week_6
Andrew Ng 机器学习笔记 ---By Orangestar
Week_6 (1)
In Week 6, you will be learning about systematically improving your learning algorithm. The videos for this week will teach you how to tell when a learning algorithm is doing poorly, and describe the 'best practices' for how to 'debug' your learning algorithm and go about improving its performance.
1. Deciding What to Try Next
如何改进算法?
- 使用更多样本
- 尝试更少的特征参数
- 尝试用更多的特征参数
- 尝试多元参数
- 试着降低或者升高正则参数
但是,选择一种有效的方法是困难的
所以,我们需要评估一个机器学习算法的性能的方法
Machine learning diagnostic
定义:

2. Evaluating a Hypothesis
如何评估假设函数以及避免过拟合和欠拟合?
如何评价假设函数?
将数据分割:按照某个比例
1.常用训练集
2.测试集
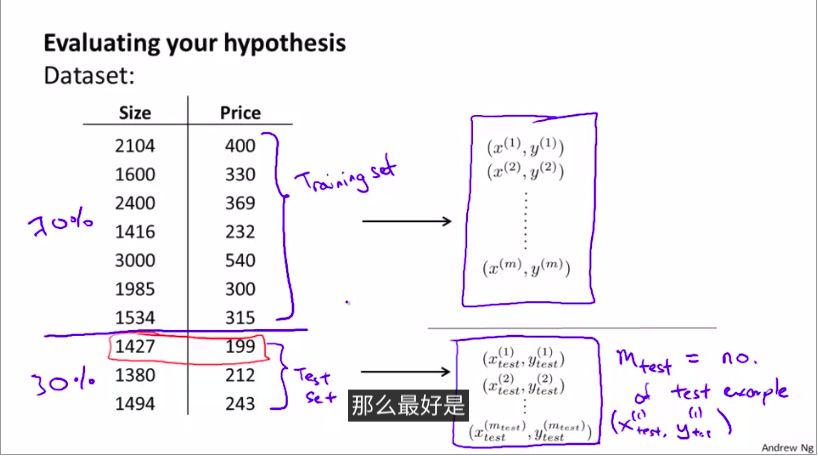
基本步骤:
- (回归问题):(线性回归)

(分类问题):(逻辑回归)
差不多,用测试集评估。
问题是:如何计算error(0/1)?
其实和之前差不多,要定义决策界限

用0/1错分率来定义error
总结:

3. Model Selection and Train/Validation /Test Sets
模型选择问题//训练集//验证集//测试集
模型选择:

还需要选择一个参数d. 也就是最高次数。
可以逐个选择,然后逐个算出测试集的误差函数。
然后观察哪个最小。
而且,这样选出的模型,可能仅仅是可以很好的拟合测试集,但是其他的说不定。所以,我们仅仅是用测试集来拟合样本。不公平!
所以,我们可以用 交叉验证集!cross validation set

现在把数据集分为3个部分:

就是说,验证是最好的模型,可以用交叉验证集来检验!然后,就没有和测试集进行拟合,回避了测试集的嫌疑

一般的比例为:

4. Diagnosing Bias vs. Variance
如何判断一个算法,是和方差有问题还是和偏差有问题?
用图像来直观理解
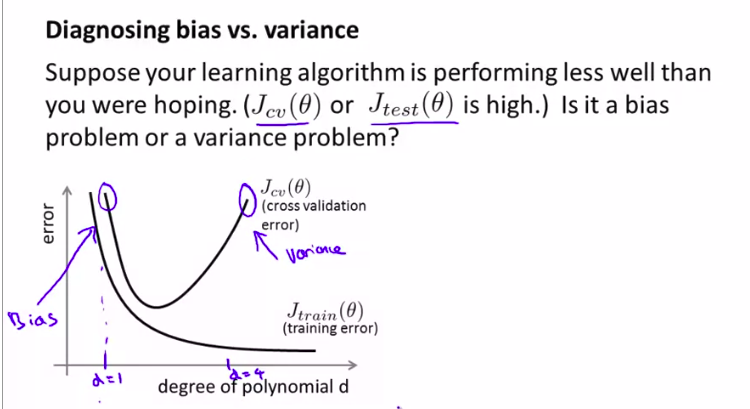
注意理解bias error 和 variance error
也就是,区分过拟合和欠拟合的情况

