Spring-data-jpa 学习笔记(二)
2024-10-19 01:33:37
通过上一篇笔记的,我们掌握了SpringData的相关概念及简单的用法。但上一篇笔记主要讲的是Dao层接口直接继承Repository接口,然后再自己定义方法。主要阐述了自定义方法时的一些规则及SpringData是如何来解析这些方法的。实际上,一些常用的方法SpringData已经帮我们定义好了,我们只需要定义Dao层接口时继承Repository的有相关功能子接口就ok了。本文主要讲的是Repository各个子接口有什么功能,了解了子接口的功能后,后续开发dao层就方便了。
这里再强调一下使用SpringData开发Dao层的步骤,这个步骤很关键。下面这段话是从上一篇笔记中copy过来的
Spring Data JPA 进行持久层(即Dao)开发一般分三个步骤:
- 声明持久层的接口,该接口继承 Repository(或Repository的子接口,其中定义了一些常用的增删改查,以及分页相关的方法)。
- 在接口中声明需要的业务方法。Spring Data 将根据给定的策略生成实现代码。
- 在 Spring 配置文件中增加一行声明,让 Spring 为声明的接口创建代理对象。配置了 <jpa:repositories> 后,Spring 初始化容器时将会扫描 base-package 指定的包目录及其子目录,为继承 Repository 或其子接口的接口创建代理对象,并将代理对象注册为 Spring Bean,业务层便可以通过 Spring 自动封装的特性来直接使用该对象。
一、Repository子接口相关概述
先来看下面一张图,大概能了解Repository接口的继承体系

下面阐述下常用的Repository的子接口
- CrudRepository:继承Repository接口,新增了一组CRUD相关的方法
- PagingAndSortingRepository:继承CrudRepository接口,新增了一组分页排序的相关方法
- JpaRepository:继承PagingAndSortRepository接口,新增了一组JPA规范的方法
有个不属于Repository继承体系的接口,也比较常用,它就是JpaSpecificationExecutor
- JpaSpecificationExecutor:不属于Repository继承体系,有一组JPA Criteria查询相关方法
二、CrudRepository接口介绍
首先我们看下这个接口的代码,代码如下,它定义好了一组CRUD的方法,共11个。
@NoRepositoryBean
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
<S extends T> S save(S entity); //保存
<S extends T> Iterable<S> save(Iterable<S> entities);//批量保存
T findOne(ID id); //根据id查询一个对象
boolean exists(ID id); //判断对象是否存在
Iterable<T> findAll(); //查询所有的对象
Iterable<T> findAll(Iterable<ID> ids);//根据id列表查询所有的对象
long count(); //计算对象的总个数
void delete(ID id); //根据id删除
void delete(T entity); //删除对象
void delete(Iterable<? extends T> entities);//批量删除
void deleteAll(); //删除所有
}14
1
@NoRepositoryBean
2
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
3
<S extends T> S save(S entity); //保存
4
<S extends T> Iterable<S> save(Iterable<S> entities);//批量保存
5
T findOne(ID id); //根据id查询一个对象
6
boolean exists(ID id); //判断对象是否存在
7
Iterable<T> findAll(); //查询所有的对象
8
Iterable<T> findAll(Iterable<ID> ids);//根据id列表查询所有的对象
9
long count(); //计算对象的总个数
10
void delete(ID id); //根据id删除
11
void delete(T entity); //删除对象
12
void delete(Iterable<? extends T> entities);//批量删除
13
void deleteAll(); //删除所有
14
}
下面还是通过一个案例来介绍下这个接口里面方法的使用,项目的搭建就不介绍了,还是使用上一篇笔记搭建好的项目。
- 为了和上一篇笔记的代码区分开,这里新建一个实体类User。这个实体类的属性如下图
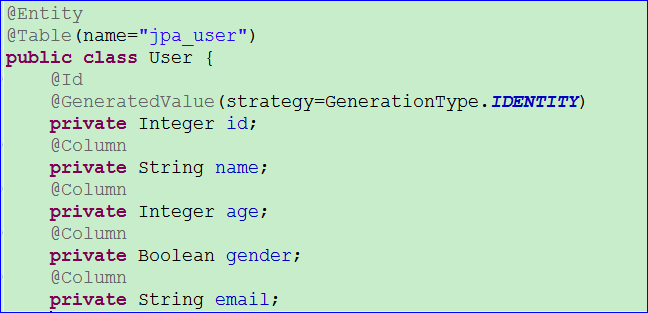
- Dao层接口定义如下,直接继承CrudRepository接口即可

- 测试类代码如下,首先我测试了批量保存方法,向数据库插入了26条数据。后面又测试了保存方法,发现这个保存方法可以起更新的作用的,类似于JPA中EntityManage的merge方法
