面向过程编程+模块&导入
面向过程编程+模块&导入
一、面向过程编程(理论+简单代码)
面向过程编程就好比在设计一条产品流水线
首先我们来认识下,什么是面向过程?如果咬文嚼字的话可以这样来理解,面向过程就是面向解决问题的过程进行编程。仔细思考一下,我们在学习和工作中,当我们去实现某项功能
或完成某项任务时,是不是会不自觉的按部就班的罗列出我们要做的事情?(如果没有,建议以后试着步骤化解决问题)。而当我们按着我们罗列的步骤去解决问题时,实质上就是按
照面向过程的思想去解决问题。我们罗列的步骤就是过程,按照步骤解决问题就是面向过程。
传统的面向过程的编程思想总结起来就八个字——自顶向下,逐步细化!
实现步骤如下:
- 将要实现的功能描述为一个从开始到结束按部就班的连续的步骤(过程);
- 依次逐步完成这些步骤,如果某一步的难度较大,又可以将该步骤再次细化为若干个子步骤,以此类推,一直到结束得到想要的结果;
- 程序的主体是函数,一个函数就是一个封装起来的模块,可以实现一定的功能,各个子步骤往往就是通过各个函数来完成的,从而实现代码的重用和模块化编程!
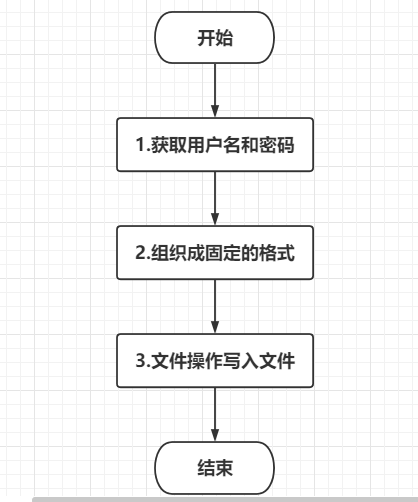


1 # 用户注册功能
2 # 1.获取用户名和密码
3 # 2.组织成固定的格式
4 # 3.文件操作写入文件
5
6
7 def get_into():
8 # 1.获取用户输入信息
9 username = input('输入用户名:').strip()
10 password = input('请输入密码:').strip()
11 if username == None and password == None:
12 print('输入错误,请重新输入')
13 return
14 # 2.输入对应的账户等级
15 user_level = {
16 '1':'user',
17 '2':'admin'
18 }
19 choice_level = input('输入账户等级:').strip()
20 if choice_level in user_level:
21 level_name = user_level.get(choice_level)
