Google BERT摘要
1.BERT模型
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
1.1 模型结构
由于模型的构成元素Transformer已经解析过,就不多说了,BERT模型的结构如下图最左:
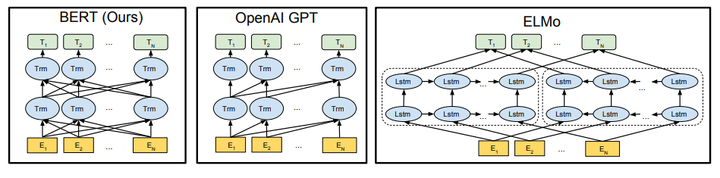
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接;就像单向rnn和双向rnn的区别,直觉上来讲效果会好一些。
对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMo是分别以 和
作为目标函数,独立训练处两个representation然后拼接,而BERT则是以
作为目标函数训练LM。
1.2 Embedding
这里的Embedding由三种Embedding求和而成:
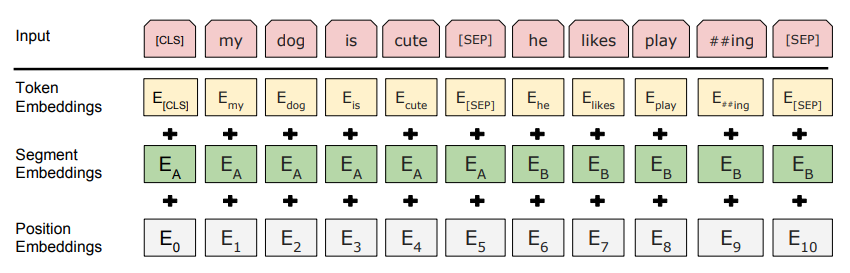
其中:
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
总结:
1. BERT的特征提取,是在捕捉词的(前后)位置关系。bidirectional决定了能获得前后的关系,position embedding决定了能学到更长的顺序关系。
2.训练,分为pre-train和fine-tune。pre-train中用到了MLM, Masked LM.
3. trick: MLM. 在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token。
4. 缺点: (1)[MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现
(2)每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
https://zhuanlan.zhihu.com/p/46652512
https://arxiv.org/pdf/1810.04805.pdf
最新文章
- linux 下安装web开发环境
- 全新 Mac 安装指南(编程篇)(环境变量、Shell 终端、SSH 远程连接)
- 烂泥:openvpn配置文件详解
- [转]Mac下配置基于SecurID的Cisco IPSec VPN全攻略(有图)
- FineUI小技巧(5)向子窗口传值,向父窗口传值
- .NET委托和事件
- PHP面向对象实例(图形计算器)
- Mac下搭建php开发环境【转】
- C#微信json结构接收参数 转载
- hadoop单节点windows 7 环境搭建
- TC358746AXBG/748XBG 桥接器说明
- android开发中的5种存储数据方式
- 嵌入式ntp服务器的移植
- C#中几种数据库的大数据批量插入
- HDU-1275-两车追及或相遇问题(数学题目)
- 通讯录--(iOS9独有的方法)
- CCF系列之字符串匹配(201409-3)
- [HNOI2003]激光炸弹
- FatMouse' Trade -HZNU寒假集训
- Luogu P3157 [CQOI2011]动态逆序对
热门文章
- Java16周作业
- idea 将java导出为可执行jar及导入jar依赖
- 搭建java环境时,DOS输入java有反应,javac没反应的解决办法。
- 解读Es6之 promise
- [RN] React Native 删除第三方开源组件依赖包 后 还要做的 (以 删除 react-native-video为例)
- AtCoder Regular Contest 069 F Flags 二分,2-sat,线段树优化建图
- 洛谷 P1991 无线通讯网 题解
- [golang][gui]Hands On GUI Application Development in Go【在Go中动手进行GUI应用程序开发】读书笔记03-拒交“智商税”,解密“GUI”运行之道
- HDU 6212 Zuma
- [技术博客] rails控制台调试路由