/** 测试CrudRepository的批量save方法 */
@Test
public void testCrudRepositorySaveMethod(){
UserDao dao = ctx.getBean(UserDao.class);
List<User> list = new ArrayList<>();
for (int i = 'A'; i <= 'Z'; i++) {
User u = new User();
u.setName((char)i + "" + (char)i); // AA,BB这种
u.setGender(true);
u.setAge(i + 1);
u.setEmail(u.getName() + "@163.com");
list.add(u);
}
// 调用dao的批量保存
dao.save(list);
}
/** 测试CrudRepository的save */
@Test
public void testCrudRepositoryUpdate(){
UserDao dao = ctx.getBean(UserDao.class);
// 从数据库查出来
User user = dao.findOne(1);
// 修改名字
user.setName("Aa");
dao.save(user); // 经过测试发现,有id时是更新,但不是绝对的;类似jpa的merge方法
}27
1
/** 测试CrudRepository的批量save方法 */
2
@Test
3
public void testCrudRepositorySaveMethod(){
4
UserDao dao = ctx.getBean(UserDao.class);
5
List<User> list = new ArrayList<>();
6
for (int i = 'A'; i <= 'Z'; i++) {
7
User u = new User();
8
u.setName((char)i + "" + (char)i); // AA,BB这种
9
u.setGender(true);
10
u.setAge(i + 1);
11
u.setEmail(u.getName() + "@163.com");
12
list.add(u);
13
}
14
// 调用dao的批量保存
15
dao.save(list);
16
}
17
18
/** 测试CrudRepository的save */
19
@Test
20
public void testCrudRepositoryUpdate(){
21
UserDao dao = ctx.getBean(UserDao.class);
22
// 从数据库查出来
23
User user = dao.findOne(1);
24
// 修改名字
25
user.setName("Aa");
26
dao.save(user); // 经过测试发现,有id时是更新,但不是绝对的;类似jpa的merge方法
27
}
三、PagingAndSortingRepository接口介绍
先通过观察源码可知,这个接口继承CrudRepository接口,它新增了一组分页和排序的方法。源码如下
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID extends Serializable> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort); // 不带分页的排序
Page<T> findAll(Pageable pageable); // 带分页的排序
}5
1
@NoRepositoryBean
2
public interface PagingAndSortingRepository<T, ID extends Serializable> extends CrudRepository<T, ID> {
3
Iterable<T> findAll(Sort sort); // 不带分页的排序
4
Page<T> findAll(Pageable pageable); // 带分页的排序
5
}
下面通过一个案例讲解这个接口中方法的使用
- 首先Dao层改一下,把继承的接口改为PagingAndSortingRepository

- 单元测试的代码如下,这里只测试了带分页和排序的那个方法,不带分页的那个方法就不测试了;这里的重点是参数怎么传。而且springdata的分页时,页码是从0开始的,这点要特别注意。
/** 测试PagingAndSortingRepositoryd的分页且排序方法 */
@Test
public void testPagingAndSortingRepository() {
UserDao userDao = ctx.getBean(UserDao.class);
/* 需求:查询第3页的数据,每页5条 */
int page = 3 - 1; //由于springdata默认的page是从0开始,所以减1
int size = 5;
//Pageable 接口通常使用的其 PageRequest 实现类. 其中封装了需要分页的信息
//排序相关的. Sort 封装了排序的信息
//Order 是具体针对于某一个属性进行升序还是降序.
