HashSet和HashMap
HashMap
概念和特征
概念:以键值对的形式存储数据,由键映射到值,核心在于Key上。
特征:键不能重复,值可以重复;key-value允许为null。
HashMap SinceJDK1.2 前身是HashTable(SinceJDK1.0)
HashMap 实现了Map接口
HashMap底层是一个Entry数组,当发生hash冲突(碰撞)的时候,HashMap是采用链表的方式来解决的,在对应的数组位置存放链表的头结点。对链表而言,新加入的节点会从头结点加入。
Key不能重复,判断是否重复的标准是:hashCode()和equals()方法, 如果hashCode相同并且equals相等就是一个重复的key。
注意:放入HashMap集合中的Key必须要覆盖Object类型的hashCode()和equals()方法,否则就会出现重复的Key。
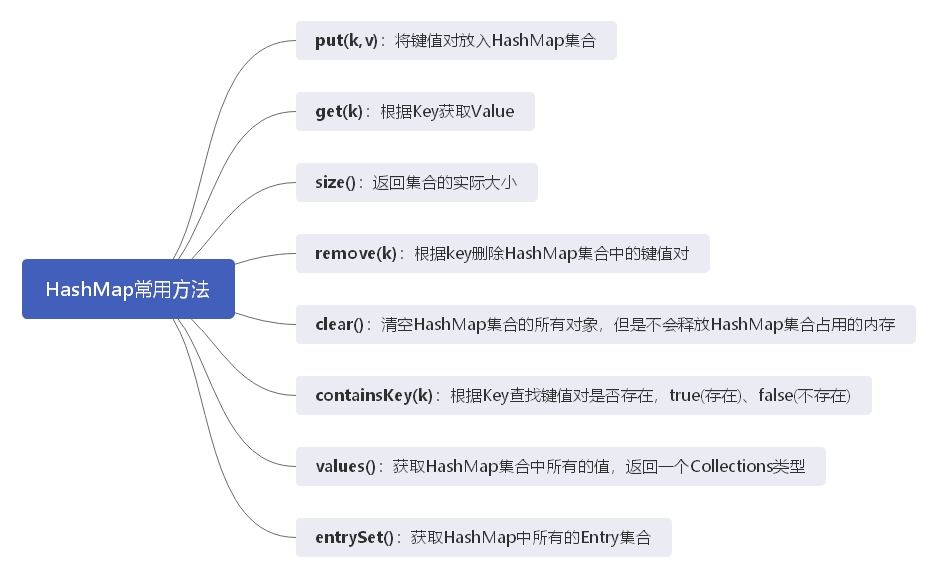
put()和get()方法
put(K,V):将键值对存储到HashMap中(放入) *
*get(K)**:根据Key获取Value,如果Key在HashMap中不存在返回null。
场景:创建HashMap对象,将元素放入HashMap,根据Key获取Value。
import java.util.HashMap;
import java.util.Map;
/**
* 场景:创建HashMap对象,将元素放入HashMap,根据Key获取Value
* 小结:HashMap的数据全部都放在{key1=value1,key2=value2...}中,以key=value的形式存放,如果有多个键值对使用逗号分隔
* HashMap与ArrayList不同,新元素放入集合中是无序的(根据Hash算法排序的)。
*/
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap对象,编译期是Map,运行期是HashMap
Map<String,String> map = new HashMap<>();
//调用put(k,v)方法将键值对放入集合 首都作为Key,国家作为Value
map.put("北京","中国");
map.put("伯尔尼","瑞士");
map.put("哈瓦那", "古巴");
map.put("太子港", "海地");
map.put("科威特城","科威特");
System.out.println(map);
//HashMap 集合没有ABC的Key,所以返回结果为null
//String value = map.get("ABC");
//System.out.println(value);
//海地
String value = map.get("太子港");
System.out.println(value);
}
}
其他方法
size():获取HashMap的实际元素大小。
remove(key):根据Key删除元素。
clear():清空HashMap所有元素,但是不会释放对象占用的内存。
containsKey(key):判断可以是否在HashMap存在,如果存在返回true,否则返回false。
import java.util.HashMap;
import java.util.Map;
/**
* 场景:创建HashMap对象,将元素放入HashMap,根据Key获取Value
* 小结:HashMap的数据全部都放在{key1=value1,key2=value2...}中,以key=value的形式存放,如果有多个键值对使用逗号分隔
* HashMap与ArrayList不同,新元素放入集合中是无序的(根据Hash算法排序的)。
*/
public class TestHashMap {
public static void main(String[] args) {
// 创建HashMap对象,编译期是Map,运行期是HashMap
Map<String,String> map = new HashMap<>();
// 调用put(k,v)方法将键值对放入集合 首都作为Key,国家作为Value
map.put("北京","中国");
map.put("伯尔尼","瑞士");
map.put("哈瓦那", "古巴");
map.put("太子港", "海地");
map.put("科威特城","科威特");
System.out.println(map);
// HashMap 集合没有ABC的Key,所以返回结果为null
// String value = map.get("ABC");
// System.out.println(value);
String value = map.get("太子港"); // 海地
System.out.println(value);
}
}
keySet():会返回集合中所有的Key。
values():返回集合中所有的值。
entrySet():获取HashMap中所有的Entry集合。
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 获取HashMap所有的Value
*/
public class TestHashMap3 {
public static void main(String[] args) {
