hashlib加密模块 subprocess模块 logging日志模块
hashlib加密模块
简介
- 何为加密
将明文数据处理成密文数据 让人无法看懂 - 为什么加密
保证数据的安全 - 如何判断数据是否是加密的
一串没有规律的字符串(数字、字母、符号) - 密文的长短有何讲究
密文越长表示使用的加密算法(数据的处理过程)越复杂 - 常见的加密算法有哪些
md5、base64、hmac、sha系列
hashlib使用流程
import hashlib
# 1.选择加密算法
md5 = hashlib.md5()
# 2.传入明文数据
md5.update(b'hello') # 只能接受bytes类型
# 3.获取加密密文
res = md5.hexdigest()
print(res) # 5d41402abc4b2a76b9719d911017c592
hashilb加密模块使用说明
明文绑定密文
- 加密算法不变时,输入的明文一样,输出的密文也就一样
import hashlib
md5 = hashlib.md5()
md5.update(b'hello')
res = md5.hexdigest()
print(res) # 5d41402abc4b2a76b9719d911017c592
md5_2 = hashlib.md5()
md5_2.update(b'hello')
res2 = md5_2.hexdigest()
print(res2) # 5d41402abc4b2a76b9719d911017c592 # hello进行加密之后的密文是固定的
# 5d41402abc4b2a76b9719d911017c592 = hello
md5_3 = hashlib.md5()
md5_3.update(b'hell')
print(md5_3.hexdigest()) # 4229d691b07b13341da53f17ab9f2416 # 修改了一个字母 结果完全不同 # 但是密文的长度相同
密文长度不变
- 相同的算法,最后得出的密文长度是一样的
import hashlib
md5 = hashlib.md5()
md5.update(b'hello world a is apple, are you ok?')
res = md5.hexdigest()
print(res) # 5ba0f222d3f7cc4aa211a7195612f833 # 32位
md5_2 = hashlib.md5()
md5_2.update(b'a')
res2 = md5_2.hexdigest()
print(res2) # 0cc175b9c0f1b6a831c399e269772661 # 输入字符串长度不同 密文长度相同 32位
sha1 = hashlib.sha1()
sha1.update(b'a')
print(sha1.hexdigest()) # 86f7e437faa5a7fce15d1ddcb9eaeaea377667b8 40位
多次传入
- 一次性传 和多次传是一样的 只要拼接起来是相同的即可
import hashlib
md5 = hashlib.md5()
md5.update(b'hello~world~python~666') # 一次性传可以
print(md5.hexdigest()) # af9a44cbf7784b1a58e23c0a40df2bbc
md5_2 = hashlib.md5()
md5_2.update(b'hello') # 分多次传也可以
md5_2.update(b'~world') # 分多次传也可以
md5_2.update(b'~python~666') # 分多次传也可以
print(md5_2.hexdigest()) # af9a44cbf7784b1a58e23c0a40df2bbc # 得出的密文是相同的
密文不可解密原因
- 加密的结果一般是不可以反解密的 只能通过撞库的方法解密
md5不可逆的原因是因为它是一种散列函数,使用的是hash算法,在计算过程中原文的部分信息是丢失了的。也就是说,MD5的运算过程存在信息丢失。由于不知道运算过程中会有多少个进位在哪一步被丢弃,因而仅仅根据MD5的计算过程和得到的最终结果,是无法逆向计算出明文的。这才是MD5不可逆的真正原因。