Order order1 = new Order(Direction.DESC, "id");//按id降序
Order order2 = new Order(Direction.ASC, "age");//按age升序
Sort sort = new Sort(order1,order2);
Pageable pageable = new PageRequest(page, size,sort);
Page<User> result = userDao.findAll(pageable);
System.out.println("总记录数: " + result.getTotalElements());
System.out.println("当前第几页: " + (result.getNumber() + 1));
System.out.println("总页数: " + result.getTotalPages());
System.out.println("当前页面的 List: " + result.getContent());
System.out.println("当前页面的记录数: " + result.getNumberOfElements());
System.out.println("当前的user对象的结果如下:");
for (User user : result.getContent()) {
System.out.println(user.getId() + " == " + user.getAge());
}
}27
1
/** 测试PagingAndSortingRepositoryd的分页且排序方法 */
2
@Test
3
public void testPagingAndSortingRepository() {
4
UserDao userDao = ctx.getBean(UserDao.class);
5
/* 需求:查询第3页的数据,每页5条 */
6
int page = 3 - 1; //由于springdata默认的page是从0开始,所以减1
7
int size = 5;
8
//Pageable 接口通常使用的其 PageRequest 实现类. 其中封装了需要分页的信息
9
//排序相关的. Sort 封装了排序的信息
10
//Order 是具体针对于某一个属性进行升序还是降序.
11
Order order1 = new Order(Direction.DESC, "id");//按id降序
12
Order order2 = new Order(Direction.ASC, "age");//按age升序
13
Sort sort = new Sort(order1,order2);
14
15
Pageable pageable = new PageRequest(page, size,sort);
16
Page<User> result = userDao.findAll(pageable);
17
18
System.out.println("总记录数: " + result.getTotalElements());
19
System.out.println("当前第几页: " + (result.getNumber() + 1));
20
System.out.println("总页数: " + result.getTotalPages());
21
System.out.println("当前页面的 List: " + result.getContent());
22
System.out.println("当前页面的记录数: " + result.getNumberOfElements());
23
System.out.println("当前的user对象的结果如下:");
24
for (User user : result.getContent()) {
25
System.out.println(user.getId() + " == " + user.getAge());
26
}
27
}
- 运行测试方法,生成的sql和结果如下图


四、JpaRepository接口介绍
这个接口继承了PagingAndSortingRepository接口,所以开发中一般都会继承它,它功能多一点。源码如下
@NoRepositoryBean
public interface JpaRepository<T, ID extends Serializable>
extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll(); //查询方法
List<T> findAll(Sort sort); //查询方法,带排序
List<T> findAll(Iterable<ID> ids); //查询方法,参数为id集合
<S extends T> List<S> save(Iterable<S> entities); //批量保存
void flush(); //刷新
<S extends T> S saveAndFlush(S entity); //保存并刷新,类似merge方法
void deleteInBatch(Iterable<T> entities);
void deleteAllInBatch();
T getOne(ID id);
<S extends T> List<S> findAll(Example<S> example); //根据“example”查找,参考:http://www.cnblogs.com/rulian/p/6533109.html
<S extends T> List<S> findAll(Example<S> example, Sort sort); // 根据“example”查找并排序
}16
1
