ElasticSearch实战系列六: Logstash快速入门和实战
前言
本文主要介绍的是ELK日志系统中的Logstash快速入门和实战
ELK介绍
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Filebeat是一个轻量型日志采集器,可以方便的同kibana集成,启动filebeat后,可以直接在kibana中观看对日志文件进行detail的过程。
Logstash介绍
Logstash是一个数据流引擎:
它是用于数据物流的开源流式ETL引擎,在几分钟内建立数据流管道,具有水平可扩展及韧性且具有自适应缓冲,不可知的数据源,具有200多个集成和处理器的插件生态系统,使用Elastic Stack监视和管理部署
Logstash包含3个主要部分: 输入(inputs),过滤器(filters)和输出(outputs)。
inputs主要用来提供接收数据的规则,比如使用采集文件内容;
filters主要是对传输的数据进行过滤,比如使用grok规则进行数据过滤;
outputs主要是将接收的数据根据定义的输出模式来进行输出数据,比如输出到ElasticSearch中.
示例图:
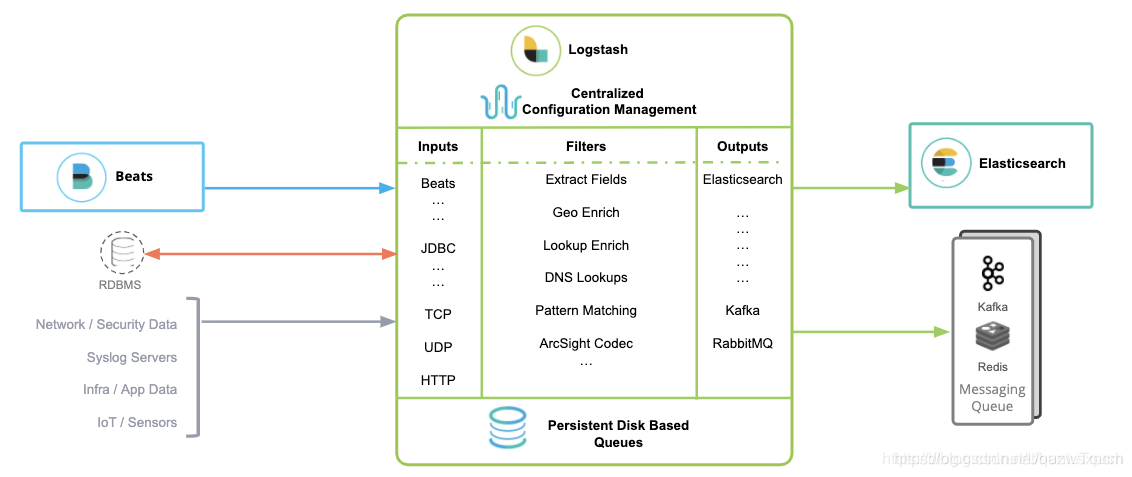
Logstash安装使用
一、环境选择
Logstash采用JRuby语言编写,运行在jvm中,因此安装Logstash前需要先安装JDK。如果是6.x的版本,jdk需要在8以上,如果是7.x的版本,则jdk版本在11以上。如果Elasticsearch集群是7.x的版本,可以使用Elasticsearch自身的jdk。
Logstash下载地址推荐使用清华大学或华为的开源镜像站。
下载地址:
https://mirrors.huaweicloud.com/logstash
https://mirrors.tuna.tsinghua.edu.cn/ELK
ELK7.3.2百度网盘地址:
链接:https://pan.baidu.com/s/1tq3Czywjx3GGrreOAgkiGg
提取码:cxng
二、JDK安装
注:JDK版本请以自身Elasticsearch集群的版本而定。
1,文件准备
解压下载下来的JDK
tar -xvf jdk-8u144-linux-x64.tar.gz
移动到opt/java文件夹中,没有就新建,然后将文件夹重命名为jdk1.8
mv jdk1.8.0_144 /opt/java
mv jdk1.8.0_144 jdk1.8
2,环境配置
首先输入 java -version
查看是否安装了JDK,如果安装了,但版本不适合的话,就卸载
输入
rpm -qa | grep java
查看信息
然后输入:
rpm -e --nodeps “你要卸载JDK的信息”
如: rpm -e --nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.el6.x86_64

确认没有了之后,解压下载下来的JDK
tar -xvf jdk-8u144-linux-x64.tar.gz
移动到opt/java文件夹中,没有就新建,然后将文件夹重命名为jdk1.8。
mv jdk1.8.0_144 /opt/java
mv jdk1.8.0_144 jdk1.8
然后编辑 profile 文件,添加如下配置
输入: vim /etc/profile
export JAVA_HOME=/opt/java/jdk1.8
export JRE_HOME=/opt/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
添加成功之后,输入:
source /etc/profile
使配置生效,然后查看版本信息输入:
java -version
三、Logstash安装
1,文件准备
将下载下来的logstash-7.3.2.tar.gz的配置文件进行解压
在linux上输入:
tar -xvf logstash-7.3.2.tar.gz
然后移动到/opt/elk 里面,然后将文件夹重命名为 logstash-7.3.2
输入
mv logstash-7.3.2.tar /opt/elk
mv logstash-7.3.2.tar logstash-7.3.2
2,配置修改
