁的,因此对同一Segment的并发写入会被阻塞。
由此可见,ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
(二)、ConcurrentHashMap读写的详细过程:
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空才会加锁重读。我们知道HashTable容器的get方法是需要加锁的,那么ConcurrentHashMap的get操作是如何做到不加锁的呢?原因是它的get方法里将要使用的共享变量都定义成volatile类型, 如用于统计当前Segement大小的count字段和用于存储值的HashEntry的value。 定义成volatile的变量, 能够在线程之间保持可见性, 能够被多线程同时读, 并且保证不会读到过期的值, 但是只能被单线程写(有一种情况可以被多线程写, 就是写入的值不依赖于原值),在get操作里只需要读不需要写共享变量count和value, 所以可以不用加锁。 之所以不会读到过期的值, 是因为根据Java内存模型的happen before原则, 对volatile字段的写入操作先于读操作, 即使两个线程同时修改和获取volatile变量, get操作也能拿到最新的值, 这是用volatile替换锁的经典应用场景。
Put方法:
1.为输入的Key做Hash运算,得到hash值
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.判断是否需要对Segment里的HashEntry数组进行扩容
5.再次通过hash值,定位到Segment当中数组的具体位置
6.插入或覆盖HashEntry对象
7.释放锁。
(1) 是否需要扩容
在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold) , 如果超过阈值, 则对数组进行扩容。 值得一提的是, Segment的扩容判断比HashMap更恰当, 因为HashMap是在插入元素后判断元素是否已经到达容量的, 如果到达了就进行扩容, 但是很有可能扩容之后没有新元素插入, 这时HashMap就进行了一次无效的扩容。
(2) 如何扩容
在扩容的时候, 首先会创建一个容量是原来容量两倍的数组, 然后将原数组里的元素进行再散列后插入到新的数组里。 为了高效, ConcurrentHashMap不会对整个容器进行扩容, 而只对某个segment进行扩容。
从步骤可以看出,ConcurrentHashMap在读写时都需要二次定位。首先定位到Segment,之后定位到Segment内具体数组下标。
(三)、ConcurrentHashMap的size方法
既然每个Segment都各自加锁,那么在调用Size方法时,怎么解决一致性的问题呢?
Size方法的目的是统计ConcurrentHashMap的总元素数量, 自然需要把各个Segment内部的元素数量汇总起来。
但是,如果在统计Segment元素数量的过程中,已统计过的Segment瞬间插入新的元素,这时候该怎么办呢?

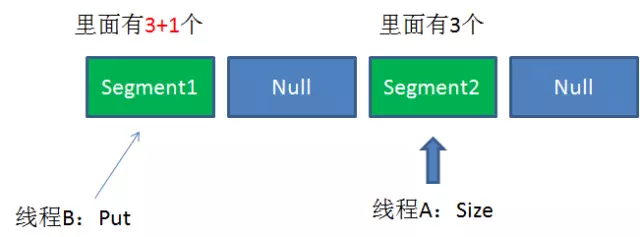

ConcurrentHashMap的Size方法是一个嵌套循环,大体逻辑如下:
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
这种思想和乐观锁悲观锁的思想如出一辙。
为了尽量不锁住所有Segment,首先乐观地假设Size过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有Segment保证强一致性。
参考:
《Java并发编程的艺术》
来自公众号:

最新文章
- fastclick 源码注解及一些基础知识点
- 仿W8屏保
- [转]C#编程总结(三)线程同步
- day6-2面向对象
- Spring基本概念
- 【initrd】向虚拟文件系统initrd.img中添加驱动
- 【二】php常用方法
- 当一个控件属性不存在的时候,IDE会出错在这里
- mybatis之动态SQL
- 实习生的Django[1]
- lambda, reduce, map求阶乘之和
- Webdriver实现对菜单栏的灵活切换功能,附上代码,类似的菜单栏切换可以自己封装
- drupal7 分页
- laravel Scout包在elasticsearch中的应用
- # ? & 号在url中的的作用
- 【Ubuntu Desktop】VMware 中 Unknown Display
- Cookie中的HttpOnly详解
- 理解WebKit和Chromium: JavaScript引擎简介
- Echart ,X轴显示的为tooltip内显示的一部分内容放在上面显示的一部分如下图所示
- [Android] QPST,解BL锁,刷Recovery,备份系统,root,刷框架.
热门文章
- Object C学习笔记1-基本数据类型说明
- 工作总结 vue 城会玩
- async/await工作机制探究--NodeJS
- AxWebBrowser 实现的多进程浏览器 (一)
- Git报错:Your branch is ahead of 'origin/master' by 1 commit
- Python之NMAP详解
- 关于spring boot 使用 mybatis plus INSERT的时候id报错
- 自动分配ip的方法- 【Linux】
- HIVE函数的UDF、UDAF、UDTF
- Netty源码分析第2章(NioEventLoop)---->第2节: NioEventLoopGroup之NioEventLoop的创建