@NoRepositoryBean
2
public interface JpaRepository<T, ID extends Serializable>
3
extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
4
5
List<T> findAll(); //查询方法
6
List<T> findAll(Sort sort); //查询方法,带排序
7
List<T> findAll(Iterable<ID> ids); //查询方法,参数为id集合
8
<S extends T> List<S> save(Iterable<S> entities); //批量保存
9
void flush(); //刷新
10
<S extends T> S saveAndFlush(S entity); //保存并刷新,类似merge方法
11
void deleteInBatch(Iterable<T> entities);
12
void deleteAllInBatch();
13
T getOne(ID id);
14
<S extends T> List<S> findAll(Example<S> example); //根据“example”查找,参考:http://www.cnblogs.com/rulian/p/6533109.html
15
<S extends T> List<S> findAll(Example<S> example, Sort sort); // 根据“example”查找并排序
16
}
下面还是通过一个案例来实践一下这个接口的部分方法。
- dao层,把继承的接口修改一下就ok,见下图

- 单元测试代码如下
/** 测试JpaRepository的SaveAndFlush */
@Test
public void testJpaRepositorySaveAndFlush() {
UserDao userDao = ctx.getBean(UserDao.class);
User user = new User();
user.setId(30); // id为30的话,不在数据库中。如果在数据库中,下面则是更新
user.setAge(27);
user.setName("testSaveAndFlush");
User user2 = userDao.saveAndFlush(user);
System.out.println("user==user2:" + (user == user2));
System.out.println("user.id=" + user.getId());
System.out.println("user2.id=" + user2.getId());
}15
1
/** 测试JpaRepository的SaveAndFlush */
2
@Test
3
public void testJpaRepositorySaveAndFlush() {
4
UserDao userDao = ctx.getBean(UserDao.class);
5
User user = new User();
6
user.setId(30); // id为30的话,不在数据库中。如果在数据库中,下面则是更新
7
user.setAge(27);
8
user.setName("testSaveAndFlush");
9
10
User user2 = userDao.saveAndFlush(user);
11
System.out.println("user==user2:" + (user == user2));
12
System.out.println("user.id=" + user.getId());
13
System.out.println("user2.id=" + user2.getId());
14
15
}
- 运行结果得好好说一下。运行该方法,发现id为30的记录不在数据库中,则新增一条记录,把属性值copy过去,保存到数据库。截图如下所示,从sql语句可以看出是先查询然后新增

- 当我们把测试代码中按下图修改下,再运行。则发现id在数据库中存在,就更新。测试代码及结果见下图
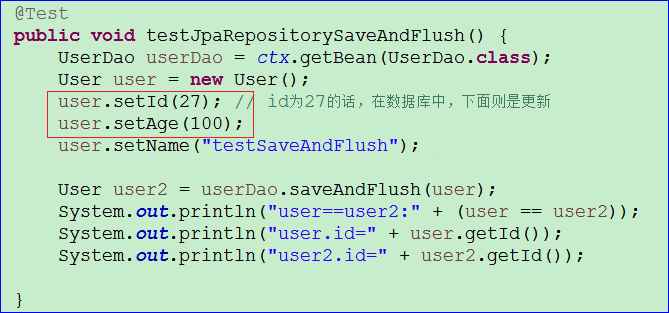
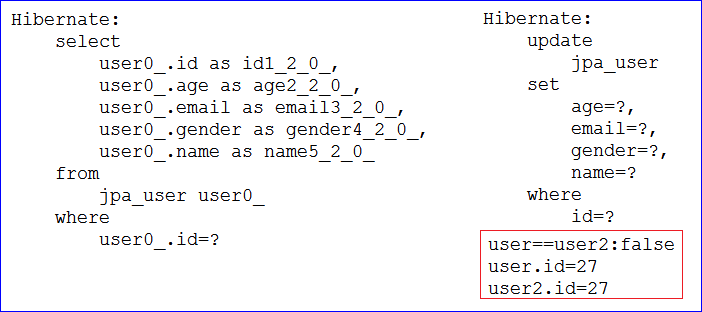
总结下saveAndFlush方法:
- 功能和jpa的EntityManage的merge方法是一致的,如果对象的id在数据库存在,则是更新;如果不存在则是保存
- 返回的对象和原来的对象之所以不相等时因为返回的是持久化对象的引用。也就是返回的是一级缓存中对象的引用。
- 欲实现user等于user2的话,则可以这样玩:
- 在service层定义一方法,开始事务;
- 方法第一步从数据库查询出id为27的user实体,然后修改一个属性,这个user实体此时是在一级缓存中的。
- 方法的第二步是saveAndFlush这个user实体,返回一个user2实体,这个user2实体就是一级缓存中的那个user实体。
- 比较user和user2的地址,你会发现结果是true;但是我们一般也不会去刻意比较这2个对象。之所以在这个解释这个返回值,可能也是由于笔者有强迫症。
五、JpaSpecificationExecutor接口介绍
这个接口不属于Repository体系,定义了一组JPA Criteria查询的方法,其源码如下所示。
public interface JpaSpecificationExecutor<T> {
T findOne(Specification<T> spec);
List<T> findAll(Specification<T> spec);
