Python多线程、线程池及实际运用
我们在写python爬虫的过程中,对于大量数据的抓取总是希望能获得更高的速度和效率,但由于网络请求的延迟、IO的限制,单线程的运行总是不能让人满意。因此有了多线程、异步协程等技术。
下面介绍一下python中的多线程及线程池技术,并通过一个具体的爬虫案例实现具体运用。
多线程
先来分析单线程。写两个测试函数
def func1():
for i in range(500000):
print("func1", i)
def func2():
for i in range(500000):
print("func2", i)
在主函数中调用
if __name__ == "__main__":
func1()
func2()
当程序执行时,按照主程序中的执行顺序,func1全部运行完毕后才会运行func2,这就是单线程的效果。
接下来测试多线程。
先导包
from threading import Thread
改造主函数
thread1 = Thread(target=func1)
thread1.start()
thread2 = Thread(target=func2)
thread2.start()
thread1.join()
thread2.join()
这里的thread.join()是阻塞进程,因为这里主函数中没有
执行效果如下:
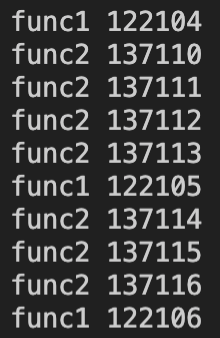
可以看到func1和func2函数分为两个不同的线程同时工作、互不干扰。
线程池
以此类推,如果同时开着20个这样的线程,是否可以同时执行呢?但手动分配这么多线程显然是不可能的,因此引入线程池这一概念,一次开辟一些进程,我们用户直接给线程池提交任务,线程任务的调度交给线程池来完成。这样一来,就能十分方便的分配线程的任务了。
首先导包
from concurrent.futures import ThreadPoolExecutor
改造一下子函数
def func(url):
for i in range(1000):
print(url)
主函数
if __name__ == "__main__":
# 创建线程池
with ThreadPoolExecutor(50) as t:
for i in range(100):
t.submit(func, url=f"线程{i}")
print("over")
我们建立一个线程池,分配50个线程,提交100个任务,让他们去自由分配。现有的50个线程先去拿到了1-50这些任务,当谁先完成就去拿到51个任务,以此类推。相当于50个工人一起干活,互不干涉,显然效率较单人更高一些。
再来看运行结果

线程锁
了解了线程池的基本概念之后就可以去改造我们的爬虫了。但是在此之前该需要了解一个线程锁的概念。先看下面这个例子
from threading import Thread
num = 0
def add():
global num
for i in range(100000):
num += 1
def minus():
global num
for i in range(100000):
num -= 1
if __name__=="__main__":
thread1 = Thread(target=add)
thread2 = Thread(target=minus)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(num)
开辟两个线程,一个做自增一个做自减,他们两个同时运行,按常理num最终的值应为0,但实际运行结果是不稳定的。

由于每个线程运行速度极快,因此在他们的临界点都想对全局变量num操作时会出现竞争状态,有可能出现数值丢失、自增失败的情况,因此需要加入线程锁来控制每次只允许有一个线程对全局变量num进行操作。
import threading
lock = threading.Lock()
lock.acquire()
num += 1
lock.release()
在线程中的关键操作加上线程锁,再跑起来就不会出现竞争状态了。

爬虫实战
要在爬虫中运用到线程池,基本的思路很简单,
1.如何抓取到单个页面的数据
2.上线程池批量抓取
目标:https://www.dydytt.net/html/gndy/dyzz/list_23_1.html
这里仅做线程池的基本实验,具体案例移步这里
先随便写个爬虫拿到第一页的所有电影标题数据
import requests
from lxml import etree
filmNameList = []
def download(url):
global filmNameList
resp = requests.get(url)
resp.encoding="gb2312"
html = etree.HTML(resp.text)
filmName = html.xpath('//table[@class="tbspan"]/tr[2]/td[2]/b/a/text()')
for each in filmName:
filmNameList.append(each)
pass
if __name__=="__main__":
url = "https://www.dydytt.net/html/gndy/dyzz/list_23_1.html"
download(url)
for i in filmNameList:
print(i)
非常轻松的拿到了第一页的数据

接下来上线程池
import requests
import threading
from concurrent.futures import ThreadPoolExecutor
from lxml import etree
filmNameList = []
lock = threading.Lock()
def download(url):
global filmNameList
resp = requests.get(url)
resp.encoding="gb2312"
html = etree.HTML(resp.text)
filmName = html.xpath('//table[@class="tbspan"]/tr[2]/td[2]/b/a/text()')
for each in filmName:
lock.acquire()
filmNameList.append(each)
lock.release()
resp.close()
if __name__=="__main__":
with ThreadPoolExecutor(5) as t:
for i in range(1, 11):
url = f"https://www.dydytt.net/html/gndy/dyzz/list_23_{i}.html"
t.submit(download, url=url)
for i in filmNameList:
print(i)
print(f"total_len is {len(filmNameList)}")
我们给线程池分配了5个线程,抓了前10页共250条数据。
 ****
****
最新文章
- ajax 多级联动 下拉框 Demo
- cron(CronTrigger)表达式用法
- DEDE建站之图片标签技巧指南
- 【Java基础】通用程序设计
- JAVA基础学习之命令行方式、配置环境变量、进制的基本转换、排序法、JAVA文档生成等(1)
- Collection 和 Collections的区别。
- HW5.19
- python 计算apache进程占用的内存大小以及占物理内存的比例
- 【iOS开发】 常遇到的Crash和Bug处理
- strchr,wcschr 和strrchr, wcsrchr,_tcschr,_tcsrchr功能
- C#基础原理拾遗——引用类型的值传递和引用传递
- JS一周游~(基础、运算符、条件语句)
- Spark_总结五
- H5游戏见缝插针开发
- 使用netflix Zuul 代理你的微服务
- open
- 微信小程序wx.uploadFile 上传文件 的两个坑
- django之信号
- TCP学习总结(三)
- bzoj2208 连通数(bitset优化传递闭包)
热门文章
- shell脚本 系统信息检测
- 测试工具_http_load
- mapbox获取各种经纬度
- LuoguP3880 [JLOI2008]提示问题 题解
- vim 默认配置
- 使用docker-compose一起安装kafka(zookeeper)
- 【LeetCode】1022. Sum of Root To Leaf Binary Numbers 解题报告(Python)
- 【LeetCode】829. Consecutive Numbers Sum 解题报告(C++)
- 【嵌入式】keil不识别野火高速dap的问题
- ☕【难点攻克技术系列】「海量数据计算系列」如何使用BitMap在海量数据中对相应的进行去重、查找和排序