//创建HashMap对象,编译期是Map,运行期是HashMap
Map<String,String> map = new HashMap<>();
//调用put(k,v)方法将键值对放入集合 首都作为Key,国家作为Value
map.put("北京","中国");
map.put("伯尔尼","瑞士");
map.put("哈瓦那", "古巴");
map.put("太子港", "海地");
map.put("科威特城","科威特");
System.out.println(map.size());
//Collection以及Collection下面的子类,数据以[]存储
//Map以及Map下面的子类,数据以{}存储
//[瑞士, 海地, 古巴, 科威特, 中国]
//返回HashMap集合所有的Value
Collection<String> values = map.values();
System.out.println(values);
//遍历Collection
for(String value: values) {
System.out.print(value+"\t");
}
}
}
遍历HashMap里面的元素
HashMap 可以理解为一张平面表,由两列多行组成。
场景:遍历HashMap集合的每个元素
package com.whsxt.day7.map;
import java.util.HashMap;
import java.util.Map;
/**
* @author caojie
*场景:遍历HashMap集合的每个元素
*/
public class TestHashMap4 {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("北京","中国");
map.put("伯尔尼","瑞士");
map.put("哈瓦那", "古巴");
map.put("太子港", "海地");
map.put("科威特城","科威特");
//map.entrySet() 获取HashMap中所有的Entry对象
//Map.Entry<String,String> entry 表示HashMap集合中的每一个Entry对象
//entry编译期是一个接口类型(Map.Entry),运行期是一个HashMap$Node类型
//遍历HashMap集合的每个元素,每个元素都以Entry类型存在
for(Map.Entry<String,String> entry : map.entrySet()) {
//获取HashMap 的key
String key =entry.getKey();
//获取Hash Map的Value
String value =entry.getValue();
System.out.println(key+"\t\t\t"+value);
}
}
}
HashMap和缓存
缓存特征:牺牲空间换取时间。
缓存是内存的一种形式:经常需要获取并且不轻易改变的数据就会放入缓存中,缓存中的数据只加载一次。
HashMap中的数据在工作中通常以缓存的形式存在,也就是说工作中HashMap通常当做缓存使用。
场景1:存储全国所有的城市信息,城市名称作为Key,城市相关的信息作为value[id,cityName,cityCode,cityDesc],要求根据Key,获取城市相关的信息
步骤:1. 创建一个缓存(HashMap),将所有的城市信息的加载工作放入static块
2. 提供一个公有的静态的方法给外界,外界可以根据Key获取缓存中的value信息
public class City {
private int id;
private String cityName;
/**
* 城市的区号
*/
private String cityCode;
/**
* 城市的描述(介绍信息)
*/
private String cityDesc;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getCityName() {
return cityName;
}
public void setCityName(String cityName) {
this.cityName = cityName;
}
public String getCityCode() {
return cityCode;
}
public void setCityCode(String cityCode) {
this.cityCode = cityCode;
}
public String getCityDesc() {
return cityDesc;
}
public void setCityDesc(String cityDesc) {
this.cityDesc = cityDesc;
}
public City() {}
public City(int id, String cityName, String cityCode, String cityDesc) {
super();
this.id = id;
this.cityName = cityName;
this.cityCode = cityCode;
this.cityDesc = cityDesc;
}
@Override