Page<T> findAll(Specification<T> spec, Pageable pageable); //条件查询,且支持分页
List<T> findAll(Specification<T> spec, Sort sort);
long count(Specification<T> spec);
}x
1
public interface JpaSpecificationExecutor<T> {
2
3
T findOne(Specification<T> spec);
4
List<T> findAll(Specification<T> spec);
5
Page<T> findAll(Specification<T> spec, Pageable pageable); //条件查询,且支持分页
6
List<T> findAll(Specification<T> spec, Sort sort);
7
long count(Specification<T> spec);
8
}
下面还是通过一个案例来实践一下这个接口中的部分方法
- dao层做了小小的改动,继承JpaRepository的同时也继承JpaSpecificationExecutor,具体见下图

- 测试代码如下,这个测试的是 Page<T> findAll(Specification<T> spec, Pageable pageable) 这个方法
/**
* 目标: 实现带查询条件的分页. id > 3 的条件
* 调用 JpaSpecificationExecutor 的 Page<T> findAll(Specification<T> spec, Pageable pageable);
* Specification: 封装了 JPA Criteria 查询的查询条件
* Pageable: 封装了请求分页的信息: 例如 pageNo, pageSize, Sort
*/
@Test
public void testJapSpecificationExecutor() {
// 目标:查询id>3 的第3页的数据,页大小为5
UserDao userDao = ctx.getBean(UserDao.class);
Pageable pageable = new PageRequest(3 - 1, 5);
//通常使用 Specification 的匿名内部类
Specification<User> spec = new Specification<User>() {
/**
* @param root: 代表查询的实体类.
* @param query: 可以从中可到 Root 对象, 即告知 JPA Criteria 查询要查询哪一个实体类. 还可以
* 来添加查询条件, 还可以结合 EntityManager 对象得到最终查询的 TypedQuery 对象.
* @param cb: CriteriaBuilder 对象. 用于创建 Criteria 相关对象的工厂. 当然可以从中获取到 Predicate 对象
* @return: Predicate 类型, 代表一个查询条件.
*/
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
// 一般用root和cb就ok了
return cb.gt(root.get("id"), 3);
// 多条件查询的案例
/*List<Predicate> predicates = new ArrayList<>();
Predicate p1 = cb.notEqual(root.get("id"), 15);
Predicate p2 = cb.like(root.get("email"),"%163.com");
predicates.add(p1);
predicates.add(p2);
// 即使predicates集合里面没元素,也能查询,就变成了查全部
return cb.and(predicates.toArray(new Predicate[predicates.size()]));*/
}
};
Page<User> list = userDao.findAll(spec, pageable);
for (User user : list) {
System.out.println(user);
}
}1
/**
2
* 目标: 实现带查询条件的分页. id > 3 的条件
3
* 调用 JpaSpecificationExecutor 的 Page<T> findAll(Specification<T> spec, Pageable pageable);
4
* Specification: 封装了 JPA Criteria 查询的查询条件
5
* Pageable: 封装了请求分页的信息: 例如 pageNo, pageSize, Sort
6
*/
7
@Test
8
public void testJapSpecificationExecutor() {
9
// 目标:查询id>3 的第3页的数据,页大小为5
10
UserDao userDao = ctx.getBean(UserDao.class);
11
Pageable pageable = new PageRequest(3 - 1, 5);
12
//通常使用 Specification 的匿名内部类
13
Specification<User> spec = new Specification<User>() {
14
/**
15
* @param root: 代表查询的实体类.
16
* @param query: 可以从中可到 Root 对象, 即告知 JPA Criteria 查询要查询哪一个实体类. 还可以
17
* 来添加查询条件, 还可以结合 EntityManager 对象得到最终查询的 TypedQuery 对象.
