python利用(threading,ThreadPoolExecutor.map,ThreadPoolExecutor.submit) 三种多线程方式处理 list数据
2024-08-30 00:03:00
需求:在从银行数据库中取出 几十万数据时,需要对 每行数据进行相关操作,通过pandas的dataframe发现数据处理过慢,于是 对数据进行 分段后 通过 线程进行处理;
如下给出 测试版代码,通过 list 分段模拟 pandas 的 dataframe ;
1.使用 threading模块
# -*- coding: utf-8 -*-
# (C) Guangcai Ren <renguangcai@jiaaocap.com>
# All rights reserved
# create time '2019/6/26 14:41'
import math
import random
import time
from threading import Thread _result_list = [] def split_df():
# 线程列表
thread_list = []
# 需要处理的数据
_l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 每个线程处理的数据大小
split_count = 2
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
# 线程相关处理
thread = Thread(target=work, args=(item, _list,))
thread_list.append(thread)
# 在子线程中运行任务
thread.start()
count += split_count # 线程同步,等待子线程结束任务,主线程再结束
for _item in thread_list:
_item.join() def work(df, _list):
""" 线程执行的任务,让程序随机sleep几秒 :param df:
:param _list:
:return:
"""
sleep_time = random.randint(1, 5)
print(f'count is {df},sleep {sleep_time},list is {_list}')
time.sleep(sleep_time)
_result_list.append(df) def use():
split_df() if __name__ == '__main__':
y = use()
print(len(_result_list), _result_list)
响应结果如下:
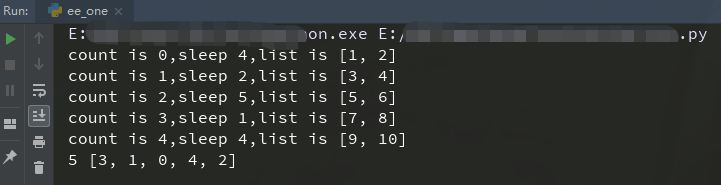
注意点:
脚本中的 _result_list 在项目中 要 放在 函数中,不能直接放在 路由类中,否则会造成 多次请求 数据 污染;
定义线程任务时 thread = Thread(target=work, args=(item, _list,)) 代码中的 work函数 和 参数 要分开,否则 多线程无效
注意线程数不能过多
2.使用ThreadPoolExecutor.map
# -*- coding: utf-8 -*-
# (C) Guangcai Ren <renguangcai@jiaaocap.com>
# All rights reserved
# create time '2019/6/26 14:41'
import math
import random
import time
from concurrent.futures import ThreadPoolExecutor def split_list():
# 线程列表
new_list = []
count_list = []
# 需要处理的数据
_l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 每个线程处理的数据大小
split_count = 2
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
new_list.append(_list)
count_list.append(count)
count += split_count
return new_list, count_list def work(df, _list):
""" 线程执行的任务,让程序随机sleep几秒 :param df:
:param _list:
:return:
"""
sleep_time = random.randint(1, 5)
print(f'count is {df},sleep {sleep_time},list is {_list}')
time.sleep(sleep_time)
return sleep_time, df, _list def use():
pool = ThreadPoolExecutor(max_workers=5)
new_list, count_list = split_list()
# map返回一个迭代器,其中的回调函数的参数 最好是可以迭代的数据类型,如list;如果有 多个参数 则 多个参数的 数据长度相同;
# 如: pool.map(work,[[1,2],[3,4]],[0,1]]) 中 [1,2]对应0 ;[3,4]对应1 ;其实内部执行的函数为 work([1,2],0) ; work([3,4],1)
# map返回的结果 是 有序结果;是根据迭代函数执行顺序返回的结果 # 使用map的优点是 每次调用回调函数的结果不用手动的放入结果list中
results = pool.map(work, new_list, count_list)
print(type(results))
# 如下2行 会等待线程任务执行结束后 再执行其他代码
for ret in results:
print(ret)
print('thread execute end!') if __name__ == '__main__':
use()
响应为:

3.使用 ThreadPoolExecutor.submit
# -*- coding: utf-8 -*-
# (C) Guangcai Ren <renguangcai@jiaaocap.com>
# All rights reserved
# create time '2019/6/26 14:41'
import math
import random
import time
from concurrent.futures import ThreadPoolExecutor # 线程池list
pool_list = [] def split_df(pool):
# 需要处理的数据
_l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 每个线程处理的数据大小
split_count = 2
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
# 线程相关处理
# submit方法提交可回调的函数,并返回一个future实例;future对象包含相关属性
# 如: done(函数是否执行完成),result(函数执行结果),running(函数是否正在运行)
# 从而 可以在submit 后的代码中 查看 相关任务运行情况
# 此方法 执行数据的结果是无序的,如果需要得到有序的结果,需要 for循环 每个future实例(线程池),如 此脚本代码
f = pool.submit(work, item, _list)
pool_list.append(f)
count += split_count def work(df, _list):
""" 线程执行的任务,让程序随机sleep几秒 :param df:
:param _list:
:return:
"""
sleep_time = random.randint(1, 5)
print(f'count is {df},sleep {sleep_time},list is {_list}')
time.sleep(sleep_time)
return sleep_time, df, _list def use():
pool = ThreadPoolExecutor(max_workers=5)
split_df(pool)
_result_list = []
for item in pool_list:
result_tuple = item.result()
_result_list.append(result_tuple[1])
return _result_list if __name__ == '__main__':
_result_list = use()
print(len(_result_list), _result_list)
结果如下:
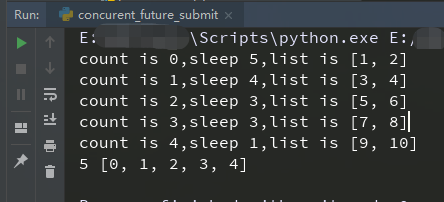
个人比较喜欢使用 第二中方法,代码写的少,返回的是有序结果,回调函数结果自动管理在generator中,直接for循环 map的结果即可;不用担心在 项目中多次请求数据污染问题
相关连接:
https://blog.csdn.net/dutsoft/article/details/54728706
最新文章
- 【续集】塞翁失马,焉知非福:由 Styles.Render 所引发 runAllManagedModulesForAllRequests="true" 的思考
- CCNET+MSBuild+SVN实现每日构建
- linux系统一键安装phpstudy的lnmp环境
- checkbox选中与取消选择
- Quartz任务调度快速入门
- iOS中判断消息推送是否打开
- 微软office MIME类型
- (10.20)Java小作业!
- mapper.xml 的配置
- Mittag-Leffer函数, Matlab内部函数
- C# 获取 sha256
- FreeSWITCH异常原因总结
- 申港集中运营平台Linux测试环境架构搭建
- java框架篇---hibernate之连接池
- quartz定时任务cron表达式详解
- 51nod 1835 - 完全图 - [dp][组合数公式][快速幂]
- #leetcode刷题之路48-旋转图像
- 通过pd.to_sql()将DataFrame写入Mysql
- 2017北京国庆刷题Day1 morning
- debian flam3 依赖文件