当然,这两种情况都是不好的!
5. Regularization and Bias / Variance
更深入地 探讨一下偏差和方差的问题 讨论一下两者之间 是如何相互影响的 以及和算法的正则化之间的相互关系
首先,我们来看一下正则项:
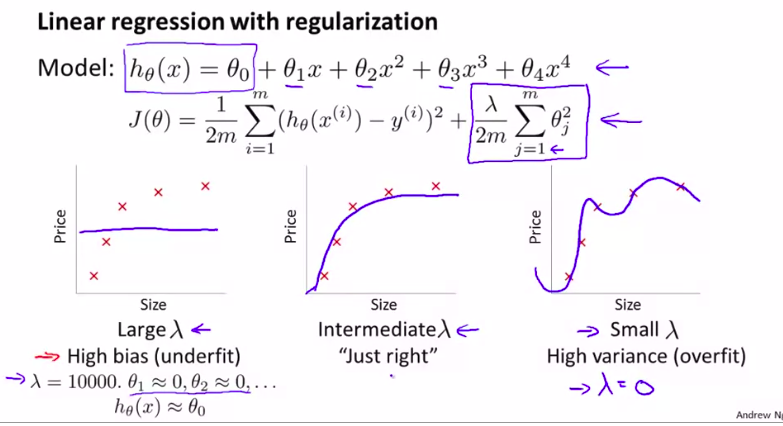
当然,我们需要先用交叉验证集上进行选择模型
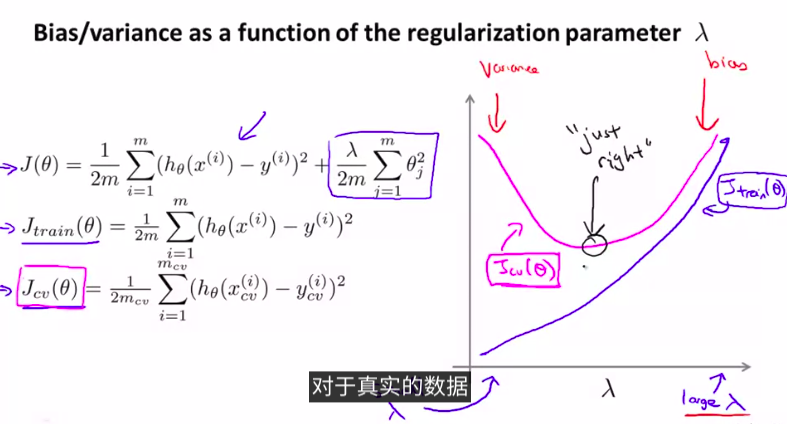
再试着用哪一个正则项更好。来得到最小的J_train_
如图:
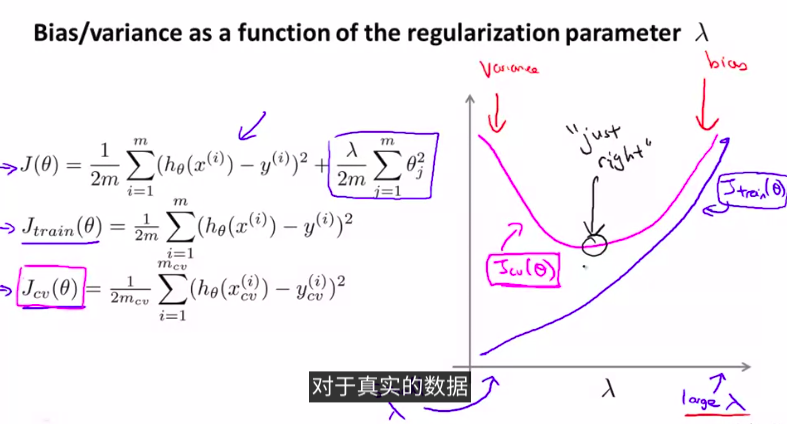
总结步骤:

- for each λ go through all the models to learn some Θ.
- without regularization or λ = 0
以上两点很重要
6. 学习曲线learning curves
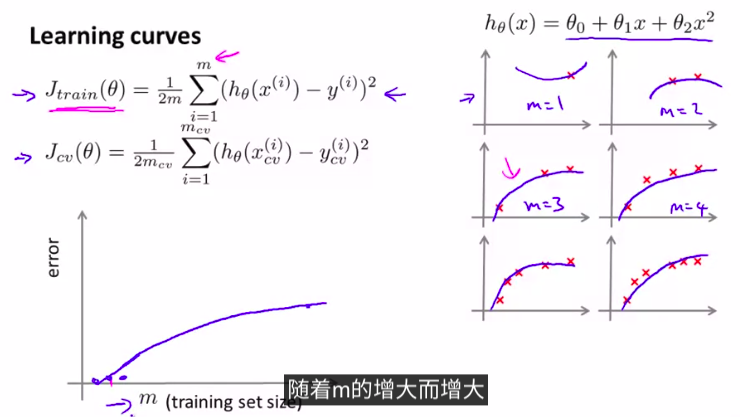
一种模型,当训练集的样本增加的时候,error是越来越大的
- 高偏差情况high bias(欠拟合)
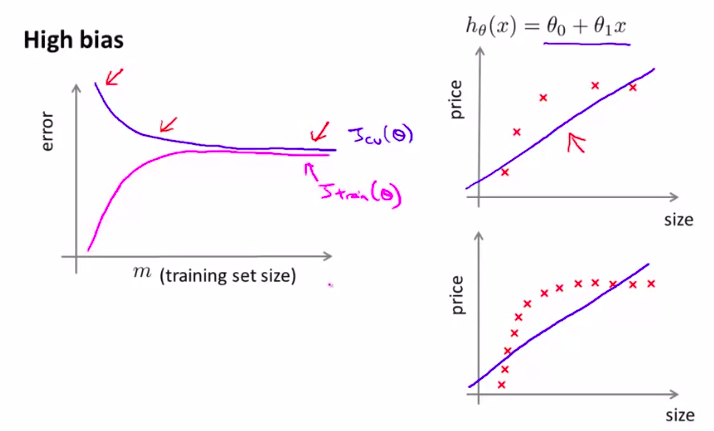
结论:

所以,如果模型是高偏差,再多的样本来拟合,也不太会管用
- 高方差情况high variance(过拟合)
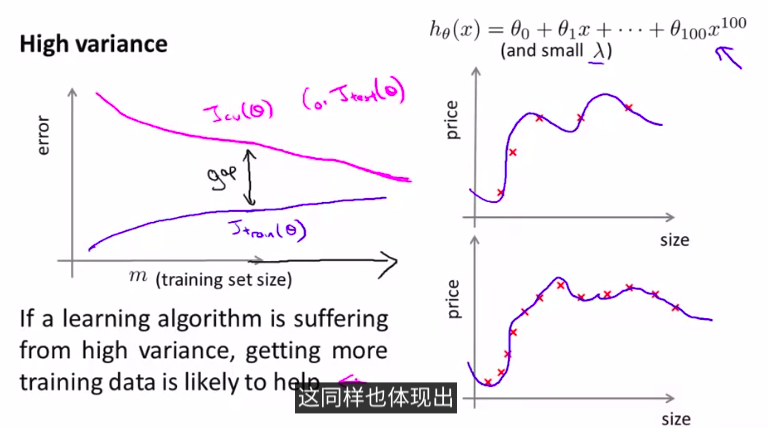
这种情况下,使用更多的样本是有帮助的
总结:
画出曲线,可以更容易看出是高偏差还是高方差的问题,然后来选择改进算法




