Java IO流(二)
字节缓冲流
能够高速读写的缓冲流,能够转换编码的转换流,能够持久化存储对象的序列化流等等,这些功能强大的流,都是在基本的流对象基础之上创建而来的,就像穿上铠甲的武士一样,相当于是对基本流对象的一种增强。
概述
缓冲流,也叫高效流,是对4个基本的 FileXxx流的增强,所以也是4个流,按照数据类型分类:
- 字节缓冲流:
BufferedInputStream,BufferedOutputStream - 字符缓冲流:
BufferedReader,BufferedWriter - 缓冲流的基本原理:是在创建流对象时,会创建一个内置大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。

BufferedOutputStream类
- java.io.BufferedOutputStream extends OutputStream
- BufferedOutputStream:字节缓冲输入流。
继承父类的共性成员方法
- public void close():关闭此输出流并释放与此流相联的任何系统资源。
- public void flush():刷新此输出流并强制任何缓冲的输出字节被写出。
- public void write(byte[] b):将b.length字节从指定的字节数组写入此输出流。
- public void write(byte[] b, int off, int len):从指定的字节数组写入 len字节,从偏移量 off开始输出至此输出流。
- public abstract void write(int b):将指定的字节输出流。
构造方法
- BufferedOutputStream(OutputStream out) :创建一个新的缓冲输出流,以将数据写入指定的底层输出流。
- BufferedOutputStream(OutputStream out, int size) :创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流。
- 参数:
- OutputStream out:字节输出流。我们可以传递FileOutputStream对象,缓冲流会给FileOutputStream增加一个缓冲区,提高FileOutputStream的写入效率。
- int size:指定缓冲流内部缓冲区数组的大小,不指定默认。
使用步骤(重点):
- 创建FileOutputStream对象,构造方法中绑定要输出数据的目的地。
- 创建BufferedOutputStream对象,构造方法中传递FileOutputStream对象,提高FileOutputStrem的写入效率。
- 使用BufferedOutputStream对象中的方法 writer,把数据写入到内部缓冲区中。
- 使用BufferedOutputStream对象中的方法 flush,把内部缓冲区中的数据,刷新到文件中。
- 释放资源(会先调用 flush方法,刷新数据,第4步可以省略)。
- 示例
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo01BufferedOutputStream {
public static void main(String[] args) throws IOException {
// 1. 创建FileOutputStream对象,构造方法中传递要输出数据的目的地
FileOutputStream fos = new FileOutputStream("itcast-code\\a.txt");
// 2. 创建BufferedOutputStream对象,构造方法中传递FileOutputStream对象,提高写入的效率
BufferedOutputStream bos = new BufferedOutputStream(fos);
// 3. 调用BufferedOutputStream对象的方法,write写入数据
bos.write("我把数据写入到内部缓冲区中".getBytes());
// 4. 调用flush方法,刷新缓冲区
bos.flush();
// 5. 释放资源
bos.close();
}
}
BufferedInputStream类
- java.io.BufferedInputStream extends InputStream
- BufferedInputStream:字节缓冲输入流。
继承自父类的方法:
- abstract int read():从输入流中读取数据的下一个字节。
- int read(byte[] b):从输入流中读取一定数量的字节,并将其存储到缓冲区数组 b 中。
- void close():关闭此输入流并释放与该流关联的所有系统资源。
构造方法
- BufferedInputStream(InputStream in) :创建一个 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。
- BufferedInputStream(InputStream in, int size) :创建具有指定缓冲区大小的 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。
- 参数:
- InputStream in:字节输入流。我们可以传递FileInputStream对象,缓冲流会给FileInputStream增加一个缓冲区,提高FileInputStream的读取效率。
- int size:指定缓冲流内部缓冲区数组的大小,不指定默认。
使用步骤(重点):
- 创建FileInputStream对象,构造方法中绑定要读取的数据源.。
- 创建BufferedInputStream对象,构造方法中传递FileInputStream对象,提高FileInputStrem的读取效率。
- 使用BufferedInputStream对象中的方法 read,读取文件。
- 释放资源(会先调用 flush方法,刷新数据)。
- 示例
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
public class Demo02BufferedInputStream {
public static void main(String[] args) throws IOException {
// 1. 创建FileInputStream对象,构造方法中绑定读取的数据源
FileInputStream fis = new FileInputStream("itcast-code\\a.txt");
// 2. 创建BufferedInputStream对象,构造方法中传递FileInputStream对象
BufferedInputStream bis = new BufferedInputStream(fis);
// 3. 调用BufferedInputStream中的方法,read,读取文件
// 一次读取一个字节的方式
/*
int len = 0; // 记录每次读取字节的有效个数
while ((len = bis.read()) != -1) {
System.out.println((char)len);
}
*/
// 一次读取多个字节的方式
int len = 0; // 记录每次读取字节的有效个数
// 用来缓冲读取的字节
byte[] bytes = new byte[1024];
// 读取到文件末尾时,返回-1
while ((len = bis.read(bytes)) != -1) {
System.out.println(new String(bytes, 0, len));
}
}
}
文件复制练习(增强版 使用缓冲流)
import java.io.*;
/*
使用缓冲流完成
文件复制练习:一读一写
明确:
数据源:
数据的目的地:
文件复制的步骤:
1. 创建字节缓冲输入流对象,构造方法中传递字节输入流对象。
2. 创建字节缓冲输出流对象,构造方法中传递字节输出流对像.