既然md5无法逆运算,为什么网上还有很多声称可以解密md5的网站,其实这不是真正意义上的解密了。网上搜索到的md5解密网站是成千上万的md5原文和md5密文,放到了数据里,所谓的解密就是从数据库里查询有没有原文。
这种网站相当于md5的字典库,就是原文和密文的的对应表,数据量很庞大,上万亿级别,如果用户的密文正好在字典库里面,一查对应表就行。很多用户的密码都不够复杂,所以很容易被这种方式生成出来。一般网上这种md5解密网站能解密8位数左右的纯数字密码。密码太复杂的话,要根据这个网站的数据库和数据量而定。
加盐处理(salt)
普通加盐
在明文里面添加一些额外的干扰项
import hashlib
# 1.选择加密算法
md5 = hashlib.md5()
# 2.传入明文数据
md5.update('干扰项'.encode('utf8')) # 传入事先设定好的干扰项
md5.update(b'hello python') # 传入真正的明文数据
# 3.获取加密密文
res = md5.hexdigest()
print(res) # 4078474b483814b00a9f28c86184981d
动态加盐
由于干扰项也有泄露的可能 动态加盐就是使用动态变化的干扰项。
如:当前时间、用户名的一部分
import hashlib
import time
now_time = str(time.time()).encode('utf8') # 时间戳 转 bytes类型
md5 = hashlib.md5()
md5.update(now_time) # 传入bytes类型的时间信息
md5.update(b'hello python') # 传入真正的明文数据
print(md5.hexdigest()) # 13a7c50b2c696ac85a267475d6a55ebd
time.sleep(2)
now_time = str(time.time()).encode('utf8') # 时间戳 转 bytes类型
md5_2 = hashlib.md5()
md5_2.update(now_time) # 传入bytes类型的时间信息
md5_2.update(b'hello python') # 传入真正的明文数据
print(md5_2.hexdigest()) # f98174f8a27c4bdc05282fc968075eb6 # 由于加入时间戳作为干扰项,导致两次的密文不同
加密实际运用
用户密码加密
用户密码加密 只存放密文 只比对密文
import hashlib
password = b'123'
md5 = hashlib.md5()
md5.update(password) # 传入bytes类型
db_data = md5.hexdigest() # 保存密文到数据库
print(f'数据库内存放的密文:{db_data}')
# 服务端的数据库保存密文即可 下次输入密码时 直接比对密文
user_login = input('请输入密码>>').strip() # 用户登录
user_login = user_login.encode('utf8') # 转bytes类型
md5_2 = hashlib.md5()
md5_2.update(user_login)
user_encrypt_data = md5_2.hexdigest()
print(f'你的输入转换成密文:{user_encrypt_data}')
if user_encrypt_data == db_data:
print('登录成功')
else:
print('登录失败')
文件安全性校验
当你在网站上下载软件时,官方往往会给你提供一个md5密文,用于校验文件完整性。
背后其实做了这样一件事:
当你先下载好二进制数据时,先别急着打开软件,先把二进制数据用md5算法加密得到一串密文,拿这串密文和官网的密文进行比对,如果相同,那说明文件是安全的。如果修改了文件,会导致两次密文不一样,这样就可以防止下到被篡改,被加入病毒的文件。
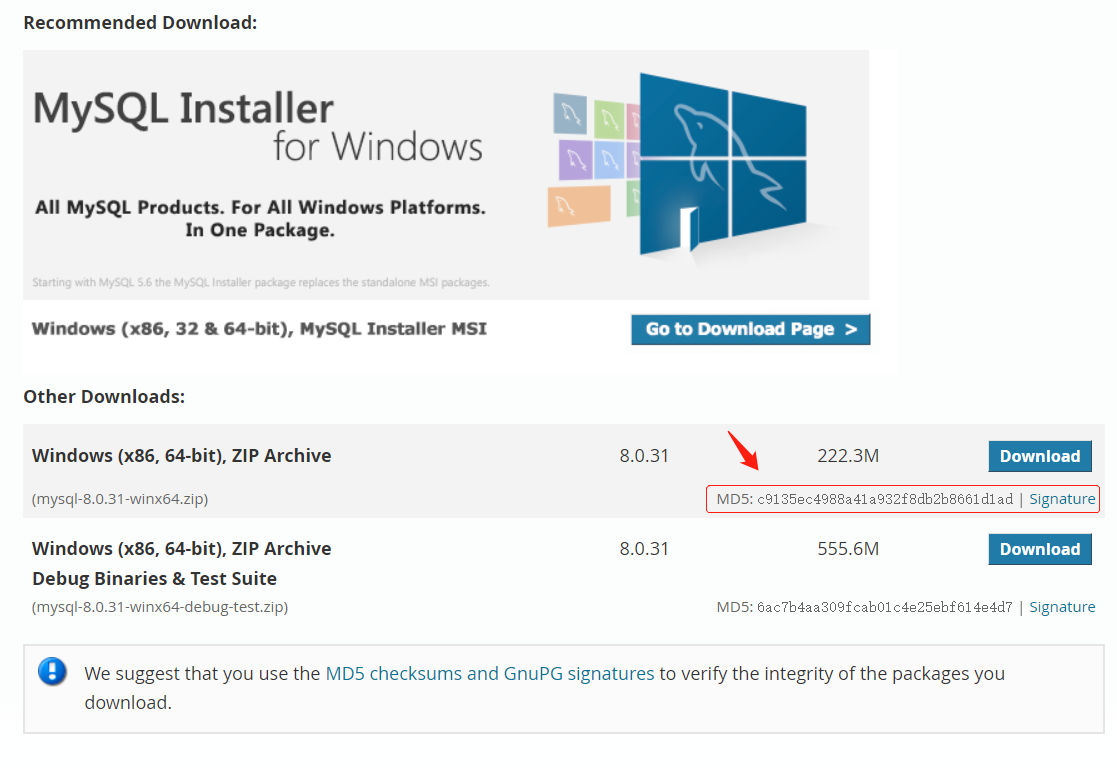
文件内容一致性校验
可能文件名不同,但是文件内部的数据是一样的,有没有办法进行校验呢?