public String toString() {
return "City [id=" + id + ", cityName=" + cityName + ", cityCode=" + cityCode + ", cityDesc=" + cityDesc + "]";
}
}
定义缓存
import java.util.HashMap;
import java.util.Map;
/**
* 使用HashMap作为缓存
*/
public class CityCache {
/**
* 存储所有的城市信息
*/
private static Map<String,City> cityCache = new HashMap<>();
static {
cityCache.put("北京",new City(1, "北京","010","帝都"));
cityCache.put("上海",new City(2, "上海","021","魔都"));
cityCache.put("广州",new City(3, "广州","020","羊城"));
cityCache.put("深圳",new City(4, "深圳","0755","鹏程"));
cityCache.put("武汉",new City(5, "武汉","027","江城"));
}
/**
* 根据Key获取对应的城市信息
* @param key 城市的名称
* @return 城市相关的信息City
*/
public static City getCityByKey(String key) {
return cityCache.get(key);
}
}
使用缓存
public class TestCache {
public static void main(String[] args) {
// 获取缓存中的数据
/*
* 第一步:将CityCache加载到JVM
* 第二步:检查CityCache.class有没有静态数据,如果有初始化静态数据
* 第三步:调用静态方法getCityByKey(key)获取缓存中的数据
* 注意:静态方法调用之前缓存中所有的数据初始化完毕
* 缓存中的数据只会初始化一次,在第一次调用静态方法之前初始化
* 所以说:第一次调用静态方法相对较慢(加载静态数据),后面会很快
*/
City city = CityCache.getCityByKey("深圳");
System.out.println(city);
// 第二次调用静态方法不会初始化CityCache缓存中的数据
City city2 = CityCache.getCityByKey("广州");
System.out.println(city2);
}
}
场景2:使用HashMap作为缓存,来存储环境变量的信息,根据Key获取环境变量的值
import java.util.Map;
/**
* 环境变量的缓存
*/
public class EnvCache {
/**
* 获取系统所有的环境变量信息,存储到HashMap缓存中
*/
private static Map<String,String> envMap = System.getenv();
/**
* 遍历缓存中的每个键值对
*/
public static void iteratorEnv() {
for(Map.Entry<String,String> entry: envMap.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"\t\t\t"+value);
}
}
/**
* 根据Key获取环境变量对应的值
* @param key
* @return
*/
public static String getValueByKey(String key) {
return envMap.get(key);
}
}
获取缓存数据:
public class TestEnv {
public static void main(String[] args) {
// 遍历缓存的数据
// EnvCache.iteratorEnv();
// 根据Key获取对应的环境变量值
String value =EnvCache.getValueByKey("Path");
System.out.println(value);
}
}
补充:HashMap中的坑
import java.util.HashMap;
import java.util.Map;
/**
* HashMap的陷阱
*/
public class TestHashMapTrap {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
//HashMap键必须唯一,如果将相同的Key放入HashMap,后面的key-value会覆盖前面的key-value
map.put("北京","中国");
map.put("北京","CHINA");
map.put("北京","CHINESE");
// A.1 B.3 C.编译错误 D.编译成功,运行失败
System.out.println(map.size()); // 1
}
}
问题:为什么String作为HashMap的Key,不能重复,而Student作为HashMap的Key,却可以重复?
