mysql 大数据分页优化
一、mysql大数据量使用limit分页,随着页码的增大,查询效率越低下。
1. 直接用limit start, count分页语句, 也是我程序中用的方法:
select * from product limit start, count
当起始页较小时,查询没有性能问题,我们分别看下从10, 100, 1000, 10000开始分页的执行时间(每页取20条), 如下:
select * from product limit 10, 20 0.016秒
select * from product limit 100, 20 0.016秒
select * from product limit 1000, 20 0.047秒
select * from product limit 10000, 20 0.094秒
我们已经看出随着起始记录的增加,时间也随着增大, 这说明分页语句limit跟起始页码是有很大关系的,那么我们把起始记录改为40w看下(也就是记录的一半左右)
select * from product limit 400000, 20 3.229秒
再看我们取最后一页记录的时间
select * from product limit 866613, 20 37.44秒
难怪搜索引擎抓取我们页面的时候经常会报超时,像这种分页最大的页码页显然这种时
间是无法忍受的。
从中我们也能总结出两件事情:
1)limit语句的查询时间与起始记录的位置成正比
2)mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
2. 对limit分页问题的性能优化方法
利用表的覆盖索引来加速分页查询
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。现在让我们看看利用覆盖索引的查询效果如何:
这次我们之间查询最后一页的数据(利用覆盖索引,只包含id列),如下:
select id from product limit 866613, 20 0.2秒
相对于查询了所有列的37.44秒,提升了大概100多倍的速度
那么如果我们也要查询所有列,有两种方法,
(1)一种是id>=的形式,另一种就是利用join,看下实际情况:
SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
查询时间为0.2秒,简直是一个质的飞跃啊,哈哈
(2)另一种写法
SELECT * FROM product a JOIN (select id from product limit 866613, 20) b ON a.ID = b.id
查询时间也很短,赞!
其实两者用的都是一个原理嘛,所以效果也差不多
二、覆盖索引
1、定义:
(1)如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’。即只需扫描索引而无须回表。
(2)只扫描索引而无需回表的优点:
1)索引条目通常远小于数据行大小,只需要读取索引,则mysql会极大地减少数据访问量。
2)因为索引是按照列值顺序存储的,所以对于IO密集的范围查找会比随机从磁盘读取每一行数据的IO少很多。
3)一些存储引擎如myisam在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用
4)innodb的聚簇索引,覆盖索引对innodb表特别有用。(innodb的二级索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询)
(3)覆盖索引必须要存储索引列的值,而哈希索引、空间索引和全文索引不存储索引列的值,所以mysql只能用B-tree索引做覆盖索引。
当发起一个被索引覆盖的查询(也叫作索引覆盖查询)时,在EXPLAIN的Extra列可以看到“Using index”的信息

2、实验验证
表结构
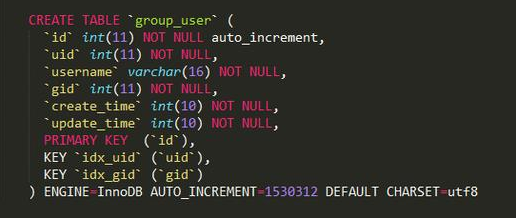
150多万的数据,这么一个简单的语句:

慢查询日志里居然很多用了1秒的,Explain的结果是:

从Explain的结果可以看出,查询已经使用了索引,但为什么还这么慢?
分析:首先,该语句ORDER BY 使用了Using filesort文件排序,查询效率低;其次,查询字段不在索引上,没有使用覆盖索引,需要通过索引回表查询;也有数据分布的原因。
知道了原因,那么问题就好解决了。
解决方案:由于只需查询uid字段,添加一个联合索引便可以避免回表和文件排序,利用覆盖索引提升查询速度,同时利用索引完成排序。

覆盖索引:SQL只需要通过索引就可以返回查询所需要的数据,而不必通过二级索引查到主键之后再去查询数据。
我们再Explain看一次:

Extra信息已经有'Using Index',表示已经使用了覆盖索引。经过索引优化之后,线上的查询基本不超过0.001秒。
部分内容来自于:https://www.cnblogs.com/lpfuture/p/5772055.html
最新文章
- 关于Oracle AUTONOMOUS TRANSACTION(自治事务)的介绍
- Coder-Strike 2014 - Round 1 D. Giving Awards
- eclipse下安装Extjs的插件spket
- cocos2dx-lua class语法糖要注意了
- Java基础知识强化81:Math类random()方法之获取任意范围的随机数案例(面试题)
- ArcEngine颜色可视化
- 【Arduino】8地点LED数码管(3461BS)
- swift2.0 字符串,数组,字典学习代码
- 一天搞定HTML----列表标签03
- (译)Web是如何工作的:给Web开发新手的初级读物
- 单例模式,堆,BST,AVL树,红黑树
- tomcat如何路由映射网址
- Telegraf+InfluxDB+Grafana搭建服务器监控平台
- spring Bean的完整生命周期
- Kong(v1.0.2)认证
- 92. Reverse Linked List II 反转链表 II
- LinuxTimeLine
- (转载)linux 常用命令
- [bug]不包含“AsNoTracking”的定义
- .NetCore使用Swagger进行单版本或多版本控制处理
热门文章
- C# 、Java数组申明、初始化区别
- k8s-dashboard搭建
- mysql jdbcTemplate访问
- create-react-app+react-app-rewired引入antd实践
- ex1.c 补
- 【bzoj2763】[JLOI2011]飞行路线
- linux socket设置阻塞与非阻塞
- 【Leetcode】最大的数
- You have 1 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): shopadmin. Run 'python manage.py migrate' to apply them.
- Elasticsearch Java Rest Client API 整理总结 (一)