3. 使用字节缓冲输入流中的方法,read,读取文件。
4. 使用字节缓冲输出流中的方法 writer,把读取到的数据写入到内部缓冲区中。
5. 释放资源(会先把缓冲区中的数据,刷新到文件中)
*/
public class Demo03CopuFIle {
public static void main(String[] args) throws IOException {
// 记录开始时间
long start = System.currentTimeMillis();
// 1. 创建字节缓冲输入流对象
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("C:\\Users\\Pictures\\Saved Pictures\\3.jpeg"));
// 2. 创建字节缓冲输出流对象
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("D:\\3.jpeg"));
// 3. 调用 read方法,读取文件
// 一次读取一个字节的方式
/*int len = 0;
while ((len = bis.read()) != -1) {
// 调用 write方法,写入数据
bos.write(len);
}*/
// 使用字节数组缓冲一次读取到的多个字节
byte[] bytes = new byte[1024];
int len = 0;
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0, len);
}
// 5. 释放资源
bos.close();
bis.close();
// 结束时间
long end = System.currentTimeMillis();
System.out.println("文件复制耗费:" + (end - start) + "毫秒");
}
}
字符缓冲流
- java.io.BufferedWriter extends Writer
- BufferedWriter:字符缓冲输出流。
BufferedWriter类
继承自父类的共性方法
- void writer(int c):写入单个字符。
- void writer(char[ ] cbuf):写入字符数组。
- abstract void writer(char[ ] cbuf, int off, int len):写入字符数组的一部分,off:数组的开始索引,len:写的字符个数。
- void writer(String str):写入字符串。
- void writer(String str, int off, int len):写入字符串的一部分,off:字符串的开始索引,len:写入字符的个数。
- void flush():刷新该流的缓冲区。
- void close():关闭此流,但要先刷新它。
构造方法
- BufferedWriter(Writer out) :创建一个使用默认大小输出缓冲区的缓冲字符输出流。
- BufferedWriter(Writer out, int sz) :创建一个使用给定大小输出缓冲区的新缓冲字符输出流。
- 参数:
- Writer out:字符输出流。我们可以传递 FileWriter对象,缓冲流会给 FileWriter增加一个缓冲区,提高 FileWriter的写入效率。
- int sz:指定缓冲区的大小,不写默认大小。
特有的成员方法
- void newLine() :写入一个行分隔符。 会根据不同的操作系统,获取不同的行分隔符。
- 换行:换行符号
- Windows:\r\n
- Linux:/n
- mac:/r
使用步骤:
- 创建字符缓冲输出流对象,构造方法中传递字符输出流。
- 调用字符缓冲输出流对象中的方法 writer,把数据写入到内存缓冲区中。
- 调用字符缓冲输出流对象中的方法 flush,把内存缓冲区中的数据,刷新到文件中。
- 释放资源。
- 示例:
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class Demo04BufferedWriter {
public static void main(String[] args) {
try (// 1. 创建字符缓冲输出流对象,构造方法中绑定字符输出流对象
BufferedWriter bw = new BufferedWriter(new FileWriter("itcast-code\\b.txt"));) {
for (int i = 0; i < 10; i++) {
// 2. 调用字符缓冲输出流对象中的方法,writer,把数据写入到内存缓冲区中
bw.write("我爱学习java,耶耶耶!");
// 使用特有的方法,newLine(),换行
bw.newLine();
}
// 3. 调用字符缓冲输出流对象中的方法,flush,把内存缓冲区中的数据,刷新到文件中
bw.flush();
} catch (IOException e) {
System.out.println(e);
}
// 4. 释放资源
// bw.close();
}
}
BufferedReader类
- java.io.BufferedReader extends Reader
- BufferedReader:字符缓冲输入流
继承自父类的共性方法
- int read():读取单个字符并返回。
- int read(char[ ] cbuf):一次读取多个字符,将字符读入数组。