22 dell_data(username,password,level_name)
23 else:
24 print('输入错误')
25 return
26
27
28 def dell_data(username,password,level_name):
29 data = f'{username}|{password}|{level_name}\n'
30 login_data(data)
31
32 def login_data(data):
33 with open(r'data.txt', 'a', encoding='utf8') as f:
34 f.write(data)
35 print('写入成功')
36
37 get_into()
面向过程编程
缺陷: 面向过程编程的缺陷在于:一旦要修改功能 那么需要整体改造(牵一发而动全身)
二、模块简介
python语言最早起源于linux运维、胶水语言、调包侠(贬义词>>>褒义词)
模块实际上就是一系列功能的结合体,模块最大的作用就是提高开发效率(站在巨人肩膀上)
2.1 模块三种来源
1.内置的(python解释器自带能够直接导入使用)
2.第三方的(别人写好的发布在网上的 需要先下载后使用)
3.自定义的(自己写的)
2.2 模块的四种表现形式
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包(文件夹)
# 包其实就是多个py文件(模块)的集合
包里面通常会含有一个__init__.py文件
4 使用C编写并链接到python解释器的内置模块
PS:遇到复杂的功能 优先考虑是否有相应的模块可以调用
三、import句式
首次导入md模块发生的事情
1 1.运行导入文件(import句式.py)产生该文件的全局名称空间
2 2.运行md.py文件
3 3.产生md.py全局名称空间 运行md文件内代码 将产生的名字全部存档于md.py名称空间
4 4.在导入文件名称空间产生一个md的名字指向md.py全局名称空间

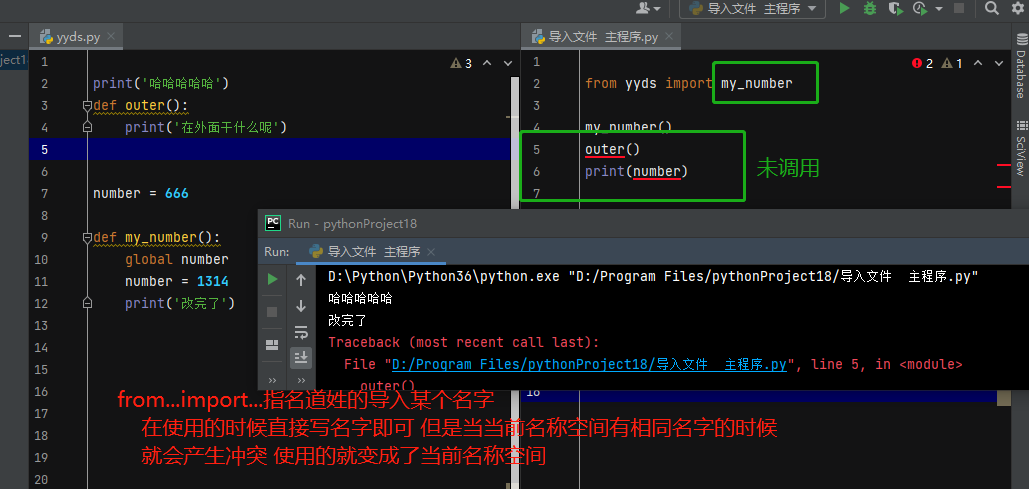
四、from...import...句式
from...import...多次导入也只会导入一次
