Mesa: GeoReplicated, Near RealTime, Scalable Data Warehousing
Mesa的定义并没有反映出他的特点,因为分布式,副本,高可用,他都是依赖google的其他基础设施完成的
他最大的特点是,和传统数仓比,可以做到near real-time的返回聚合的查询结果
算入实时数仓的范围,做到数据一致性,高吞吐的写入,并提供较好的查询性能


所以Mesa的核心是Storage Subsystem如何设计的,
提出一个数仓的经典问题,
提出,dimensional和measure attributes的概念,那么一般dimensional具备hierarchical的特点,比如时间,那么在每个一个layer上都会形成一个物化视图
对于数仓,在dimensional上进行drill-downs和roll-ups,就称为一个最常见的操作
但是对于实时数仓,这就是一个难题,当数据实时写入的时候,如何保证每个物化视图的数据都是同步的,或者可以实时更新

Mesa的Table schema里面除了要定义,传统的key,value的类型,
还需要定义Aggre函数,一定要满足结合律,但是交换律不是强要求
右边的例子中,可以看出,c是b的一个物化视图

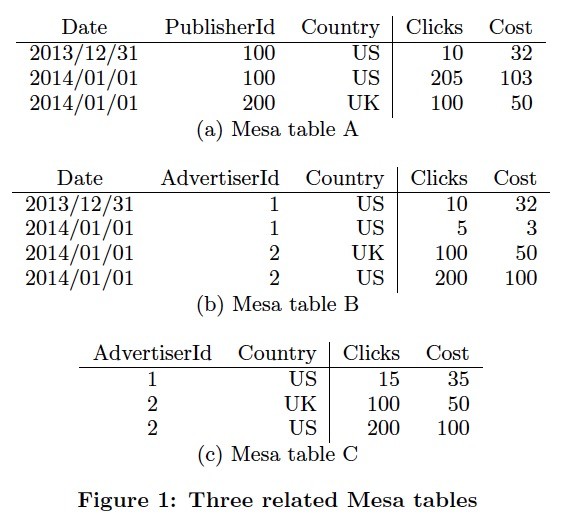
Update和查询
更新关键是要batch,而且这个batch是要上游来保证的,mesa自己也不会cache batch,这个batch通常是分钟级别的,这如果大流量的数据,分钟级别要多大的batch
并且每个batch都会有一个递增version,更新的时候,也是需要根据version来严格按顺序更新,这个来保证atomicity
查询的时候需要带上version number


更新的例子,
更新两个版本,这里没有直接更新c,因为c是b的物化视图,b更新后,Mesa会自动更新c
Mesa论文并没有太多细节讨论,如何高效的更新物化视图,可能他们没有做什么特别的设计,但是如果要所有视图一致,等所有视图更新完,update才返回?
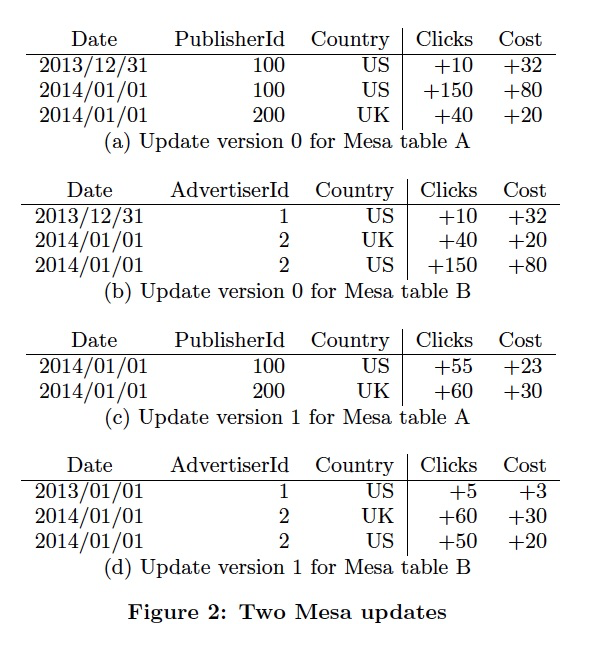
版本数据管理
这里抛出问题,
如果保留所有的原始数据,很expensive
如果要在查询的时候聚合所有的数据,很expensive
但是如果在插入的时候去做预聚合,也很expensive
所以这里的设计其实也很直觉,
写入的时候不能update,只能append,这样才能高吞吐,所以写入只能记录deltas,deltas是batch级别的,至少包含一个version,batch内部预先聚合,这种称为Singletons,如图最右
查询的时候,如果要聚合所有的deltas得到结果,可能不行,所以需要定期把老的delta做compaction,这个叫base compaction
这样查询性能还是不够,那么把新的deltas做小batch的compaction,称为delta compaction,如图,中间,10个version compaction一下
这样查询的时候,可以根据时间或条件,尽量prune deltas,如果老数据,直接读base,新数据,就用cumulatives的结果和部分的Singletons的结果进行聚合





后面论文还讲了一堆的东西,无甚亮点
Mesa核心就是这套版本管理设计,可以参考借鉴
同样的问题,Mesa的数据结构设计的也比较粗糙,Confluo的数据结构设计的更加精妙
最新文章
- vijos P1915 解方程 加强版
- How to: Registry settings for generating Verbose log
- POJ 3384 Feng Shui
- java新特性之可变参数
- bin home
- leetcode[61] Unique Paths
- jquery_api(CSS)
- Python基础(set集合)
- TinyMCE
- 一维信号频谱图仿真——matlab
- Linux 对信号的总结
- 几种 WebP 动态图制作方法
- 使用RegisterNatives注冊原生代码
- 消息中间件及WebSphere MQ入门(转载)
- P3456 [POI2007]GRZ-Ridges and Valleys(bfs)
- 数据序列化导读(1)[JSON]
- python配合Fiddler获取windows app登录时生成cookie实例
- MVVM模式的命令绑定
- Scala之::的研究
- (二分搜索 数论)(求阶乘里零个数对应的阶乘)light oj -- 1138