基于bs4库的HTML标签遍历方法
2024-09-05 18:58:40
基于bs4库的HTML标签遍历方法
import requests
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
HTML基本格式
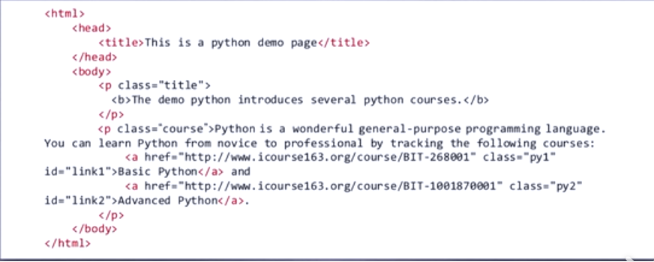
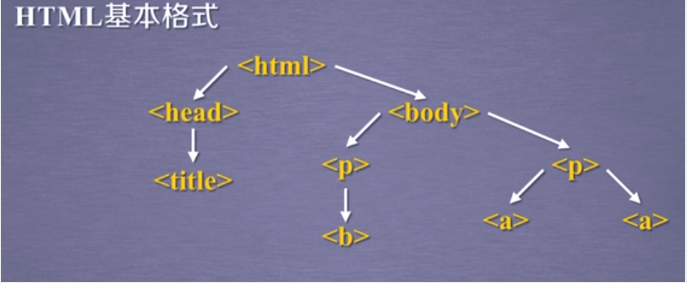
HTML可以看做一棵标签树
遍历方法
!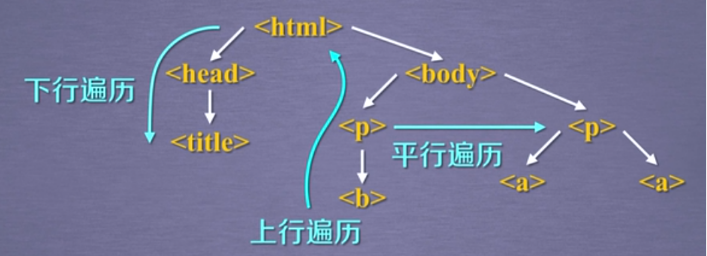
下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 将该标签所有的儿子节点存入列表 |
| .children | 子节点的迭代类型,和contents类似,用于遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有的子孙跌点,用于循环遍历 |
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.contents)# 获取整个标签树的儿子节点
print(soup.body.content)#返回标签树的body标签下的节点
print(soup.head)#返回head标签
print(len(soup.body.content))#输出body标签儿子节点的个数
print(soup.body.content[1])#获取body下第一个子标签
遍历子孙节点
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
for child in soup.body.children:#遍历儿子节点
print(child)
for child in soup.body.descendants:#遍历子孙节点
print(child)
上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点的先辈标签的迭代类型,用于循环遍历先辈节点 |
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.title.parent)
print(soup.title.parent)
print(soup.parent)
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
for parent in soup.a.parents:#遍历先辈的信息
if parent is None:
print(parent)
else:
print(parent.name)
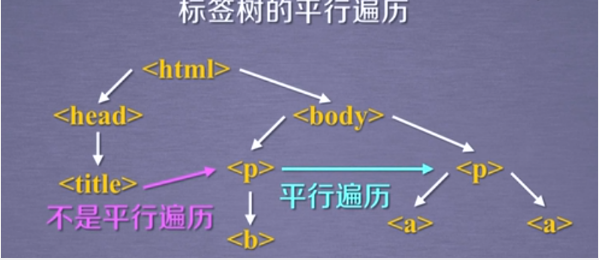
平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回HTML文本顺序的下一个平行标签 |
| .previous_sibling | 返回HTML文本顺序的上一个平行标签 |
| .next_siblings | 迭代类型,返回HTML文本顺序后续所有的平行标签 |
| .pervious_siblings | 迭代类型,返回HTML文本顺序前面所有的平行标签 |
注意
- 标签树的平行遍历是有条件的
- 平行遍历发生在同一个父亲节点的各节点之间
- 标签中的内容也构成了节点
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.a.next_sibling)#a标签的下一个标签
print(soup.a.next_sibling.next_sibling)#a标签的下一个标签的下一个标签
print(soup.a.previous_sibling)#a标签的前一个标签
print(soup.a.previous_sibling.previous_sibling)#a标签的前一个标签的前一个标签
平行遍历
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
for sibling in soup.a.next_siblings:#遍历后续节点
print(sibling)
for sibling in soup.a.previous_sibling:#遍历之前的节点
print(sibling)
有层次感的输出-prettify()
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.prettify())
最新文章
- z-stack组网过程
- Dapper使用方法:dapper-dot-net/Tests/Tests.cs解析(1)方法:TestMultiMapWithConstructor
- mysql数据库管理备份运维常用命令
- jquery keyup 在IOS设备上输入中文时不触发
- 《C++ Primer》之面向对象编程(二)
- 读书笔记 effective c++ Item 49 理解new-handler的行为
- Java集合类库list(1)ArrayList实例
- myeclipse2017下载安装与破解详细教程
- linux开机默认启动命令行模式
- npm -S -D -g i 有什么区别
- csp20151203画图 解题报告和易错地方
- Mysql线程池系列一:什么是线程池和连接池( thread_pool 和 connection_pool)
- Spring MVC定时服务
- Codeforces Beta Round #18 (Div. 2 Only)
- python3.4用循环往mysql5.7中写数据并输出
- OpenCL 三种内存对象的使用
- 设置第三方的SMTP服务
- 「日常训练」Alternative Thinking(Codeforces Round #334 Div.2 C)
- django “如何”系列7:错误汇报
- ASP调用存储过程访问SQL Server