有没有发现 有时候百度网盘上传的速度特别快 有时特别慢 这是什么原因呢?
百度网盘上传时 先读取文件 将文件内容加密生成一个密文 然后去数据库找有没有相同的密文 因为别的用户可能也传过相同的内容 如果数据库有相同的密文 此时百度网盘就会直接从自己的数据库将文件内容复制一份给你 此时就不需要上传了 所以表面上看就是你上传的特别快。
import hashlib
# 1.文件内容相同 但是文件名不同
with open('a.txt', 'w', encoding='utf8') as f:
f.write('hellomiku') # 写入数据
with open('b.txt', 'w', encoding='utf8') as f:
f.write('hellomiku') # 写入相同的数据
# 2.读出数据
with open('a.txt', 'r', encoding='utf8') as f:
a_data = f.read().encode('utf8')
with open('b.txt', 'r', encoding='utf8') as f:
b_data = f.read().encode('utf8')
# 3.生成密文
md5 = hashlib.md5()
md5.update(a_data)
a_md5_data = md5.hexdigest()
print(f'a文件内容加密结果:{a_md5_data}')
md5_2 = hashlib.md5()
md5_2.update(b_data)
b_md5_data = md5_2.hexdigest()
print(f'b文件内容加密结果:{b_md5_data}')
# 4.比较密文 校验内容一致性
if a_md5_data == b_md5_data:
print('文件内容相同')
else:
print('文件内容不相同')
大文件校验完整性
从文件二进制截取部分内容加密即可 可以自行设定截取多少段数据 一次截取数据的大小。这种方案会有偶然事件的发生。
比特流技术
比如x雷的下载,某个链接下载的人多,你的下载速度就越快。是因为很多视频提供厂商使用比特流技术,你可以从x雷下载文件,x雷也可以读取你电脑上的文件。当发现你电脑存在用户需要下载的文件,就会直接从你的电脑下载,每个用户既是使用者也是服务者。
subprocess模块
模拟操作系统终端 执行命令并获取结果
import subprocess
res = subprocess.Popen(
'ipconfig', # 操作系统要执行的命令
shell=True, # 固定配置
stdin=subprocess.PIPE, # 输入命令
stdout=subprocess.PIPE, # 输出结果
)
print('正确结果', res.stdout.read().decode('gbk')) # 获取操作系统执行命令之后的正确结果
print('错误结果', res.stderr) # 获取操作系统执行命令之后的错误结果 # 没有就返回None
logging日志模块
日志简介
日志是有级别的 只有warning及以上级别的日志才会在终端显示
日志是有从属的对象 默认情况下日志属于root
1.如何理解日志
简单的理解为是记录行为举止的操作(历史史官)
2.日志的级别
五种级别
3.日志模块要求
代码无需掌握 但是得会CV并稍作修改
import logging
# logging.debug('debug message')
# logging.info('info message')
# logging.warning('warning message')
# logging.error('error message')
# logging.critical('critical message')
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf8',)
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
level=logging.ERROR
)
logging.error('你好')
logging使用流程
- 产生日志
- 过滤日志
基本不用 因为在日志产生阶段就可以控制想要的日志内容 - 输出日志
- 日志格式
import logging
# 1.日志的产生(准备原材料) logger对象
logger = logging.getLogger('购物车记录')
# 2.日志的过滤(剔除不良品) filter对象>>>:可以忽略 不用使用
# 3.日志的产出(成品) handler对象
hd1 = logging.FileHandler('a1.log', encoding='utf-8') # 输出到文件中
hd2 = logging.FileHandler('a2.log', encoding='utf-8') # 输出到文件中
hd3 = logging.StreamHandler() # 输出到终端
# 4.日志的格式(包装) format对象
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s: %(message)s',
datefmt='%Y-%m-%d',