因为String定义了判断是否重复的逻辑,而Student没有。
String作为Key放入HashMap之前,会首先调用hashCode()方法,判断集合中有没有相同的hashCode,如果有相同的hashCode,然后再调用equals()方法,判断有没有相等的值,如果hashCode相同并且equals相等,说明有重复的Key,不会放入,只会将新的key-value对覆盖旧的key-value对。
以下代码:将Student作为Key,String作为Value,由于Student没有判断Key是否重复,所以size=2;
public class Student {
private int id;
private String stuName;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getStuName() {
return stuName;
}
public void setStuName(String stuName) {
this.stuName = stuName;
}
public Student() {}
public Student(int id, String stuName) {
this.id = id;
this.stuName = stuName;
}
@Override
public String toString() {
return "Student [id=" + id + ", stuName=" + stuName + "]";
}
}
import java.util.HashMap;
import java.util.Map;
/**
* HashMap的陷阱
*/
public class TestHashMapTrap {
public static void main(String[] args) {
//Student作为Key,String作为Value
Map<Student,String> map = new HashMap<>();
map.put(new Student(1,"Tom"), "Tom");
map.put(new Student(1,"Tom"), "Tom");
System.out.println(map.size()); // 2
System.out.println(map);
}
}
注意:HashMap中的Key必须要覆盖Object类型的hashCode()和equals()方法,这两个方法用来判断HashMap集合中是否存在相同的Key。
HashMap的存储机制
问题:HashMap集合中的key-value对没有规律(没有顺序),但是HashMap会根据Key的hashCode进行排序
HashMap 存储机制:第一次 put(k,v) 会初始化 Node[] table = new Node[16]; ,然后将 hashCode&table.length-1 作为数组的下标,最后创建 Node类型对象 , Node newNode = new Node(hash,key,value,null); 将newNode对象放入到table数组中,下标就是hashCode&table.length-1。
HashMap核心静态内部类Node,实现了Entry接口,每当你put元素到HashMap,都会创建一个Node对象
注意:1的hashCode为49
12的hashCode为1569
1和12的 hashCode& table.length-1 的索引下标都是1,就会造成hashCode码的碰撞,由于1是先put,12后put,那么将12放入到1的下一个节点中(一个槽中放入两个数值,单链表的形式存储)。
场景:将 "北京","中国"作为键值对放入HashMap集合。
步骤:1. 获取“北京”的hashCode ,hashCode 获取方式如下:(hashCode ^ (hashCode >>> 16))。
2. 检查内存表table[] 是否为空,如果第一次做put(k,v)操作,table就是null值,需要创建table[],然后分配空间,空间默认大小是16,默认负载因子是0.75,默认的阀值是12。
3. 如果是第一次put(k,v), 会创建一个静态内部类的对象Node,存储key的hashCode,key,value。
4. 需要将Node对象放入到table[]数组中,放到数组的那个slot(槽位)呢?