- void close():关闭该流并释放与之关联的所有资源。
构造方法
- BufferedReader(Reader in) :创建一个使用默认大小输入缓冲区的缓冲字符输入流。
- BufferedReader(Reader in, int sz) :创建一个使用指定大小输入缓冲区的缓冲字符输入流。
- 参数:
- Reader in:字符输入流。我们可以传递 FileReader,缓冲流会给 FileReader增加一个缓冲区,提高 FileReader的读取效率。
- int sz:指定缓冲区的大小,不写默认大小。
特有的成员方法
- String readLine() :读取一个文本行。读取一行数据。
- 通过下列字符之一即可认为某行已终止:换行 ('\n')、回车 ('\r') 或回车后直接跟着换行 ( \r\n )。
- 返回值:
- 包含该行内容的字符串,不包含任何行终止符,如果已到达流末尾,则返回 null。
使用步骤:
- 创建字符缓冲输入流对象,构造方法中传递字符输入流对象。
- 使用字符输入流对象中的方法,read / readLine,读取文本。
- 释放资源。
- 示例:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class Demo05BufferedReader {
public static void main(String[] args) throws IOException {
// 1. 创建字符缓冲输入流对象,构造方法中绑定字符输入流对象
BufferedReader br = new BufferedReader(new FileReader("itcast-code\\b.txt"));
/*
在不知道文本中有多少行时,使用while循环
while的结束条件,读取到 null时结束
*/
// 2. 使用字符缓冲输入流对象中的方法,read / readLine,读取文本
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
// 3. 释放资源
br.close();
}
}
练习:文本排序
import java.io.*;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
/*
练习:
对文本的内容进行排序
按照(1,2,3,4...)顺序排序
分析:
1. 创建一个HashMap集合对象
key:存储每行的文本序号(1,2,3...)
value:存储每行的文本
2. 创建字符缓冲输入流对象,构造方法中绑定字符输入流对象
3. 创建字符缓冲输入流对象,构造方法中绑定字符输出流对象
4. 调用字符缓冲输入流中的方法,readLine,逐行读取文本
5. 对读取到的文本进行切割,获取行中的序号和文本内容
6. 把切割好的序号和文本内容存储到HashMap集合中(key是有序的,会自动排序1,2,3..)
7. 遍历HashMap集合,获取每一个键值对
8. 把每一个键值对,拼接成一个文本行
9. 把拼接好的文本行,使用字符缓冲输入流的方法write,写入文件中
10. 释放资源
*/
public class Demo06Test {
public static void main(String[] args) throws IOException {
// 1. 创建HashMap集合,key:序号,value:文本内容
HashMap<String, String> map = new HashMap<>();
// 2. 创建字符缓冲输入流对象
BufferedReader br = new BufferedReader(new FileReader("itcast-code\\in.txt"));
// 3. 创建字符缓冲输入流对象
BufferedWriter bw = new BufferedWriter(new FileWriter("itcast-code\\out.txt"));
// 4. 使用字符缓冲输入流中的方法,readLine方法,读取文本内容
String line;
while ((line = br.readLine()) != null) {
// 5. 对读取到的字符串进行切割,key:序号,value:文本内容
String[] arr = line.split("\\.");
// 6. 把切割好的字符串放入到HashMap集合中
map.put(arr[0], arr[1]);
}
// 7. 遍历HashMap集合,获取键值对
Set<Map.Entry<String, String>> entrySet = map.entrySet();
// 遍历Set集合的迭代器
Iterator<Map.Entry<String, String>> it = entrySet.iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
String key = entry.getKey();
String value = entry.getValue();
// 8. 对键值对进行拼接
line = key + "." + value;
// 9. 使用字符缓冲输出流对象,输出到文件中
bw.write(line);
// 换行
bw.newLine();
}
// 10. 释放资源
bw.close();
br.close();
}
}
转换流
字符编码和字符集
字符编码
- 编码:字符(能看懂的)--> 字节(看不懂的)。
- 解码:字节(看不懂的)--> 字符(能看懂的)。