)
# 5.给logger对象绑定handler对象
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
# 6.给handler绑定formmate对象
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
# 7.设置日志等级
logger.setLevel(10) # debug
# 8.记录日志
logger.debug('写了半天')

日志配置参数
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
日志配置字典
import logging
import logging.config
# 定义日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定义文件路径
logfile_path = 'a3.log'
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
# '购物车记录': {
# 'handlers': ['default','console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)传递
# }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
# logger1 = logging.getLogger('购物车记录')
# logger1.warning('尊敬的VIP客户 晚上好 您又来啦')
# logger1 = logging.getLogger('注册记录')
# logger1.debug('jason注册成功')
logger1 = logging.getLogger('红浪漫顾客消费记录')
logger1.debug('慢男 猛男 骚男')
了解如何使用logging配置字典
import logging
import logging.config # 这里是一个小bug 必须加这一行代码
# 1.定义日志输出格式
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字 # 标准日志格式
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' # 简易版日志格式
# 2.自定义文件路径
logfile_path = 'a3.log' # 文件路径
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format # 在上面
},
'simple': {
'format': simple_format # 在上面
},
}, # 对日志格式的设置 (标准格式 or 简易格式)
'filters': {}, # 过滤日志 我们不用这个
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志
'default': {
'level': 'INFO', # 收集info及以上的日志
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件路径 看上面
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M 超过5M会新生成一个文件
'backupCount': 5, # 这个参数限制最多创建5个文件保存日志内容 如果继续超过5M 则会覆盖第1个文件
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
}, # hander对象的配置 如何——>打印到终端 如何——>打印到文件 (注意level)
'loggers': {
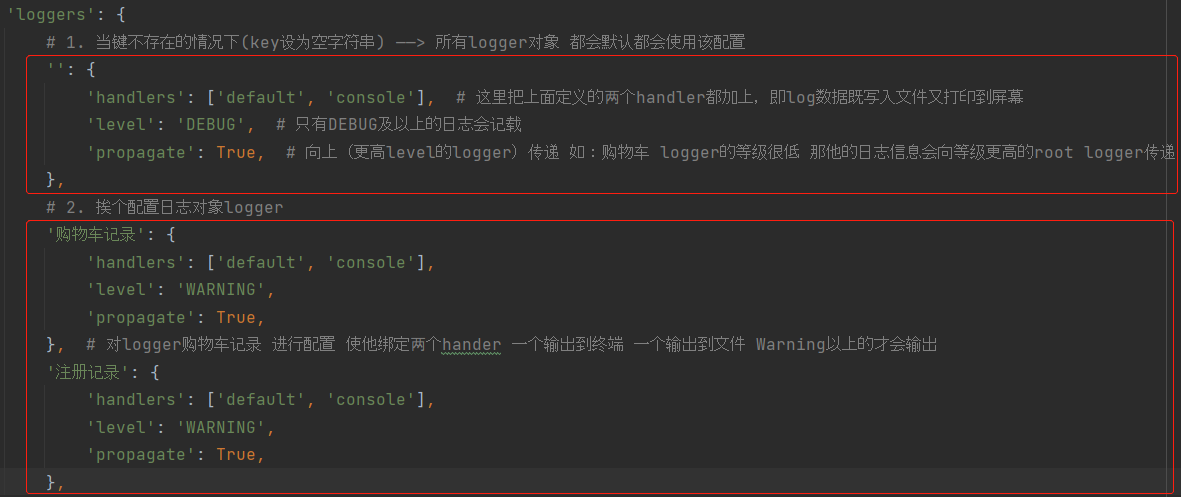
# 1. 当键不存在的情况下(key设为空字符串) ——> 所有logger对象 都会默认都会使用该配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # 只有DEBUG及以上的日志会记载
'propagate': True, # 向上(更高level的logger)传递 如:购物车 logger的等级很低 那他的日志信息会向等级更高的root logger传递
},
# 2. 挨个配置日志对象logger
# '购物车记录': {
# 'handlers': ['default', 'console'],
# 'level': 'WARNING',
# 'propagate': True,
# }, # 对logger购物车记录 进行配置 使他绑定两个hander 一个输出到终端 一个输出到文件 Warning以上的才会输出
# '注册记录': {
# 'handlers': ['default', 'console'],
# 'level': 'WARNING',
# 'propagate': True,
# },
}, # 日志对象的配置 如:购物车日志 注册日志 这些日志对应哪些handler 有两种配置方法!!