1.先产生执行文件的全局名称空间
2.执行模块文件 产生模块的全局名称空间
3.将模块中执行之后产生的名字全部存档于模块名称空间中
4.在执行文件中有一个money执行模块名称空间中money指向的值
五、导入模块扩展用法
1.起别名
既可以给模块名起别名,也可以给模块中某个名字起别名。
import mdddddddd as m
from mddddddd import name as n
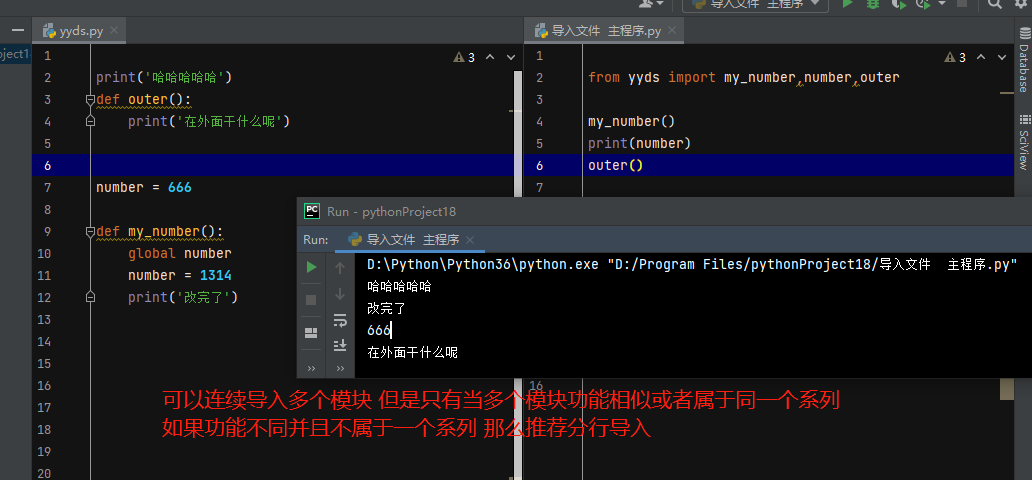
2.连续导入
import 模块名1,模块名2
# 可以连续导入多个模块 但是只有当多个模块功能相似或者属于同一个系列
# 如果功能不同并且不属于一个系列 那么推荐分行导入
import 模块名1
import 模块名2
from 模块名1 import 名字1,名字2,名字3
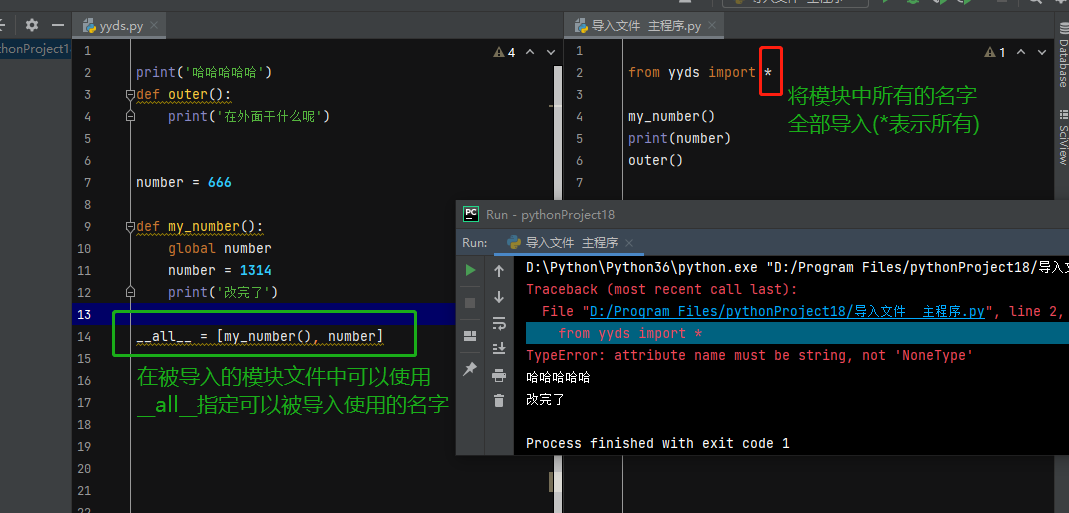
3.通用导入
六、判断文件类型
# 判断py文件是作为模块文件还是执行文件
__name__当文件是执行文件的时候会返回__main__
如果文件是被当做模块导入则返回文件名(模块名) if __name__ == '__main__':
read1()
"""在pycharm中可以直接敲 main按tab键即可自动补全if判断"""
七、循环导入
不允许出现循环导入的现象
不允许出现循环导入的现象
不允许出现循环导入的现象 >>>重说三
八、模块导入的顺序
1.先从内存中查找
2.再去内置模块中查找
3.最后去sys.path系统路径查找(自定义模块) 如果都没有查找到则报错
PS:给py文件名命名的时候尽量不要和模块名重名,后面调用时会很恶心。
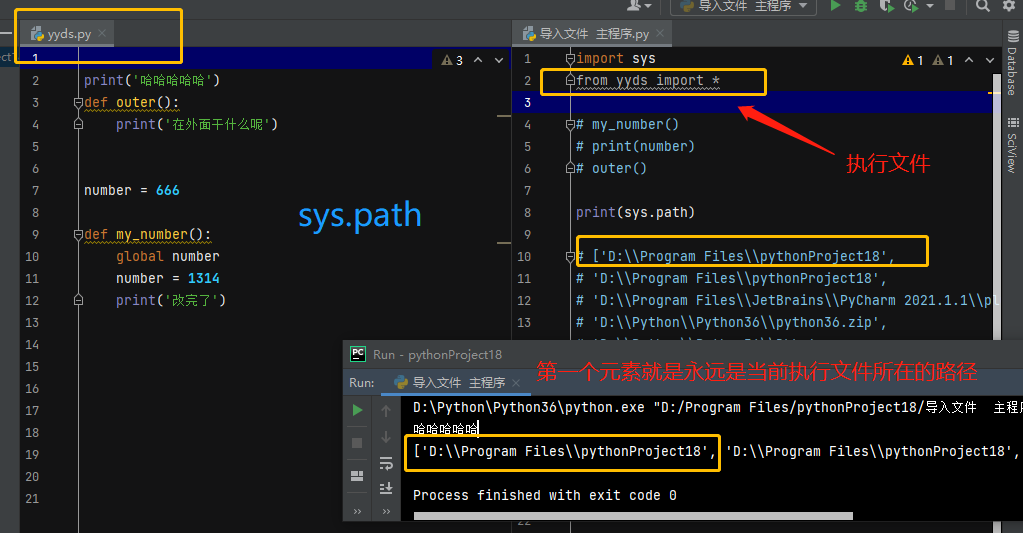
1 import sys
2 print(sys.path) # 结果中第一个元素永远是当前执行文件所在的路径
3
4
5 当某个自定义模块查找不到的时候解决方案
6 1.自己手动将该模块所在的路径添加到sys.path中
7 import sys
8 sys.path.append(r'D:\py20\day18\aaa')