- 字符编码(Character Encoding):就是一套自然语言的字符与二进制数之间的对应规则。
- 编码表:生活中的文字和计算机中二进制的对应规则。
字符集
- 字符集(CharSet):也叫编码表,是一个系统支持的所有字符的集合,包括各国家的文字、标点符号、图形符号、数字等。
- ASCII字符集:
- 基本的ASCII字符集,使用7位(bits)表示一个字符,共128个字符。ASCII的扩展字符集使用8位(bits)表示一个字符,共256个字符,方便支持欧洲常用字符。
- ISO-8859-1字符集:
- 使用单字节编码,兼容ASCII编码。
- GBxxx字符集:
- GB就是国标的意思,是为了显示中文而设计的一套字符集。
- GB2312:简体中文码表。
- GBK:最常用的中文码表,用2个字节表示一个中文。
- GB18030:最新的中文码表,采用多字节编码,每个字可以由1、2、4个字节组成。
- Unicode字符集
- 万国码
- 它最多使用4个字节的数字表达字符。有三种编码方案:UTF-8、UTF-16、UTF-32。最为常用的是UTF-8。
- UTF-8编码:
- 128个US-ASCII字符,只需一个字节编码。
- 拉丁文等字符,需要2个字节编码。
- 大部分常用字(含中文),使用3个字节编码。
- 其他极少使用的Unicode辅助字符,使用4个字节编码。
编码引出的问题
在IDEA中,使用FileReader读取项目中的文本文件。由于IDEA的设置,都是默认的UTF-8编码,所以没有任何问题。但是当读取Windows系统中创建的文本文件时,由于Windows系统的默认是GBK,就会出现乱码。
- 示例:
// 乱码问题
import java.io.FileReader;
import java.io.IOException;
public class Test {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("D:\\ideaproject\\itcast-code\\a.txt");
int len = 0;
while ((len = fr.read()) != -1) {
System.out.print((char)len);
}
fr.close();
}
}
/*
输出结果:
��ã����磡
*/
转换流的原理
FileReader类:
- 用来读取字符文件的便捷类。
- 此类的构造方法假定默认字符编码和默认字节缓冲区大小都是适当的。
- 要自己指定这些值,可以先在 FileInputStream 上构造一个 InputStreamReader。
FileWriter类:
- 来写入字符文件的便捷类。
- 此类的构造方法假定默认字符编码和默认字节缓冲区大小都是可接受的。
- 要自己指定这些值,可以先在 FileOutputStream 上构造一个 OutputStreamWriter。
OutputStreamWriter类
- java.io.OutputStreamWriter extends Writer
- OutputStreamWriter:是字符流通向字节流的桥梁;可使用指定的
charset将要写入流中的字符编码成字节。(编码:把能看懂的 --> 看不懂的)
继承父类的共性成员方法
- void writer(int c):写入单个字符。
- void writer(char[ ] cbuf):写入字符数组。
- abstract void writer(char[ ] cbuf, int off, int len):写入字符数组的一部分,off:数组的开始索引,len:写的字符个数。
- void writer(String str):写入字符串。
- void writer(String str, int off, int len):写入字符串的一部分,off:字符串的开始索引,len:写入字符的个数。
- void flush():刷新该流的缓冲区。
- void close():关闭此流,但要先刷新它。
构造方法
- OutputStreamWriter(OutputStream out) :创建使用默认字符编码的 OutputStreamWriter。
- OutputStreamWriter(OutputStream out, String charsetName) :创建使用指定字符集的 OutputStreamWriter。
- 参数:
- OutputStream out:字节输出流,可以用来写转换之后的字节到文件中。
- String charsetName:指定编码表的名称,不区分大小写,可以是:utf-8 / UTF-8,gbk / GBK,...。不指定,默认使用 utf-8。
使用步骤:
- 创建OutputStreamWriter对象,构造方法中传递字节输出流对象和指定编码表名称。
- 使用OutputStreamWriter对象中的方法 writer,把字符转换为字节,存储在缓冲区中(编码)。
- 使用OutputStreamWriter对象中的方法 flush,把内存缓冲区中的字节刷新到文件中(使用字节流写的过程)。
- 释放资源。
- 示例:
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
public class Demo01OutputStreamWriter {
public static void main(String[] args) throws IOException {
// write_utf_8();
write_gbk();