} # 配置信息字典 会使用即可 有余力可以进行了解
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置(重要 这行代码要记住)
# 3.这上面全都是一些对logging模块的配置 下面是具体使用
# 4.创建三个不同的日志logger 但是这三个不同的日志都写入同一个文件
logger1 = logging.getLogger('购物车记录')
logger1.warning('尊敬的VIP客户 晚上好 您又来啦')
logger1 = logging.getLogger('注册记录')
logger1.warning('mike注册成功')
logger1 = logging.getLogger('红浪漫顾客消费记录')
logger1.debug('慢男 猛男 骚男')
整体框架
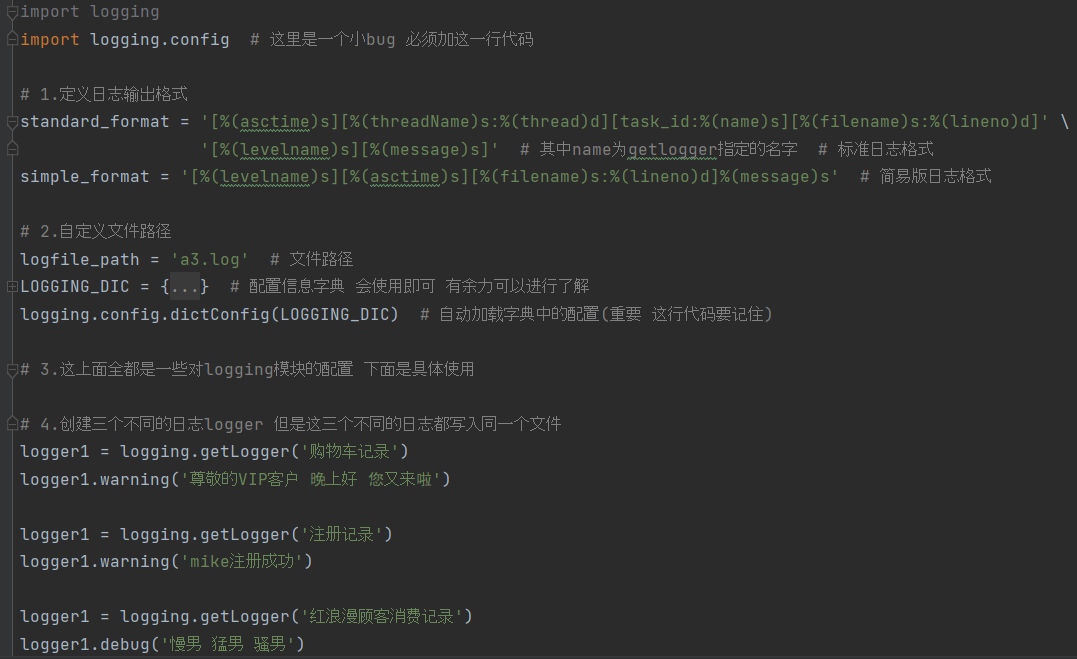
配置字典参数展示

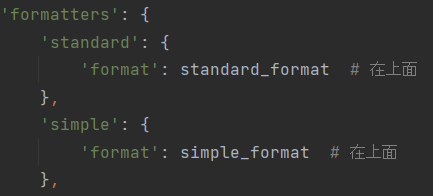
配置字典formatters参数
配置字典handlers参数
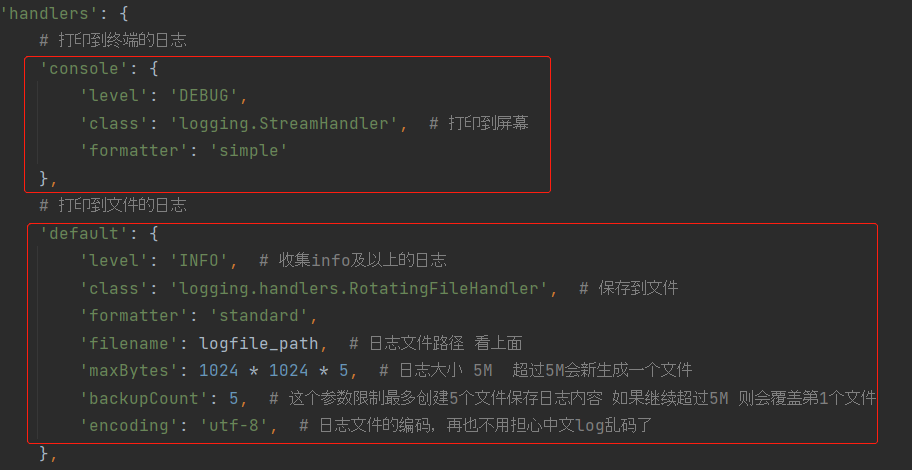
配置字典handlers参数
ps:两种方法选择其一就好
轻量版配置字典 即插即用
import os
import logging
import logging.config # 必须加这一行代码
# 1.定义日志输出格式
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字 # 标准日志格式
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' # 简易版日志格式
# 2.自定义文件路径
logfile_path = os.path.dirname(__file__) # 文件路径
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
# 打印到终端的日志
'console': {
'level': 'WARNING',
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
# 打印到文件的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler',
'formatter': 'standard',