7. Deciding What to Do Next Revisited
当我们发现方差或者偏差出了问题,我们应该怎么做?

如何和神经网络联系/
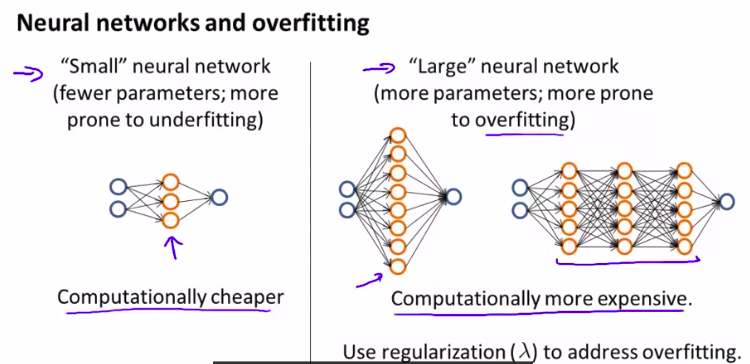
如果发生过拟合,可以使用正则化
但是,计算量更大。如何选择hiding layer?
想用多个隐藏层。可以尝试着数据分割。
总结:
Our decision process can be broken down as follows:
Getting more training examples: Fixes high variance
Trying smaller sets of features: Fixes high variance
Adding features: Fixes high bias
Adding polynomial features: Fixes high bias
Decreasing λ: Fixes high bias
Increasing λ: Fixes high variance.
Diagnosing Neural Networks
- A neural network with fewer parameters is prone to underfitting. It is also computationally cheaper.
- A large neural network with more parameters is prone to overfitting. It is also computationally expensive. In this case you can use regularization (increase λ) to address the over-fitting.
Using a single hidden layer is a good starting default. You can train your neural network on a number of hidden layers using your cross validation set. You can then select the one that performs best.
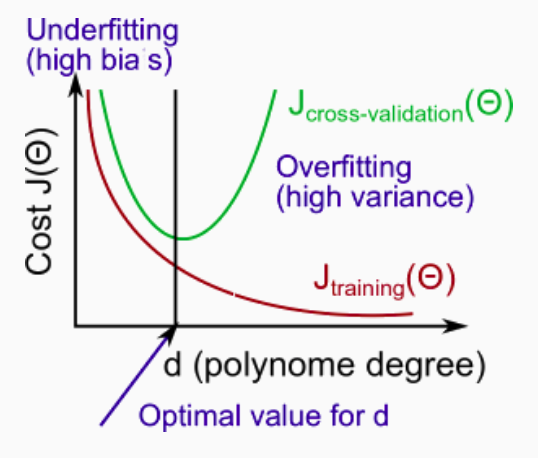
Model Complexity Effects:
- Lower-order polynomials (low model complexity) have high bias and low variance. In this case, the model fits poorly consistently.
- Higher-order polynomials (high model complexity) fit the training data extremely well and the test data extremely poorly. These have low bias on the training data, but very high variance.
- In reality, we would want to choose a model somewhere in between, that can generalize well but also fits the data reasonably well.
最新文章
- Quartz2D之生成圆形头像、打水印、截图三种方法的封装
- sql连着function使用
- checkbox选中与取消选择
- Apache Shiro(安全框架)
- [转载]WiFi有死角? 巧用旧无线路由器扩展覆盖
- 【TCP】超时与重传
- 使用扩展方法(this 扩展类型)
- Getting Started with Mongoose and Node.js – A Sample Comments System | Dev Notes
- 最小生成树之Kruskal
- WinForm中关于控件焦点的问题
- C#小写人民币转大写
- HTTP 长连接 使用场景
- AOP in dotnet :AspectCore的参数拦截支持
- windows下 gvim8.0 编译器配置
- javascript原始值和对象引用
- CentOS 6忘记root密码的解决办法
- GIT-Bonobo.Git.Server的使用
- Struts S2-048 RCE漏洞分析
- python tcp 实时抓包
- yii源码一 -- CComponent