ubuntu16.04搭建hadoop集群环境
1. 系统环境
Oracle VM VirtualBox
Ubuntu 16.04
Hadoop 2.7.4
Java 1.8.0_111
master:192.168.19.128
slave1:192.168.19.129
slave2:192.168.19.130
2. 部署步骤
在虚拟机环境中安装三台Ubuntu 16.04虚拟机,在这三台虚拟机中配置一下基础配置
2.1 基础配置
1、安装 ssh和openssh
sudo apt-get install ssh
sudo apt-get install rsync
2、添加 hadoop 用户,并添加到 sudoers
sudo adduser hadoop
sudo vim /etc/sudoers
添加如下:
# User privilege specification
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) ALL
3、切换到 hadoop 用户:
su hadoop
4、修改 /etc/hostname
sudo vim /etc/hostname
将内容修改为master/slave1/slave2
5、修改 /etc/hosts
127.0.0.1 localhost
127.0.1.1 localhost.localdomain localhost
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
# hadoop nodes
192.168.19.128 master
192.168.19.129 slave1
192.168.19.130 slave2
6、安装配置 Java 环境
下载 jdk1.8 解压到 /usr/local 目录下(为了保证所有用户都能使用),修改 /etc/profile,并生效:
# set jdk classpath
export JAVA_HOME=/usr/local/jdk1.8.0_111
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
重新加载文件
source /etc/profile
验证 jdk 是否安装配置成功
hadoop@master:~$ java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
2.2 配置 master 节点可通过 SSH 无密码访问 slave1 和 slave2 节点
1.生成公钥
hadoop@master:~$ ssh-keygen -t rsa
2.配置公钥
hadoop@master:~$ cat .ssh/id_rsa.pub >> .ssh/authorized_keys
将生成的 authorized_keys 文件复制到 slave1 和 slave2 的 .ssh目录下
scp .ssh/authorized_keys hadoop@slave1:~/.ssh
scp .ssh/authorized_keys hadoop@slave2:~/.ssh
3.master 节点无密码访问 slave1 和 slave2 节点
hadoop@master:~$ ssh slave1
hadoop@master:~$ ssh slave2
输出:
hadoop@master:~$ ssh slave1
Welcome to Ubuntu 16.04.1 LTS (GNU/Linux 4.4.0-31-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Last login: Mon Nov 28 03:30:36 2016 from 192.168.19.1
hadoop@slave1:~$
2.3 Hadoop 2.7集群部署
1、在master机器上,在hadoop 用户目录下解压下载的 hadoop-2.7.4.tar.gz到用户目录下的software目录下
hadoop@master:~/software$ ll
total 205436
drwxrwxr-x 4 hadoop hadoop 4096 Nov 28 02:52 ./
drwxr-xr-x 6 hadoop hadoop 4096 Nov 28 03:58 ../
drwxr-xr-x 11 hadoop hadoop 4096 Nov 28 04:14 hadoop-2.7.4/
-rw-rw-r-- 1 hadoop hadoop 210343364 Apr 21 2015 hadoop-2.7.4.tar.gz
2、配置 hadoop 的环境变量
sudo vim /etc/profile
配置如下:
# set hadoop classpath
export HADOOP_HOME=/home/hadoop/software/hadoop-2.7.4
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_PREFIX=$HADOOP_HOME
export CLASSPATH=$CLASSPATH:.:$HADOOP_HOME/bin
加载配置
source /etc/profile
3、配置 hadoop 的配置文件,主要配置 core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 文件
1>配置/home/hadoop/software/hadoop-2.7.4/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- master: /etc/hosts 配置的域名 master -->
<value>hdfs://master:9000/</value>
</property>
</configuration>
2>配置/home/hadoop/software/hadoop-2.7.4/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/software/hadoop-2.7.4/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/software/hadoop-2.7.4/dfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
</configuration>
3>配置/home/hadoop/software/hadoop-2.7.4/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>matraxa:9001</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
4>配置/home/hadoop/software/hadoop-2.7.4/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
4、修改env环境变量文件,为 /home/hadoop/software/hadoop-2.7.4/etc/hadoop/hadoop-env.sh、mapred-env.sh、yarn-env.sh 文件添加 JAVA_HOME
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.8.0_111/
5、配置 slaves 文件
slave1
slave2
6、 向 slave1 和 slave2 节点复制 hadoop2.7.4 整个目录至相同的位置
hadoop@master:~/software$ scp -r hadoop-2.7.4/ slave1:~/software
hadoop@master:~/software$ scp -r hadoop-2.7.4/ slave2:~/software
至此,所有的配置已经完成,准备启动hadoop服务。
2.4 从master机器启动hadoop集群服务
1、初始格式化文件系统 bin/hdfs namenode -format
hadoop@master:~/software/hadoop-2.7.4$ ./bin/hdfs namenode -format
输出 master/192.168.19.128 节点的 NameNode has been successfully formatted.