'filename': logfile_path, # 日志文件路径
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M 超过5M会新生成一个文件
'backupCount': 5, # 创建文件数 超过会覆盖
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
'': {
'handlers': ['default', 'console'],
'level': 'DEBUG',
'propagate': True,
},
},
}
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
ps: 以上配置字典设定了——> 既会打印日志到终端 也会打印日志到文件
终端只打印warning及以上的 文件内打印debug及以上的。
logging使用技巧
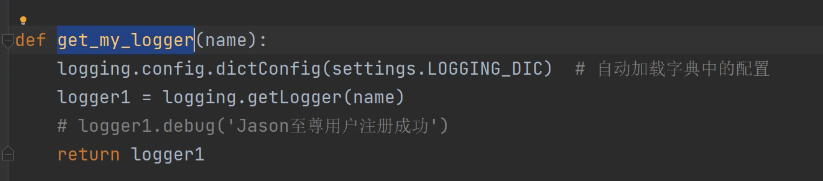
封装日志函数
封装:
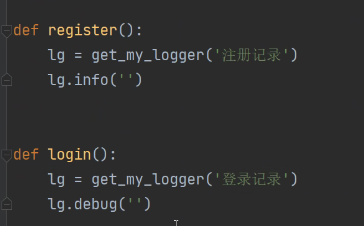
使用:
最新文章
- foreach
- 了解了下spring boot,说一下看法
- Orchard源码分析(6):Shell相关
- Thinkpad X240使用U盘安装Win7系统
- Java for LeetCode 042 Trapping Rain Water
- ubuntu服务器/home/分区替换3T硬盘
- centos6安装redis
- 轮子来袭 vJine.Core 之 AppConfig<T>
- MEF只导出类的成员
- 针对Openlayer3官网例子的简介
- Java for Andriod 第二周学习总结
- MySQL事务锁问题-Lock wait timeout exceeded
- SpringBoot系列: 单元测试
- 4.后台管理系统中的ajax提交或保存的两次模态框确认
- Android开发 ---基本UI组件2:图像按钮、单选按钮监听、多选按钮监听、开关
- 事件委托,js中的一种优化方法
- configure: error: png.h not found.
- D. Babaei and Birthday Cake---cf629D(LIS线段树优化)
- 20165330 2017-2018-2《Java程序设计》课程总结
- 20165330 2017-2018-2 《Java程序设计》第8周学习总结