设置beeline连接hive的数据展示格式
问题描述:beeline -u 方式导出数据,结果文件中含有“|”(竖杠)。
执行的sql为:beeline -u jdbc:hive2://hadoop1:10000/default -e 'select * from tablename' > /home/tmp/result.nb
执行结果如下:

在Beeline中,结果可以被展示为多种格式,格式可以在outputformat参数中设置。下面是支持的输出各式:
- table
- vertical
- xmlattr
- xmlelements
- separated-value formats (csv, tsv, csv2, tsv2, dsv)
其中table、vertical、xmlattr和xmlelements是按照特有的形式展示结果,比如vertical以key-value格式展示,xmlelements以xml格式展示。详情见:
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
separated-value formats展示形式是将一行值按照不同分割符分开,主要包括五种分割输出格式:csv, tsv, csv2, tsv2, dsv,目前csv和tsv已经被csv2和tsv2替代了。dsv,csv2和tsv2是从 Hive 0.14 开始引入的SV输出格式,csv2使用的是逗号,tsv2使用的是tab空格,dsv是可配置的。对于dsv格式,分隔符可以通过用参数 delimiterForDSV 进行设置,默认是 '|'。
对于问题描述可知beeline输出结果中字段之间使用“|”分割的,从前面分析可知, csv2和tsv2格式字段值分割符不可能是“|”,只有输出为dsv格式,分割符可以设置,且默认分割符是“|”。可是在执行beeline时并未设置outputformat和delimiterForDSV 参数的值,说明使用的是Beeline默认的输出格式,从outputformat说明中得知Beeline默认的输出各式为table模式,所以接下来就需要弄清楚table模式下字段分隔符是否为“|”。
首先在BeeLine类中找到展示结果相关的代码,如下图所示:
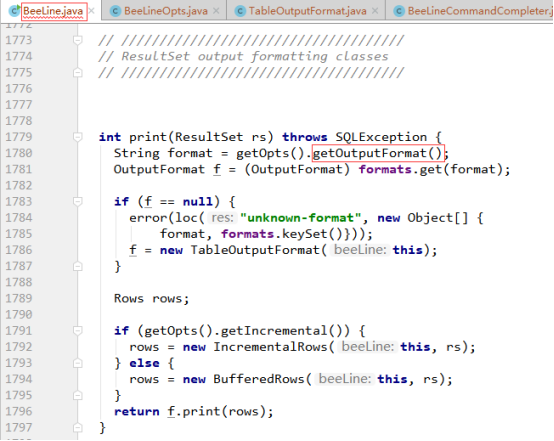
从上图可知,beeline使用的输出格式是通过getOutputFormat()方法获取的,那就进入该方法看看,如下图所示:
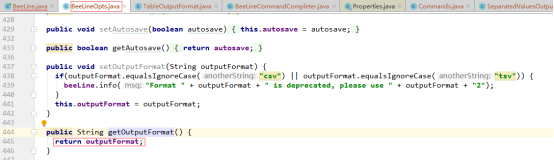
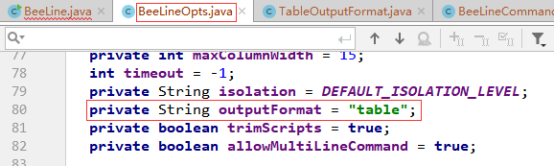
可以看出getOutputFormat()方法直接将outputFormat值返回,接下来就需要看看outputFormat的值从哪来的,通过搜索得知除了outputFormat的默认值外,只有上图中setOutputFormat(String outputFormat)会给outputFormat设置值,可是setOutputFormat(String outputFormat)只有在beeline执行语句中设置outputformat才会被调用,而事实并未在beeline中设置outputformat,所以getOutputFormat()获取的是outputformat默认值,outputformat的默认值为"table",相关代码如下:
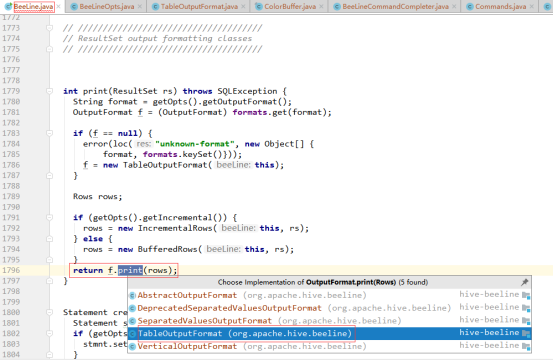
TableOutputFormat类的print()方法实现逻辑如下:
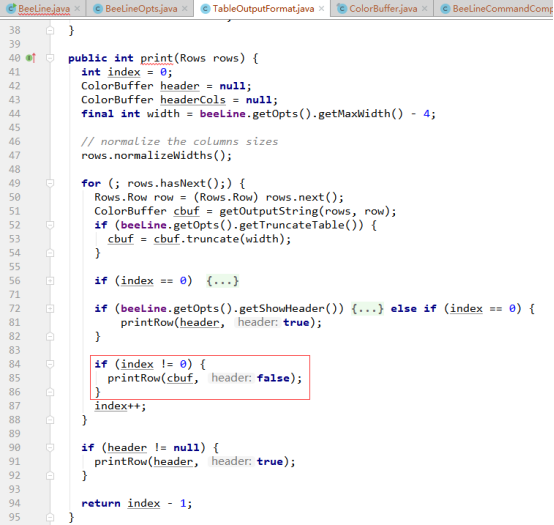
从上图可知,在print()方法中主要是设置表格中表头、表体、表中值的展示格式,这里只关注表中字段值的分割符,因此继续进入图中第85行代码看看对值的格式处理,代码如下:
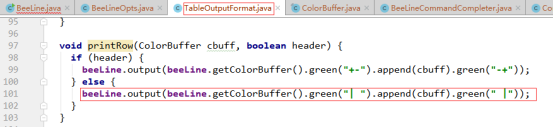
此处要看的是table默认下对值是怎么分割的,故header的值为false,所以会走该段代码的else逻辑,显然从图中红框中的代码可知值之间使用“|”分割的。
经过以上分析可知,如果没有在beeline执行语句中设置outputformat参数,默认展示格式会使用table模式,而table模式下字段值之间的分割符为“|”,因此我们看到beeline展示的结果是以“|”分割的。如果不想使用“|”作为分割符,可以通过以下方式来设置:
方式一:如果值之间用逗号分割,可以在beeline执行语句中加入--outputformat=csv2;如果值之间用tab分割,可以在beeline执行语句中加入--outputformat=tsv2。
(1)将beeline的输出格式设置为csv2,即以逗号作为值之间的分割符。
SQL示例如下:
beeline -u jdbc:hive2://hadoop1:10000/default --outputformat=csv2 -e 'select * from tablename' > /home/tmp/result.nb
展示结果如下:
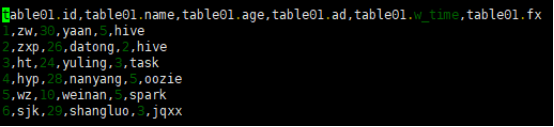
(2)将beeline的输出格式设置为tsv2,即以tab作为值之间的分割符
SQL示例如下:
beeline -u jdbc:hive2://hadoop1:10000/default --outputformat=tsv2 -e 'select * from tablename' > /home/tmp/result.nb
展示结果如下:

