第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
2024-10-20 03:38:15
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式
urllib库中使用xpath表达式
etree.HTML()将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式
#!/usr/bin/env python
# -*- coding:utf8 -*-
import urllib.request
from lxml import etree #导入html树形结构转换模块 wye = urllib.request.urlopen('http://sh.qihoo.com/pc/home').read().decode("utf-8",'ignore')
zhuanh = etree.HTML(wye) #将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式
print(zhuanh)
hqq = zhuanh.xpath('/html/head/title/text()') #通过xpath表达式获取标题 #注意,xpath表达式获取到数据,有时候是列表,有时候不是列表所以要做如下处理
if str(type(hqq)) == "<class 'list'>": #判断获取到的是否是列表
print(hqq)
else:
xh_hqq = [i for i in hqq] #如果不是列表,循环数据组合成列表
print(xh_hqq) #返回 :['【今日爆点】你的专属资讯平台']
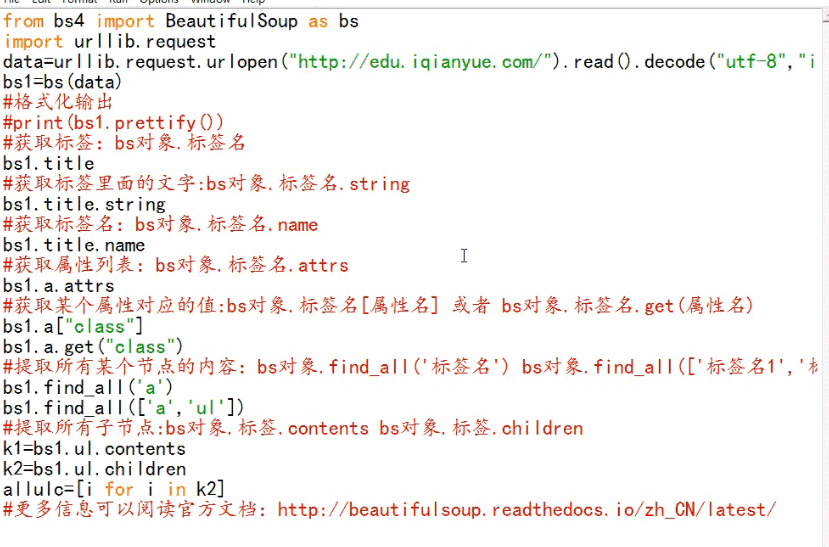
BeautifulSoup基础
BeautifulSoup是获取thml元素的模块
BeautifulSoup-3.2.1版本
最新文章
- webmagic的设计机制及原理-如何开发一个Java爬虫
- jquery常用方法
- Android面试总结 (转)
- hdu3124Arbiter(最小圆距离-扫描线)
- HDU 4832 Chess
- gridview列前加复选框需要注意的一点
- MVC过滤器基本使用
- A WPF File ListView and ComboBox
- java设计模式在公众号的应用——我是一个快乐的单例
- Caused by: java.lang.ClassNotFoundException: javax.persistence.NamedStoredProcedureQuery
- JSP指令与动作
- GCC 警告
- git私有仓库与pycharm联合使用
- python MD5加密方法
- C/C++笔试题(基础题)
- In-Place upgrade to Team Foundation Server (TFS) 2015 from TFS 2013Team Foundation Server TFS TFS 2015 TFS upgrade TFS with Sharepoint
- 用keras实现lstm 利用Keras下的LSTM进行情感分析
- Apache Flume 学习
- CSS制作图形速查表
- php对二维数组排序