}
private static void write_gbk() throws IOException {
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("itcast-code\\gbk.txt"), "gbk");
osw.write("你好"); // 3个字节
osw.flush();
osw.close();
}
private static void write_utf_8() throws IOException {
// 1. 创建OutputStreamWriter对象,构造方法中传递字节输出流对象和指定编码表名称
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("itcast-code\\utf_8.txt"), "utf-8");
// 2. 使用OutputStreamWriter对象中的方法,writer,把字符转换成字节,存储在缓冲区中。(编码)
osw.write("你好"); // 2个字节
// 3. 调用 flush方法,刷新数据到文件中、
osw.flush();
// 4. 释放资源
osw.close();
}
}
InputStreamReader类
- java.InputStreamReader extends Reader
- InputStreamReader:是字节流通向字符流的桥梁;它使用指定的 charset 读取字节并将其解码为字符(解码:把看不懂的 --> 能看懂的)。
继承自父类的共性方法
- int read():读取单个字符并返回。
- int read(char[ ] cbuf):一次读取多个字符,将字符读入数组。
- void close():关闭该流并释放与之关联的所有资源。
构造方法
- InputStreamReader(InputStream in) :创建一个使用默认字符集的 InputStreamReader。
- InputStreamReader(InputStream in, String charsetName) :创建使用指定字符集的 InputStreamReader
- 参数:
- InputStream in:字节输入流,用来读取文件中保存的字节。
- String charsetName:指定的编码表名称,不区分大小写,可以是:utf-8 / UTF-8,gbk / GBK,...。不指定,默认使用 utf-8。
使用步骤:
- 创建InputStreamReader对象,构造方法中传递字节输入流对象和指定编码表名称。
- 使用InputStreamReader对象中的方法,read,读取文件。
- 释放资源。
注意事项:
构造方法中传递的编码表名称要和文件的编码表相同,否则会产生乱码。
- 示例
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
public class Demo03InputStreamReader {
public static void main(String[] args) throws IOException {
// read_utf_8();
read_gbk();
}
private static void read_gbk() throws IOException{
// 1.创建InputStreamReader对象,构造方法中传递字节输入流对象和指定的编码表名称
InputStreamReader isr = new InputStreamReader(new FileInputStream("itcast-code\\utf_8.txt"), "gbk");
// 2.使用InputStreamReadr中的方法,read,读取文件。
int len = 0; // 记录读取到字符的有效个数
// 使用字符数组缓冲读取到的多个字符
char[] cs = new char[1024];
while ((len = isr.read(cs)) != -1) {
System.out.println(new String(cs, 0, len));
}
// 3.释放资源
isr.close();
}
private static void read_utf_8() throws IOException {
// 1.创建InputStreamReader对象,构造方法中传递字节输入流对象和指定的编码表名称
InputStreamReader isr = new InputStreamReader(new FileInputStream("itcast-code\\utf_8.txt"));
// 2.使用InputStreamReadr中的方法,read,读取文件。
int len = 0; // 记录读取到字符的有效个数
// 使用字符数组缓冲读取到的多个字符
char[] cs = new char[1024];
while ((len = isr.read(cs)) != -1) {
System.out.println(new String(cs, 0, len));
}
// 3.释放资源
isr.close();
}
}
练习:转换文件编码
import java.io.*;
/*
练习:转换文件编码
将gbk编码的文件,转换为utf-8编码的文件。
分析:
1.创建InputStreamReader对象,构造方法中传递字节输入流对象和指定gbk编码
2.创建OutputStreamWriter对象,构造方法中传递字节输出流对象和指定utf-8编码