这里简单介绍一下 inputs,filters、outputs三个主要配置。
inputs
inputs主要使用的几个配置项:
path:必选项,读取文件的路径,基于glob匹配语法。 exclude:可选项,数组类型,排除不想监听的文件规则,基于glob匹配语法。
sincedb_path:可选项,记录sinceddb文件路径以及文件读取信息位置的数据文件。
start_position:可选项,可以配置为beginning/end,是否从头读取文件。默认从尾部值为:end。
stat_interval:可选项,单位为秒,定时检查文件是否有更新,默认是1秒。
discover_interval:可选项,单位为秒,定时检查是否有新文件待读取,默认是15秒
ignore_older:可选项,单位为秒,扫描文件列表时,如果该文件上次更改时间超过设定的时长,则不做处理,但依然会监控是否有新内容,默认关闭。
close_older:可选项,单位为秒,如果监听的文件在超过该设定时间内没有新内容,会被关闭文件句柄,释放资源,但依然会监控是否有新内容,默认3600秒,即1小时。
tags :可选项,在数据处理过程中,由具体的插件来添加或者删除的标记。 type :可选项,自定义处理时间类型。比如nginxlog。
一个简单的input输入示例:
input {
file {
path => "/home/logs/mylog.log"
}
}
上述这段配置表示采集/home/logs/mylog.log的日志,如果是采集整个目录的话,则可以通过*通配符来进行匹配,如
path => "/home/logs/*.log"
表示采集该目录下所有后缀名为.log的日志。
通过logstash-input-file插件导入了一些本地日志文件时,logstash会通过一个名为sincedb的独立文件中来跟踪记录每个文件中的当前位置。这使得停止和重新启动Logstash成为可能,并让它在不丢失在停止Logstashwas时添加到文件中的行数的情况下继续运行。
在调试的时候,我们可能希望取消sincedb的记录功能,使文件每次都能从头开始读取。此时,我们可以这样来做
示例:
input {
file {
path => "/home/logs/mylog.log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
如果想使用HTTP输入,可以将类型改成http,只不过里面的参数有不同而已,tcp、udp、syslog和beats等等同理。
示例:
input {
http {
port => 端口号
}
}
filter
filter主要是实现过滤的功能,比如使用grok实现日志内容的切分等等。
比如对apache的日志进行grok过滤
样例数据:
127.0.0.1 - - [13/Apr/2015:17:22:03 +0800] "GET /router.php HTTP/1.1" 404 285 "-" "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.15.3 zlib/1.2.3 libidn/1.18 libssh2/1.4.2"
grok:
%{COMBINEDAPACHELOG}
这里我们可以使用kibana的grok来进行分析,grok在开发工具中。当然也可以在http://grokdebug.herokuapp.com/网站进行匹配调试。
使用示例:
filter {
grok {
match => ["message", "%{COMBINEDAPACHELOG}"]
}
}
示例图:
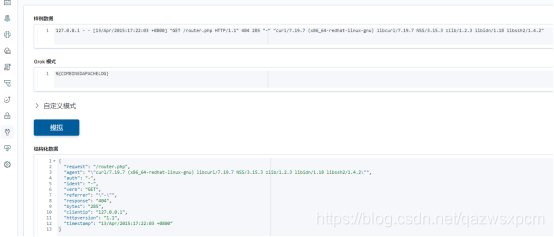
如果没有这方面的需求,可以不配做filter。
output
output主要作用是将数据进行输出,比如输出到文件,或者elasticsearch中。
这里将数据输出到ElasticSearch中,如果是集群,通过逗号可以配置多个节点。
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
}
}
如果想在控制台进行日志输出的话,可以加上stdout配置。如果想自定义输出的index话,也可以加上对应的索引库名称,不存在则根据数据内容进行创建,也可以自动按天创建索引库。
示例如下:
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "mylogs-%{+YYYY.MM.dd}"
}
}
更多logstash配置:https://www.elastic.co/guide/en/logstash/current/index.html
3,使用
demo
在/home/logs/目录下添加一个日志文件, 然后在logstash文件夹中创建一个logstash-test.conf文件,然后在该文件中添加如下配置:
input {
file {
path => "/home/logs/mylog.log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["192.168.9.238:9200"]
}
}
然后在logstash 目录输入如下命令进行启动:
nohup ./bin/logstash -f logstash-test.conf
后台启动:
nohup ./bin/logstash -f logstash-test.conf >/dev/null 2>&1 &
热配置加载启动:
nohup ./bin/logstash -f logstash-test.conf --config.reload.automatic >/dev/null 2>&1 &
启动成功之后,如果是非后台启动,可以在控制台查看数据的传输,如果是后台启动,则可以在logstash的log目录中进行查看。
在kibana展示
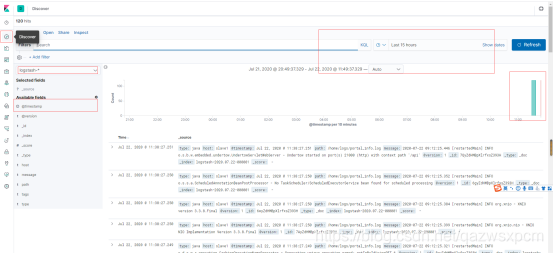
打开kibana,创建一个索引模板,操作如下图所示:
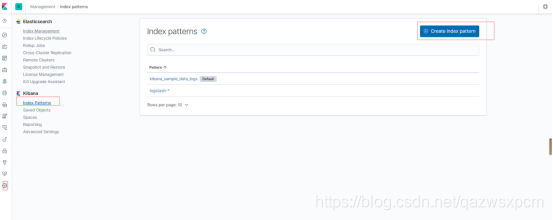
这里因为未指定索引库,logstash使用的是logstash默认的模板,这里选择它就可。
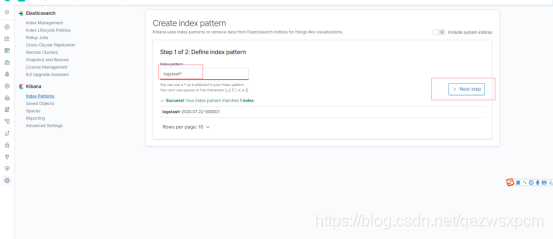
然后创建一个仪表盘,选择刚刚创建的索引库模板,就可以查看数据的情况了。
其它
参考:https://elasticstack.blog.csdn.net/article/details/105973985
- ElasticSearch实战系列一: ElasticSearch集群+Kinaba安装教程
- ElasticSearch实战系列二: ElasticSearch的DSL语句使用教程---图文详解
- ElasticSearch实战系列三: ElasticSearch的JAVA API使用教程
- ElasticSearch实战系列四: ElasticSearch理论知识介绍
- ElasticSearch实战系列四: ElasticSearch理论知识介绍
- ElasticSearch实战系列五: ElasticSearch的聚合查询基础使用教程之度量(Metric)聚合
音乐推荐
原创不易,如果感觉不错,希望给个推荐!您的支持是我写作的最大动力!
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
个人博客出处:http://www.panchengming.com
最新文章
- output_buffering开启
- ExtJS6 TreePanel树节点合上展开显示不同图标
- 清空IE缓存
- poj1125最短路
- JS传参出现乱码(转载)
- Oracle Data Guard
- Spring Bean之间的关系
- Codeforces Round #321 div2
- 用python爬虫抓站的一些技巧总结
- windows phone xaml文件中元素及属性(10)
- 完美解决ubuntu Desktop 16.04 中文版firefox在非root用户不能正常启动的问题
- SQL执行SQL语句提示 "内存不足"(insufficient memory....)的解决方法
- Java中next()和nextLine()
- Mapbox Studio Classic 闪退问题解决方案
- faster rcnn训练自己的数据集
- JedisCluster简单使用
- zabbix使用企业微信发送告警信息
- 动态生成web表-asp.net table
- Awk 从入门到放弃 (7) 动作总结之二
- vim打造简易C语言编辑器(在用2016.7.10)