5. 将key的hashCode& table.length-1,得到槽位的索引下标。
6. 根据索引下表将Node对象放入到table[]数组中。
7. ++size。
8. 判断size有没有超过阀值(12),如果超过了就会重新扩容。
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
/**
* 默认容量 1<<4=16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
默认负载因子0.75
阀值=(int)DEFAULT_INITIAL_CAPACITY*DEFAULT_LOAD_FACTOR
超过阀值HashMap会自动扩容
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
}
HashSet(掌握)
HashSet的底层实际就是一个HashMap(是一个简化版的HashMap),因此,查询效率和增删效率都比较高。每当将新元素放入HashSet实际上是将新元素放入HashMap,key(键)必须唯一,值是一个哑巴值。
HashSet集合实现了Set接口,存储HashSet的值,不能重复。
注意:存储HashSet集合中的元素,必须覆盖Object类型的hashCode()方法和equals()方法,这样才能保证对象唯一。
HashSet常用方法
add():将元素(对象)放入容器
size():获取HashSet集合的元素大小
remove(obj):删除元素
import java.util.HashSet;
import java.util.Set;
public class TestHashSet {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("Tom");
set.add("Tom");
set.add("Tom");
set.add("Tom");
set.add("Tom");
System.out.println(set.size()); // 1
set.remove("Tom");
System.out.println(set.size()); // 0
}
}
HashSet特征:不会有重复的元素。
第一次调用add()方法将Tom放入HashSet集合,由于集合中没有元素直接放入。第二次调用add()方法将Tom放入HashSet集合,会判断有没有重复的Tom,如果没有就放入,如果有就不会放入,只会将新的Tom覆盖旧的Tom。判断元素是否重复的依据是hashCode()和equals()方法, hashCode相同并且equals()相等说明HashSet中有重复的元素。
元素不能重复,所以存储对象(元素)的信息使用ArrayList或者LinkedList,因为Set中的元素不能重复(例如:有可能班上有两个学生都叫做张三)。
HashSet元素之间缺乏联系,所以不能使用get()方法获取元素。
场景1:有一个ArrayList集合[1,2,2,3,5,7,7,8],需要将重复的元素清除掉
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class TestHashSet {
static List<Integer> list = new ArrayList<>();
static {
list.add(1);
list.add(2);
list.add(2);
list.add(3);
list.add(5);
list.add(5);
}
public static void main(String[] args) {
Set<Integer> set =new HashSet<>(list);
list.clear();
list.addAll(set);
System.out.println(list);
}
}
contains():判断元素是否在集合中存在,true存在,false不存在。
场景2:输入一个手机号码,判断该号码是否在HashSet集合中存在,如果存在就不执行后面的业务逻辑,如果不存在就下发垃圾短信。
import java.util.HashSet;
import java.util.Scanner;
import java.util.Set;
/**
* 白名单:将手机号码存入到白名单中,如果输入的手机号不在白名单就下发垃圾短信
* 1 创建HashSet对象
* 2 加载白名单
* 3 创建Scanner对象
* 4 输入手机号码
* 5 判断输入的手机号码是否在白名单中,如果不在下发短信
*/
public class TestHashSetWhite {
/**
* 存储白名单的HashSet
*/
private final static Set<String> MOBILE_SET= new HashSet<>();
static {
MOBILE_SET.add("15609898765");
MOBILE_SET.add("15609898761");
MOBILE_SET.add("15609898769");
}
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.println("请输入手机号码");
String mobile = input.nextLine();
//条件成立:手机号码不在白名单中,下发短信
if(!MOBILE_SET.contains(mobile)) {
System.out.println("下发短信。。。。。。。。。");
}else {
System.out.println("不下发短信");
}
}
}
注意:List集合和Set集合都有contains(key) 方法,但是List里面有重复的元素,所以调用该方法效率低下,工作中contains(key)方法,通常用于set集合。
最新文章
- iOS中文API之NSLayoutconstraint
- C# 生成中间含有LOGO的二维码
- Hadoop Mac OSX 安装笔记
- 同花顺面试经验(搜索引擎C++后台研发)
- shell中截取字符串的方法总结
- Tsinsen A1517. 动态树 树链剖分,线段树,子树操作
- 安装PyQt
- 5.JSON
- UITableViewCell实现3D缩放动画
- 【转】KVM/Installation
- java applet初探之计算器
- linux上安装tcl
- Day2 - Linux发展史
- javaScript之表格操作<一:新增行>
- django ---forms组件
- C++编程基础练习
- http Get和Post请求方式
- angularJS使用内置服务
- AE常用代码(标注要素、AE中画带箭头的线、如何获得投影坐标、参考坐标、投影方式、FeatureCount注意事项)
- java8新特性lamda表达式在集合中的使用