18
* @param cb: CriteriaBuilder 对象. 用于创建 Criteria 相关对象的工厂. 当然可以从中获取到 Predicate 对象
19
* @return: Predicate 类型, 代表一个查询条件.
20
*/
21
@Override
22
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
23
// 一般用root和cb就ok了
24
return cb.gt(root.get("id"), 3);
25
// 多条件查询的案例
26
/*List<Predicate> predicates = new ArrayList<>();
27
Predicate p1 = cb.notEqual(root.get("id"), 15);
28
Predicate p2 = cb.like(root.get("email"),"%163.com");
29
predicates.add(p1);
30
predicates.add(p2);
31
// 即使predicates集合里面没元素,也能查询,就变成了查全部
32
return cb.and(predicates.toArray(new Predicate[predicates.size()]));*/
33
}
34
};
35
36
Page<User> list = userDao.findAll(spec, pageable);
37
for (User user : list) {
38
System.out.println(user);
39
}
40
}
- 运行后生成的sql语句和结果如下图
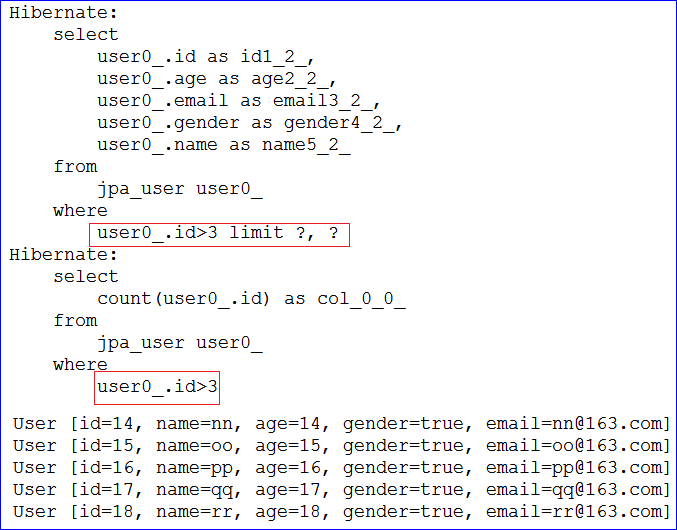
通过JpaSpecificationExecutor接口中的方法,就可以实现带分页的条件查询了。弥补了JpaRepository中的分页方法中不能带条件查询的缺点。
六、本文小结
写完本文,感觉自己写作水平真的是有待提高,很多东西没描述清楚。本文主要概述了Repository各个子接口有什么功能。通过了解这些子接口的功能,在开发dao层时就可以根据你所需要的功能继承有相应功能的Repository的子接口。省去了自己去定义方法这一步,提高了开发效率。本文还介绍了一个不是Repository继承体系的接口JpaSpecificationExecutor,该接口弥补了分页查询时不能条件查询的缺点。
一般在开发中,dao层的接口都是直接继承JpaRepository这个接口,这个接口已经有了开发中常用的功能。
下一篇spring-data-jpa的笔记应该是讲怎么自定义dao层方法的实现,但由于时间关系,暂时不往下写了。待我在工作中实际用到了那部分知识时再撰写该笔记, 未完待续。。。
最新文章
- 解决Java接口内部类的main()方法无法打印输出的问题
- wps使用技巧
- laravel administrator 一款通用的后台插件(PHP框架扩展)
- DOM--2 创建可重用的对象
- (C/C++ interview) Static 详解
- [转]AngularJS: 使用Scope时的6个陷阱
- JavaScript 变量、作用域及内存详解
- Android 开机动画启动过程详解
- AjaxManager的实现
- Warning: Cannot modify header information - headers already sent by (output started at
- 一个小团队TDD游戏及实践
- 自定义Git之忽略特殊文件
- cocos2dx - tmx地图分层移动处理
- angular组件
- 在SQL注入中利用MySQL隐形的类型转换绕过WAF检测
- Lua基础之MetaTable(6)
- 如何查看Unity的版本
- redis使用rdb恢复数据
- sourcetree删除github远程仓库文件
- Git Windows客户端保存用户名和密码