方式二:如果方式的分割符不满足需求,想通过其他分割符来分割beeline的执行结果值,可以在beeline执行语句中加入--outputformat=dsv2和--delimiterForDSV=DELIMITER。
(1)将beeline的输出格式设置为dsv2,使用dsv2默认的分割符,即‘|’。
SQL示例如下:
beeline -u jdbc:hive2://hadoop1:10000/default --outputformat=dsv -e 'select * from tablename' > /home/tmp/result.nb
结果展示如下:
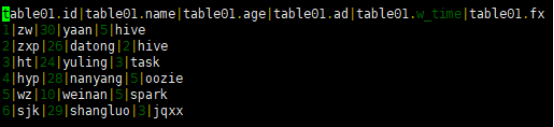
(2)将beeline的输出格式设置为dsv2,并以tab作为值之间得分割符
SQL示例如下:
beeline -u jdbc:hive2://hadoop1:10000/default --outputformat=dsv --delimiterForDSV=$'\t' -e 'select * from tablename' > /home/tmp/result.nb
结果展示如下:

(3)将beeline的输出格式设置为dsv2,并以#作为值之间得分割符
SQL示例如下:
beeline -u jdbc:hive2://hadoop1:10000/default --outputformat=dsv --delimiterForDSV=# -e 'select * from tablename' > /home/tmp/result.nb
结果展示如下:

备注:如果使用dsv2输出格式,值之间的分割符使用默认值,在beeline执行语句中只需要加入--outputformat=dsv就可以;如果使用dsv2输出格式,想通过自定义分割符来对值进行分割,不仅要在beeline执行语句中只需要加入--outputformat=dsv,还需要加入--delimiterForDSV=DELIMITER,实际使用时DELIMITER的值可替换为自定义的分割符。
最新文章
- 一些特殊的URI编码字符
- 解析 Linux 内核可装载模块的版本检查机制
- maven插件
- odoo10 费用报销
- 探索 OpenStack 之(17):计量模块 Ceilometer 中的数据收集机制
- EF-CodeFirst-3搞事
- MySQL Cluster 配置详细介绍
- java11-5 String类的转换功能
- C++学习22 多态的概念及前提条件
- USACO3.42American Heritage(二叉树)
- obj文件的连接问题以及tlib的基本用法
- MYSQL 的 6 个返回时间日期函数
- 2015 8月之后"云计算"学习计划
- Creating Spatial Indexes(mysql 创建空间索引 The used table type doesn't support SPATIAL indexes)
- IE6浏览器的一些问题
- HTML5 之文件操作(file)
- MATCH_PARENT和FILL_PARENT之间的区别?
- Windows10文件目录下添加 Shift+右键打开管理员Powershell窗口
- 爬虫 解析库re,Beautifulsoup,
- .Net Core HttpClient 忽略https证书提醒