scrapy的安装,scrapy创建项目
简要:

scrapy的安装
# 1)pip install scrapy -i https://pypi.douban.com/simple(国内源)

一步到位

# 2) 报错1: building 'twisted.test.raiser' extension
# error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++
# Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
# 解决1
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
# Twisted‑20.3.0‑cp37‑cp37m‑win_amd64.whl
# cp是你的python版本
# amd是你的操作系统的版本

# 下载完成之后 使用pip install twisted的路径 安装
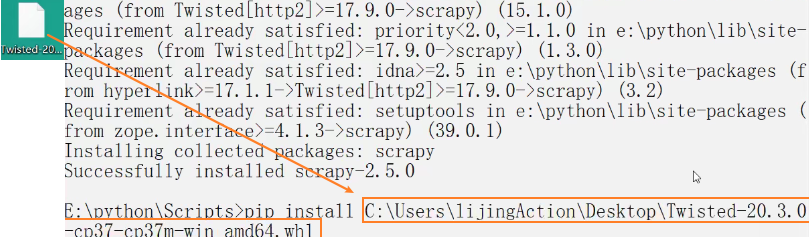
# 切记安装完twisted 再次安装scrapy
pip install scrapy -i https://pypi.douban.com/simple
# 3) 报错2:提示python -m pip install --upgrade pip
# 解决2 运行python -m pip install --upgrade pip
# 4) 报错3 win32的错误
# 解决3 pip install pypiwin32
# 5)使用 anaconda



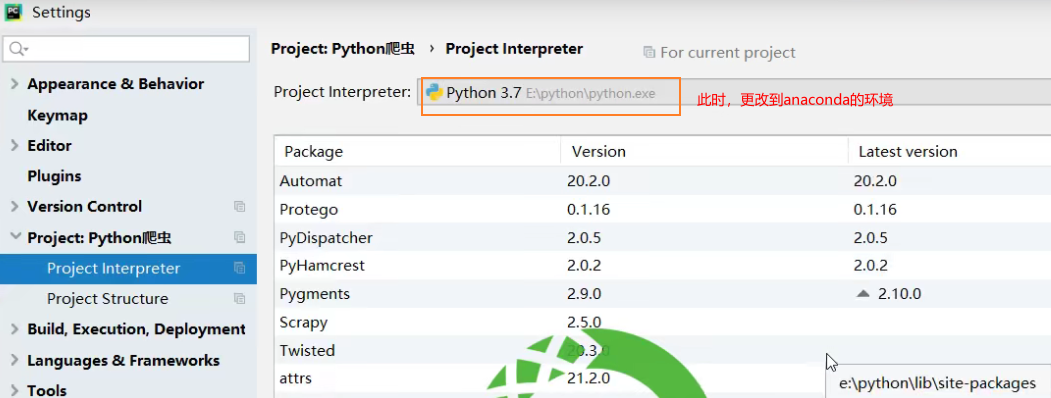

scrapy创建项目
cmd 到项目文件夹中


或者直接拖入
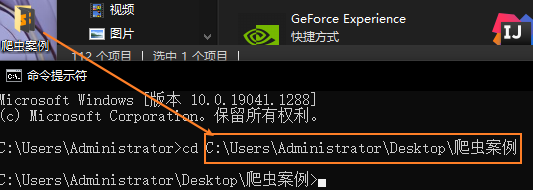
如果返回没有权限,使用管理员运行cmd
scrapy startproject scrapy_baidu
scrapy_baidu\下的文件夹


settings.py

spiders\baidu.py
import scrapy class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 使用的值
name = 'baidu'
# 允许访问的域名
allowed_domains = ['http://www.baidu.com']
# 起始的url地址 指的是第一次要访问的域名
# start_urls 是在allowed_domains的前面添加一个http://
# 在 allowed_domains的后面添加一个/
start_urls = ['http://www.baidu.com/'] # 是执行了start_urls之后 执行的方法 方法中的response 就是返回的那个对象
# 相当于 response = urllib.request.urlopen()
# response = requests.get()
def parse(self, response):
print('你好世界')
最新文章
- Android 2016新技术
- UISegmentedControl和UIStepper的使用
- C语言补码作用
- xib与nib的区别
- OpenGL的gluPerspective和gluLookAt的关系[转]
- 2014.11.12模拟赛【最小公倍数】| vijos1047最小公倍数
- js日历,使用datepicker.js,ui.core.js,jquery-1.7.1.js
- 移动开发平台-应用之星app制作教程
- 深入理解java String 及intern
- vue 基础-->进阶 教程(3):组件嵌套、组件之间的通信、路由机制
- 基于以太坊开发的类似58同城的DApp开发与应用案例
- [HEOI2015]小Z的房间
- Chrome 的 PNaCl 还活着么?
- C#.NET 大型通用信息化系统集成快速开发平台 4.1 版本 - 对外不要提供Delete方法加强软件的安全性
- Pyhton基础知识(一)
- 循序渐进学.Net Core Web Api开发系列【0】:序言与目录
- linux环境mysql的安装主从关系的配置
- xv6/sh.c
- 【cf490】D. Chocolate(素数定理)
- CC3200-LAUNCHXL仿真器驱动异常(未完成)