scrapy运行的整个流程
2024-09-02 09:53:49
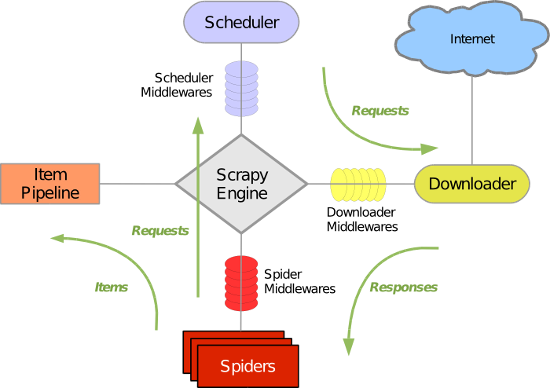
Spiders:
负责处理所有的response,从这里面分析提取数据,获取Item字段所需要的数据,并将需要跟进的URL提交给引擎,再次进入到Scheduler调度器中
Engine:
框架的核心,负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据的传递等
Scheduler:
它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理队列,当引擎需要的时候,交还给引擎
Downloader:
负责下载Engine发送过来的所有的requests请求,并将其获取到的response交还给Engine,由Engine交给Spider来进行处理
ItemPipeline:
它负责处理Spider中获取到的Item,并交给进行后期处理(详细分析、过滤、存储等)的地方
DownloaderMiddlewares(下载中间件):
介于Scrapy引擎和下载器之间的中间件,主要是处理Scrapy引擎与下载器之间的请求以及响应
SpiderMiddlewares(Spider中间件):
介于Scrapy引擎和爬虫之间的中间件,主要工作是处理蜘蛛的响应输入和请求输出
SchedulerMiddlewares(调度中间件):
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的响应和请求
执行顺序:
- Spider的yield将requests发送给Engine
- Engine对requests不做任何的处理就发送给Scheduler
- Scheduler(url调度器),生成requests交给Engine
- Engine拿到requests,通过middleware进行层层过滤发送给Downloader
- downloader在网上获取到response数据之后,又经过middleware进行层层过滤发送给Engine
- Engine获取到response之后,返回给Spider,Spider的parse()方法对获取到的response数据进行处理解析出items或者requests
- 将解析出来的items或者requests发送给Engine
- Engine获取到items或者requests,将items发送给ITEMPIPELINES,将requests发送给Scheduler
只有当调度器中不存在任何的requests的时候,整个程序才会停止(也就是说,对于下载失败的URL,scrapy也会重新进行下载)
1.引擎:Hi!Spider, 你要处理哪一个网站?
2.Spider:老大要我处理xxxx.com(初始URL)。
3.引擎:你把第一个需要处理的URL给我吧。
4.Spider:给你,第一个URL是xxxxxxx.com。
5.引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6.调度器:好的,正在处理你等一下。
7.引擎:Hi!调度器,把你处理好的request请求给我。
8.调度器:给你,这是我处理好的request
9.引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。
10.下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11.引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12.Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13.引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
14.管道、调度器:好的,现在就做!
开发Scrapy爬虫的步骤
- 创建项目:scrapy startproject 项目名称
- 明确目标:便携item,明确你要爬取的目标
- 制作爬虫:编写爬虫,开始爬取网页
- 存储内容:设计管道存储爬取内容
- 添加启动程序的文件:就是启动的main文件
parse方法的工作机制:
- 因为使用的是yield,而不是return。parse函数将会被当作一个生成器使用,scrapy回逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型
- 如果是requests则加入爬取队列,如果是item类型则使用Pipeline处理,其他的就返回错误信息
- scrapy取到第一部分的requests不会立马就去发送这个requests,只是把这个requests放到队列里,然后接着从生成器礼获取
- 取尽第一部分的requests,然后在获取第二部分的item,取到item之后,就会放到对应的pipeline里进行处理
- parse方法作为回调函数复制给了Request,指定parse方法来处理这些请求
- Request对象经过调度,执行生成scrapy.http.response()的响应对象,并送回给parse方法,直到调度器中没有Request(递归的思路)
- 取完之后,parse方法工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作
- 程序在取得各个页面的items之前,会先处理完之前所有的requests队列里的请求,然后在提取items
- 综上所述一切,scrapy引擎和调度器将会负责到底
最新文章
- 修改一个CGRect的值
- 动态规划求最长公共子序列(Longest Common Subsequence, LCS)
- 如何启动另一个应用的activity
- [DBW]大图轮播,可通过两种方法实现
- 基础学习day03---程序结构与控制、函数与数组入门
- hdu 2545(并查集求节点到根节点的距离)
- Android 中Fragment使用
- 大神眼中的React Native--备用
- c3p0写连接池 Demo
- 前端--关于javascript对象
- UVA 10375 Choose and divide
- wp如何代码实现锁屏
- Entity Framework技巧系列之一 - Tip 1 - 5
- Quartus14.1中Qsys无法更新custom component的问题
- JAVA对特殊的字符串进行html编码
- 2015阿里巴巴安全峰会PPT
- [Oracle]约束(constraint)
- 8.Vue基础
- 【爆料】-《伯明翰大学学院毕业证书》UCB一模一样原件
- Java开发知识之Java中的集合Set接口以及子类应用