3.使用InputStreamReader对象的方法 read,读取数据到缓冲区中
4.使用OutputStreamWriter对象的方法 writer,将数据写入到文件中
5.释放资源
*/
public class Demo02Test {
public static void main(String[] args) throws IOException {
InputStreamReader isr = new InputStreamReader(new FileInputStream("itcast-code\\gbk.txt"),"gbk");
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("itcast-code\\utf_8.txt"), "utf-8");
int len = 0;
while ((len = isr.read()) != -1) {
osw.write(len);
}
osw.close();
isr.close();
}
}
序列化&反序列化
序列化&反序列化概述
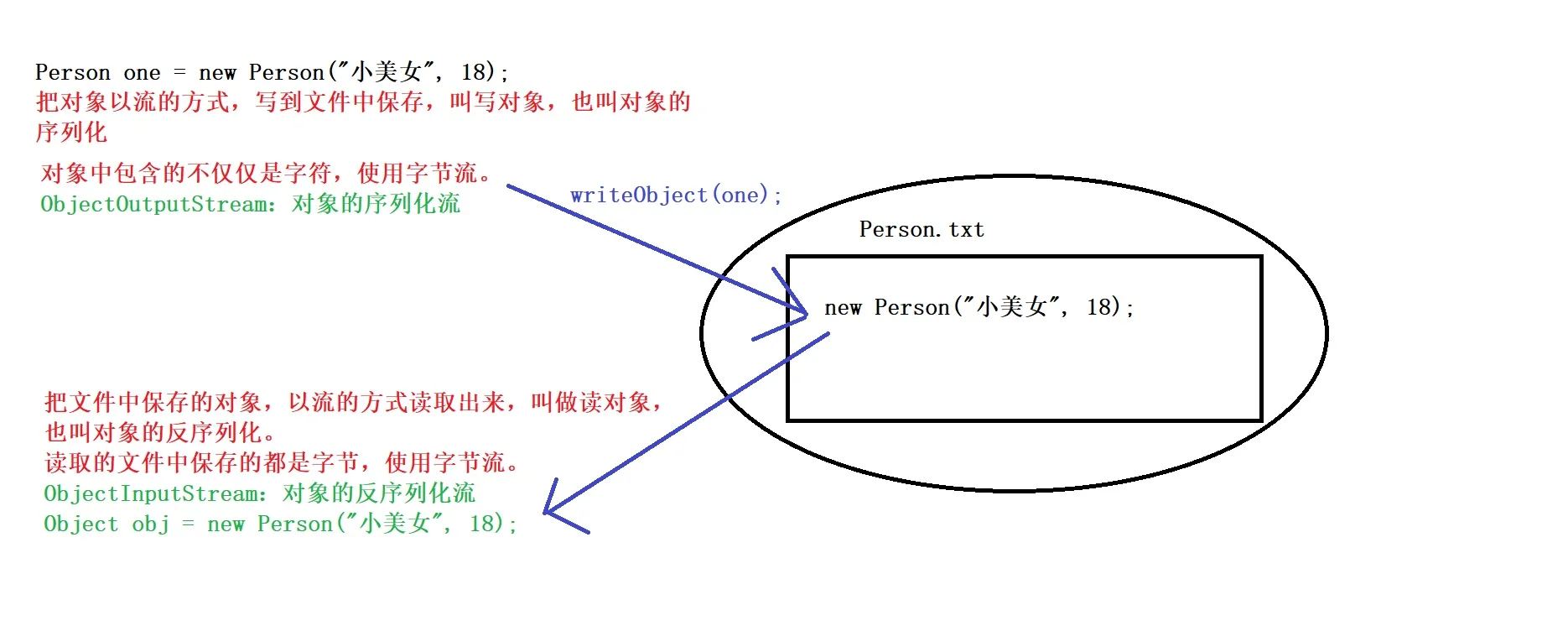
ObjectOutputStream类
- java.io.ObjectOutputStream extends OutputStream
- ObjectOutputStream:对象的序列化流
- 作用:把对象以流的方式写入到文件中保存。
构造方法
- ObjectOutputStream(OutputStream out):创建写入指定 OutputStream 的 ObjectOutputStream。
- 参数:
- OutputStream out:字节输出流。
特有的成员方法
- void writeObject(Object obj) :将指定的对象写入 ObjectOutputStream。
使用步骤:
- 创建 ObjectOutputStream对象,构造方法中传递字节输出流。
- 使用 ObjectOutputStream对象中的方法,writeObject,把对象写入到文件中。
- 释放资源。
示例
- Person.java
import java.io.Serializable;
/*
序列化和反序列化的时候,会抛出 NotSerializableException没有序列化异常
类通过实现 java.io.Serializable 接口以启用其序列化功能。
未实现此接口的类将无法使其任何状态序列化或反序列化。
Serializable接口也叫标记型接口
要进行序列化和反序列化的类,必须实现 Serializable接口,就会给类添加一个标记
当我们进行序列化和反序列化的时候,就会检测类上是否有这个标记
有:可以序列化和反序列化
没有:就会抛出 NotSerializableException异常
*/
public class Person implements Serializable {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
- Demo01ObjectOutputStream.java
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class Demo01ObjectOutputStream {
public static void main(String[] args) throws IOException {
Person one = new Person("小美女", 18);
// 1.创建ObjectOutputSream对象,构造方法中传递字节输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("itcast-code\\person.txt"));
// 2.使用ObjectOutputstream中的方法,writerObject,将对象写入到文件中
oos.writeObject(one);
// 3.释放资源
oos.close();
}
}
ObjectInputStream类
- java.io.ObjectInputStream extends InputStream
- ObjectInputStream:对象的反序列化流。
- 作用:把文件中保存的对象,以流的方式读取出来使用。
构造方法
- ObjectInputStream(InputStream in) :创建从指定 InputStream 读取的 ObjectInputStream。
- 参数:
- InputStream in:字节输入流
特有的成员方法
- Object readObject() :从 ObjectInputStream 读取对象。
使用步骤:
- 创建ObjectInputStream对象,构造方法中传递字节输入流。
- 使用ObjectInputStream对象中的方法 readObject读取保存对象的文件。
- 释放资源。
注意事项:
readObject方法声明抛出了 ClassNotFoundException(class文件找不到异常)
当不存在对象的 class文件时抛出此异常。
反序列化的前提:
- 类必须实现 Serializable接口
- 必须存在类对应的 class文件
- 示例
