【CV知识学习】【转】beyond Bags of features for rec scenen categories。基于词袋模型改进的自然场景识别方法
原博文地址:http://www.cnblogs.com/nobadfish/articles/5244637.html
原论文名叫Byeond bags of features:Spatial Pyramid Matching for Recognizing Natural Scene Categories.
这篇文章的中心思想就是基于词袋模型+金字塔结构的识别算法。首先简单介绍词袋模型。
1.词袋模型
Bag of words模型也成为“词袋”模型,在最初多是用来做自然语言处理,Svetlana在进行图片分类时,使用了“词袋”模型。词袋模型的主要思想是利用每一个“word”的频率作为特征来分类,忽略它的单词顺序和语法、句法等要素。
在图像分类应用时,图像每一个提取出来的特征被当做一个单词来考虑,那么一张图片就是一篇文章的,只不过这个文章是由图片特征组成,在此我们并不考虑特征的前后顺序。
Bag Of Words 主要有两步,第一步基础特征提取,第二步,字典生成(高级特征),最后一步,分类器分类。
1.1基础特征提取
Svetlana在此篇论文中选取的基础特征是SIFT算子,每一个SIFT点会提取一个128维的特征向量。SIFT特征点的提取,和特征向量的计算在其他的博客有所介绍不赘述,本实验代码中提取SIFT特征的代码是用的vlfeat库的vl_sift函数。
1.2 字典生成
基础特征提取之后,我们就获得到了“word”,由于word之间有一定的信息冗余和噪音干扰,并且数据量往往很大,直接用来分类可能效果并不好。因此我们需要设计一些“bag”。在此我们是通过聚类实现的,本文中的聚类方法选择的是K-means算法构造,构造的“bag”数量为400。
生成“bag”之后,我们会将“word”在各个bag中的频率作为一幅图像的特征描述向量。如下图

1.3分类器
分类器选用的是比较简单的线性SVM分类器。
2.金字塔结构
对原始的词袋模型加入金字塔结构。
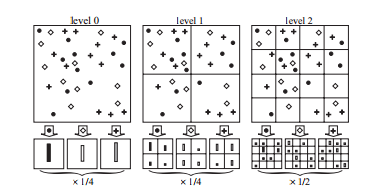
典型词袋模型只是在原图上进行直方图统计,在金字塔结构中,每一层都会将图像分成不同的区域,分别统计直方图。整个金字塔空间统计出的直方图向量则为最终的特征向量,可以用来分类。示意图如图,此图为3层金字塔结构的直方图统计。
最新文章
- C#的循环语句练习
- 01.Sencha ExtJS 6 - Generate Workspace and Application
- Linux inode && Fast Directory Travel Method(undone)
- zepto触摸事件解决方法
- MVC 微信支付
- Linux命令(5):cp命令
- js 判断url的?后参数是否包含某个字符串
- [FML]学习笔记一Cross-validation交叉验证
- 如何在TableView上添加悬浮按钮
- IIS网站发布容易出现的几个问题
- BZOJ 3211 花神游历各国 (树状数组+并查集)
- Base64编码的java实现
- 用C写一个web服务器(四) CGI协议
- Hibernate第四篇【集合映射、一对多和多对一】
- spring jdbc踩坑日记,new JdbcTemplate 为null导致UserDao一直为null
- vue 源码学习----build/config.js
- 精读《Scheduling in React》
- firewall centos
- UVA1479 Graph and Queries
- 通信技术以及5G和AI保障电网安全与网络安全