......
16/11/28 05:10:56 INFO common.Storage: Storage directory /home/hadoop/software/hadoop-2.7.0/dfs/namenode has been successfully formatted.
16/11/28 05:10:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
16/11/28 05:10:56 INFO util.ExitUtil: Exiting with status 0
16/11/28 05:10:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.19.128
************************************************************/
2、启动 Hadoop 集群 start-all.sh
hadoop@master:~/software/hadoop-2.7.4$ ./sbin/start-all.sh
输出结果:
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /home/hadoop/software/hadoop-2.7.0/logs/hadoop-hadoop-namenode-master.out
slave2: starting datanode, logging to /home/hadoop/software/hadoop-2.7.0/logs/hadoop-hadoop-datanode-slave2.out
slave1: starting datanode, logging to /home/hadoop/software/hadoop-2.7.0/logs/hadoop-hadoop-datanode-slave1.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /home/hadoop/software/hadoop-2.7.0/logs/hadoop-hadoop-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/software/hadoop-2.7.0/logs/yarn-hadoop-resourcemanager-master.out
slave2: starting nodemanager, logging to /home/hadoop/software/hadoop-2.7.0/logs/yarn-hadoop-nodemanager-slave2.out
slave1: starting nodemanager, logging to /home/hadoop/software/hadoop-2.7.0/logs/yarn-hadoop-nodemanager-slave1.out
3、jps 输出运行的 java 进程:
hadoop@master:~$ jps
输出结果:
26546 ResourceManager
26372 SecondaryNameNode
27324 Jps
26062 NameNode
4、浏览器查看 HDFS:http://192.168.19.128:50070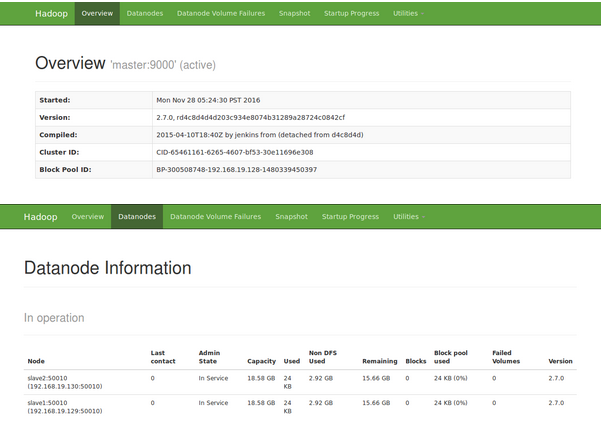
5、浏览器查看 mapreduce:http://192.168.19.128:8088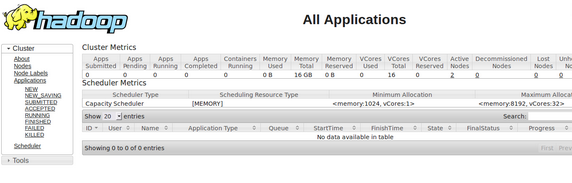
注意:在 hdfs namenode -format 或 start-all.sh 运行 HDFS 或 Mapreduce 无法正常启动时(master节点或 slave 节点),可将 master 节点和 slave 节点目录下的 dfs、logs、tmp 等目录删除,重新 hdfs namenode -format,再运行 start-all.sh
2.5 停止hadoop集群服务
hadoop@master:~/software/hadoop-2.7.4$ ./sbin/stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
master: stopping namenode
slave2: stopping datanode
slave1: stopping datanode
Stopping secondary namenodes [master]
master: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
slave2: stopping nodemanager
slave1: stopping nodemanager
no proxyserver to stop
最新文章
- 《Entity Framework 6 Recipes》中文翻译系列 (36) ------ 第六章 继承与建模高级应用之TPC继承映射
- Apache Commons 常用工具类整理
- 【Java】Map杂谈,hashcode()、equals()、HashMap、TreeMap、LinkedHashMap、ConcurrentHashMap
- 为什么开发者热衷在Stack Overflow上查阅API文档?
- MathType需要安装一个较新版本的MT Extra(True type)字体[转]
- 【Android - 框架】之ButterKnife的使用
- bzoj 1089 [SCOI2003]严格n元树(DP+高精度)
- Binders 与 Window Tokens(窗体令牌)
- lumen的自定义依赖注入
- Gradle 1.12用户指南翻译——第四十三章. 构建公告插件
- Python爬虫入门教程 60-100 python识别验证码,阿里、腾讯、百度、聚合数据等大公司都这么干
- Linux远程登录ssh免密码配置方法(仅供参考)
- 撸一个小型PHP框架
- excle删除重复项的行,自定义删除第几个
- [EasyUI]确认删除
- Wechart 饼图
- Flex自定义组件、皮肤,并调用
- WinForm如何去掉右边和下边的白边
- Openssl pkeyutl命令
- mysql表、函数等被锁住无响应的问题