HashMap之扰动函数和低位掩码
2024-09-02 12:06:19
我们都知道,hashMap在实现的时候,为了寻找在数组上的位置,主要做了两件事
int hash = hash(key);
int i = indexFor(key, table.length);
这个时候得到i才是数组上的位置。
这两个方法详解如下
JDK8对扰动函数的修改,只进行了一次移位(又移16bit),再和key.hashCode()做异或,如图
static final int hash(Object key){
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来访问数组下标。源码中模运算是在这个indexFor( )函数里完成的。
bucketIndex = indexFor(int h, table.length);
其中IndexFor代码
static int indexFor(int h, int length){
return h & (length - 1);
}
indexFor代码,正好解释了为什么HashMap的数组长度要取2的整次幂。因为这样(数组长度-1)正好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。

但这时候问题就来了,这样就算我的散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。更要命的是如果散列本身做得不好,分布上成等差数列的漏洞,恰好使最后几个低位呈现规律性重复,就无比蛋疼。
这时候“扰动函数”的价值就体现出来了,说到这里大家应该猜出来了。看下面这个图,
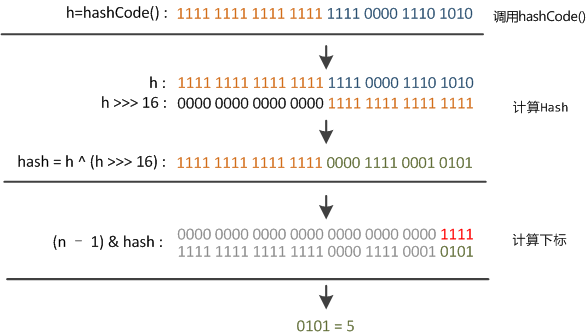
右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。
JDK 7做了4次右移,估计是边际效应的原因,JDK8就只做了一次右移。
另外 JDK8在链表长度超过8的时候,就使用红黑树做存储。这一改变大大优化了很多性能。
最新文章
- 梯度提升树(GBDT)原理小结
- oledbdataadapter 读取excel数据时,有的单元格内容不能读出
- vsftpd基于pam_mysql的虚拟用户机制
- IT行业工作6年回顾
- Web Service 小练习
- clipToBounds
- nodejs cmd
- Tomcat启动报错:严重: StandardServer.await: create[8005] java.net.BindException: Cannot assign requested address
- Javascript之登陆验证
- python指定pypi的源地址 镜像地址
- 上Https 和 http 差分
- js 数字递增特效 仿支付宝我的财富 HTML5
- SSL证书:Web加密使互联网更安全
- 如何在eclipse中添加ADT
- PLC不能初始化问题
- SQL Server的JOIN是支持使用小括号修改执行顺序的
- 12、Grafan 4.3升级到Grafana 5.0
- 学习笔记第六课 VB程序
- spring mvc 跨域问题。。。解决
- 【*】深入理解redis主从复制原理