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class Demo03ObjectInputStream {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 1.创建ObjectInputStream对象,构造方法中传递字节输入流
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("itcast-code\\person.txt"));
// 2.使用ObjectInputStream中的方法,readObject,读取文件中保存的对象
Object o = ois.readObject();
System.out.println(o);
Person one = (Person)o;
System.out.println(one.getName()+one.getAge());
// 3.释放资源
ois.close();
}
}
transient关键字
- static关键字:静态关键字
- 静态优于非静态加载到内存中(静态优先于对象进入到内存中)。
- 被 static修饰的成员变量不能被序列化,序列化的都是对象。
private static int age;
oos.writeObject(new Person("小美女", 18));
Object o = ois.readObject();
Person{name='小美女', age=0}
- transient关键字:瞬态关键字
- 被 transien修饰的成员变量,不能被序列化。
private transient int age;
oos.writeObject(new Person("小美女", 18));
Object o = ois.readObject();
Person{name='小美女', age=0}
InvalidClassException异常
编译器(javac.exe)会把 Person.java文件编译成生成 Person.class 文件,Person类实现了 Serializable接口,就会根据类的定义,给 Person.class文件添加一个序列号(serialVersionUID)。
反序列化的时候,会使用Person.class文件中的序列号和Person.txt文件中的序列号进行比较,如果是一样的,则反序列化成功;如果不一样,则抛出序列化冲突异常:InvalidClassException。
修改了类的定义,那么就会给 Person.class 文件重新编译生成一个新的序列号(serialVersionUID)。
问题:
- 每次修改了类的定义,都会给class文件重新生成一个新的序列号。
解决方案:
- 无论是否对类的定义进行修改,都不重新生成新的序列号。
- 可以手动给类添加一个序列号。
格式在 Serializable接口内有规定:
- 可序列化类可以通过声明名为 "serialVersionUID" 的字段(该字段必须是静态 (static)、最终 (final) 的 long 型字段)显式声明其自己的 serialVersionUID:
static final long serialVersionUID = 42L;
练习:序列化集合
import java.io.*;
import java.util.ArrayList;
/*
练习:序列化集合
当我们想在文件中保存多个对象的时候,可以把多个对象存储到一个集合中
对集合进行序列化和反序列化
分析:
1.定义一个存储Person对象的ArrayList集合
2.往ArrayList集合中添加多个对象
3.创建一个序列化ObjectOutputStream对象
4.使用ObjectOutputStream对象中的 writeObject方法,对集合进行序列化
5.创建一个反序列化ObjectInputStream对象
6.使用ObjectInputStream对象中的方法 readObject方法,读取文件中保存的集合
7.把 Object类型的集合强转为 ArrayList类型
8.遍历ArrayList集合
9.释放资源
*/
public class Demo02Pracitse {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 创建集合
ArrayList<Person> list = new ArrayList<>();
// 添加元素
list.add(new Person("周元", 20));
list.add(new Person("夭夭", 21));
list.add(new Person("苏幼薇", 19));
// 创建序列化流对象
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("itcast-code\\list.txt"));
// 调用 writeObject方法,将集合写入
oos.writeObject(list);
// 创建反序列化流对象
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("itcast-code\\list.txt"));
// 调用 readObject方法,读取集合
Object o = ois.readObject();
// 将 Object类型强转为 Arraylist类型
ArrayList<Person> personArrayList = (ArrayList<Person>)o;
// 遍历集合
for (Person p : personArrayList) {
System.out.println(p);
}
// 释放资源