9 2.from...import...句式
10 from 文件夹名称.文件夹名称 import 模块名
11 from 文件夹名称.模块名称 import 名字
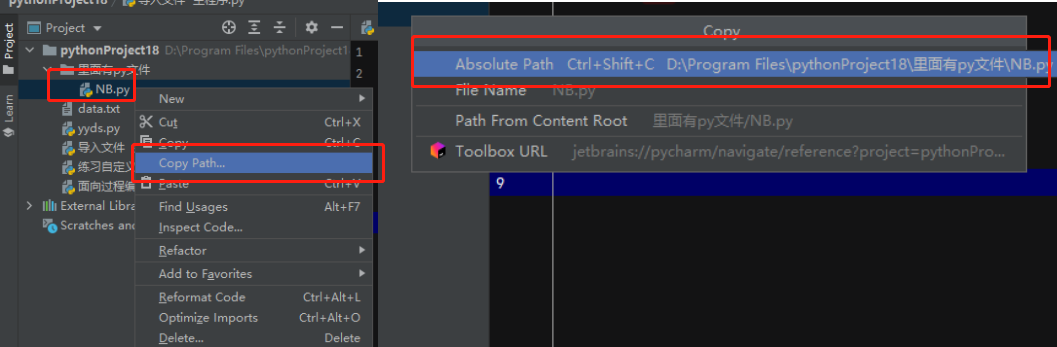
九、绝对导入与相对导入
在程序中涉及到多个文件之间导入模块的情况 一律按照执行文件所在的路径为准
绝对导入:始终按照执行文件所在的sys.path查找模块
1. 使用上文提到的sys.path.append( r ' 路径 ' )
2. 使用最常用的句式:from 文件名.模块名 import 模块名 例如: from yyds import my_number
PS : 注意“import” 后面只是功能名字,不要加后缀,函数也不能加括号()
相对导入:句点符(.) 不建议使用相对导入功能
. 一个点表示当前文件路径
..两个点表示上一层文件路径
相对导入方法,能够打破始终以执行文件为准的规则,只考虑两个文件之间的位置
相对导入只能用在模块文件中 不能在执行文件中使用

最新文章
- 【BZOJ3669】[Noi2014]魔法森林 LCT
- centos7 firewalld
- php利用svn hooks将程序自动发布到测试环境
- 升级到Xcode6.2后 免证书真机调试出错的问题
- PDF firefox转换器
- 讓 MySQL 能夠用 EF6
- JVM中启用逃逸分析
- Android开发中完全退出程序的三种方法
- Ajax编程中,经常要能动态的改变界面元素的样式
- 20160409 javaweb 数据库连接池
- XP系统VPN设置
- 通过命令修改wampserver的mysql密码
- CSS hack技巧
- 设计模式 --> (9)代理模式
- c#获取网络时间并同步本地时间
- VsCode 使用专用编程字体FiraCode
- Docker学习笔记-CentOS7镜像
- 转:java使用Filter过滤器对Response返回值进行修改
- ABP框架系列之四十九:(Startup-Configuration-启动配置)
- ****************VS编码操作实践******************