爬虫实战 豆瓣音乐top250 xpath
刷知乎时刷到一篇爬取豆瓣音乐top250的,然后看了看,感觉自己的爬虫又更上一层楼了哈啊哈哈,尤其是发现xpath这么好用的东西。
不过也有一个感慨,就是有很多种方式都可以获得想要的数据,对于入门的新人来说着实有些不友好,明确不了方向
话不多说,先贴网站https://music.douban.com/top250
我们这时候看到的网页应该是这样的,以防以后发生变化

看了豆瓣那篇文章之后给我的一个启示就是先爬到一个自己需要的资源,如果成功了,然后就批量爬取剩下的资源。
这里我们就简单的爬取一下标题,评分和音乐链接好了
查看网页代码,然后选中标题所在的地方右键复制,如下图
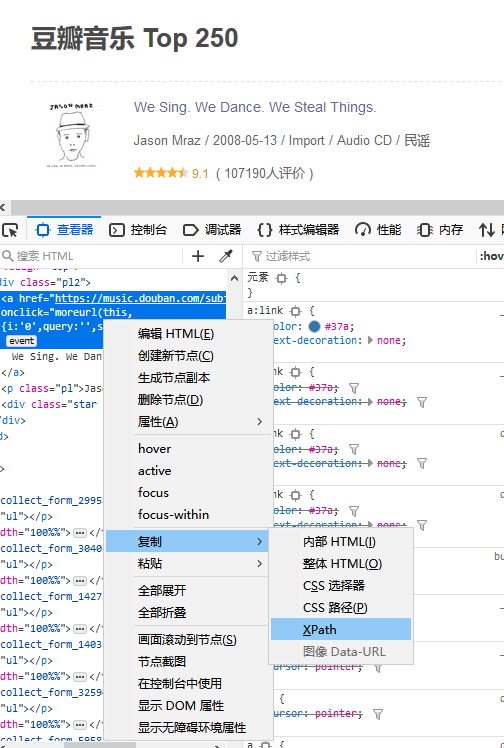
他会自动复制一个xpath
比如我拿到就得这个样子的/html/body/div[3]/div[1]/div/div[1]/div/table[1]/tbody/tr/td[2]/div/a,以供之后用。不过要要先进行一个简单的处理,复制来的xpath可能会多带一个tbody标签,把这个删除就,不然会爬取不到数据。然后再这个xpath后加上/text(),表示我想要获取的是里面的文本内容
我们可以先试着爬取第一个标题
from lxml import etree
import requests url = 'https://music.douban.com/top250'
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url , headers = kv).text
s = etree.HTML(r)
title = s.xpath('/html/body/div[3]/div[1]/div/div[1]/div/table[1]/tr/td[2]/div/a/text()')[0]
print(title)
输出结果如下
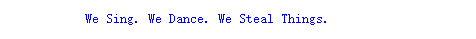
看来是成功的获取到了标题,接下来如法炮制,还有评分和音乐链接,评分没什么好说的,和标题一样的操作就好了,但是音乐链接有点特殊,他是href属性里的数据,其实也难不倒xpath,在这后面加上@href即可,同理,想要别的也可以用@来获取
话不多说直接上代码
from lxml import etree
import requests url = 'https://music.douban.com/top250'
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url , headers = kv).text
s = etree.HTML(r)
title = s.xpath('/html/body/div[3]/div[1]/div/div[1]/div/table[1]/tr/td[2]/div/a/text()')[0]
score = s.xpath('/html/body/div[3]/div[1]/div/div[1]/div/table[1]/tr/td[2]/div/div/span[2]/text()')[0]
music= s.xpath('/html/body/div[3]/div[1]/div/div[1]/div/table[1]/tr/td[2]/div/a/@href')[0]
print(title,score,music)
获取到的效果就是这个样子啦

如果想要获取下一条,那么很简单,去分析下一条的xpath,这里不多赘述,发现是table里的参数发生了变化,那我们就可以改一下xpath,先找到/html/body/div[3]/div[1]/div/div[1]/div/table这一块,然后再这一块里找到后面想要的数据,爬取出来就可以了,直接上代码吧
from lxml import etree
import requests
import json
import re def getUrl():
for i in range(10):
url = 'https://music.douban.com/top250?start={}'.format(i*25) spyder(url) def spyder(url):
#模拟浏览器
kv = {'user-agent':'Mozilla/5.0'}
html = requests.get(url , headers = kv).text
s = etree.HTML(html) trs = s.xpath('/html/body/div[3]/div[1]/div/div[1]/div/table/tr') for tr in trs:
href = tr.xpath('./td[2]/div/a/@href')[0]
title = tr.xpath('./td[2]/div/a/text()')[0].strip()
score = tr.xpath('./td[2]/div/div/span[2]/text()')[0].strip()
numbers = tr.xpath('./td[2]/div/div/span[3]/text()')[0].strip().replace(" ","").replace("\n","")
img = tr.xpath('./td[1]/a/img/@src')[0].strip() items = [href,title,score,numbers,img] with open('temp.txt','a',encoding = 'utf-8') as f:
f.write(json.dumps(items,ensure_ascii=False) + '\n') if '_main_':
getUrl()
这段代码是我看的那篇文章里的,希望诸君能好好消化利用
最新文章
- SQL 邮件配置篇
- UDS(ISO14229-2006) 汉译(No.7 应用层协议)【未完,待续】
- SQL Server如何在变长列上存储索引
- [译]git rebase
- !!!jQuery中事件绑定 推荐使用.delegate()或者live()
- Rootkit Hunter Sourcecode Learning
- VS简介
- 外中断之swi软件中断:
- 将war包布署在本地tomcat上
- [每日一题] OCP1z0-047 :2013-08-02 权限―――分配系统权限
- 前端工程化(三)---Vue的开发模式
- PHP中Smarty引擎的常用语法
- svn"database disk image is malformed"错误解决
- SkyWalking Liunx 环境搭建&NetCore接入
- Nginx 4层反向代理
- F12搜索json内容
- C#------如何深度克隆一个对象
- 【代码审计】iZhanCMS_v2.1 前台GoodsController.php页面存在SQL注入漏洞分析
- solr中facet及facet.pivot理解
- C++基础学习-20120514
热门文章
- L001.PyQt
- TCP 与 UDP 浅谈
- KiKi's K-Number HDU - 2852 树状数组+二分
- The Way to Home CodeForces - 910A
- Firefox下载.net服务器文件时中文乱码
- 启动zabbix-server/agent报错:cannot open "/etc/zabbix/logs/zabbix_server.log": [13] Permission denied
- CPPU OJ | 开发日志
- 数据结构KMP算法中手算next数组
- XJOI CSP-S2 2019开放模拟训练题1 赛后总结
- [shell脚本] mysql服务启动脚本