oos.close();
ois.close();
}
}
打印流
概述
- java.io.PrintStream extends FilterOutputStream extends OutputStream
- java.io.PrintStream:打印流
- PrintStream:为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
- PrintStream特点:
- 只负责数据的输出,不负责数据的读取。
- 与其他输出流不同,PrintStream 永远不会抛出 IOException,但会抛出 FileNotFoundException。
- 有特有的方法:print,println
- void print(任意类型的值)
- void println(任意类型的值并换行)
构造方法
- PrintStream(File file) :创建具有指定文件且不带自动行刷新的新打印流。
- PrintStream(OutputStream out) :创建新的打印流。
- PrintStream(String fileName) :创建具有指定文件名称且不带自动行刷新的新打印流。
继承自父类的共性方法
- public void close():关闭此输出流并释放与此流相联的任何系统资源。
- public void flush():刷新此输出流并强制任何缓冲的输出字节被写出。
- public void write(byte[] b):将b.length字节从指定的字节数组写入此输出流。
- public void write(byte[] b, int off, int len):从指定的字节数组写入 len字节,从偏移量 off开始输出至此输出流。
- public abstract void write(int b):将指定的字节输出流。
注意事项:
- 如果使用继承自父类的 write方法写数据,那么查看数据的时候,会查询编码表:97 --> a。
- 如果使用自己特有的方法 print / println方法写数据,那么写的数据会原样输出:97 --> 97。
import java.io.FileNotFoundException;
import java.io.PrintStream;
public class Demo01PrintStream {
public static void main(String[] args) throws FileNotFoundException {
// 1.创建PrintStream对象,构造方法中绑定输出的目的地
PrintStream ps = new PrintStream("itcast-code\\print.txt");
// 2.调用父类的 write方法
ps.write(48); // 0
// 2.调用自己的 print / println 方法
ps.println();
ps.println(97); // 97
// 3.释放资源
ps.close();
}
}
改变输出流的流向
- 可以改变输出语句的目的地(打印流的流向)。
- 输出语句,默认在控制台输出。
- 使用 System.setOut 方法该变输出语句的目的地,目的地修改为PrintStream构造方法中传递的目的地。
- static void setOut(PrintStream out) :重新分配“标准”输出流。
import java.io.FileNotFoundException;
import java.io.PrintStream;
public class Demo02PrintStream {
public static void main(String[] args) throws FileNotFoundException {
PrintStream ps = new PrintStream("itcast-code\\print.txt");
// 在控制台输出
System.out.println("我在控制台输出,哈哈哈");
// 改变输出流的流向
System.setOut(ps);
// 这条语句在文件中原样输出
System.out.println("我在print.txt中输出,呵呵呵");
ps.close();
}
}
最新文章
- [解决方案]CREATE DATABASE statement not allowed within multi-statement transaction.
- sql server 数据库 日期格式转换
- 小波变换C++实现(一)----单层小波变换
- Dos del参数与作用(/f/s/q)
- QCom MSM MDP显示驱动一些点的简记
- [改善Java代码]equals应该考虑null值的情景
- 小细节--Extjs中,renderTo 和applyTo的区别
- html button 点击链接
- js短路表达式
- ubuntu导入公钥的方法
- hadoop1.2开发环境搭建
- 在 .NET项目中使用 Redis(2018.10.16)
- webpack-loader是怎样炼成的
- win32之进程概念
- C/C++中的位运算
- Codeforces Round #357 (Div. 2) B. Economy Game 水题
- OC内存管理-黄金法则
- (剑指Offer)面试题38:数字在排序数组中出现的次数
- python基础===getattr()函数使用方法
- hihocoder 1142 三分求极值【三分算法 模板应用】