第四期coding_group笔记_用CRF实现分词-词性标注
一、背景知识
1.1 什么是分词?
NLP的基础任务分为三个部分,词法分析、句法分析和语义分析,其中词法分析中有一种方法叫Tokenization,对汉字以字为单位进行处理叫做分词。
Example : 我 去 北 京
S S B E
注:S代表一个单独词,B代表一个词的开始,E表示一个词的结束(北京是一个词)。
1.2 什么是词性标注?
句法分析中有一种方法叫词性标注(pos tagging),词性标注的目标是使用类似PN、VB等的标签对句子(一连串的词或短语)进行打签。
Example : I can open this can .
Pos tagging -> PN MD VV PN NN PU
注:PN代词 MD情态动词 VV 动词 NN名词 PU标点符号
1.3 什么是分词-词性标注?
分词-词性标注就是将分词和词性标注两个任务同时进行,在一个模型里完成,可以减少错误传播。
Example : 我 去 北 京
S-PN S-VV B-NN E-NN
注:如果想理解更多关于nlp基础任务的知识,可参看我整理的张岳老师暑期班的第一天的笔记。
1.4 什么是CRF?
条件随机场(conditional random field)是一种用来标记和切分序列化数据的统计模型。在NLP领域可以用来做序列标注任务。
注:更多关于条件随机场的理论知识,可以参考以下内容:
条件随机场介绍(译)Introduction to Conditional Random Fields
二、CRF序列标注
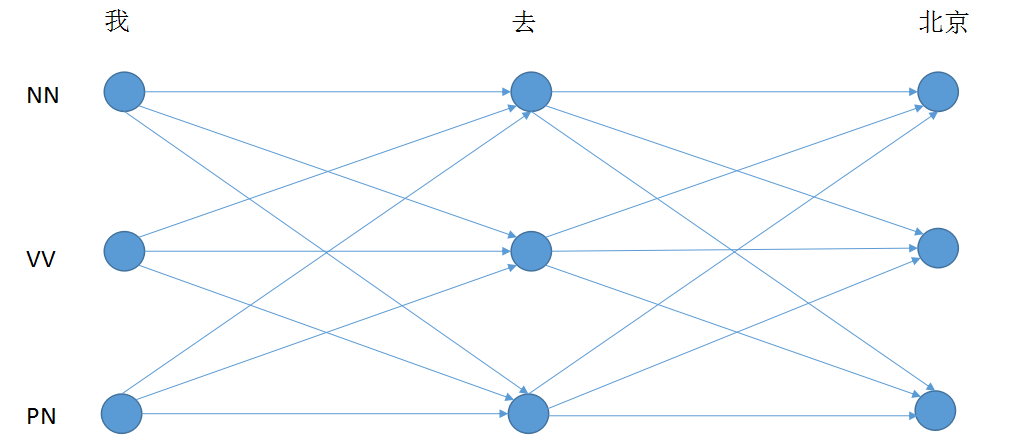
2.1 模型结构图
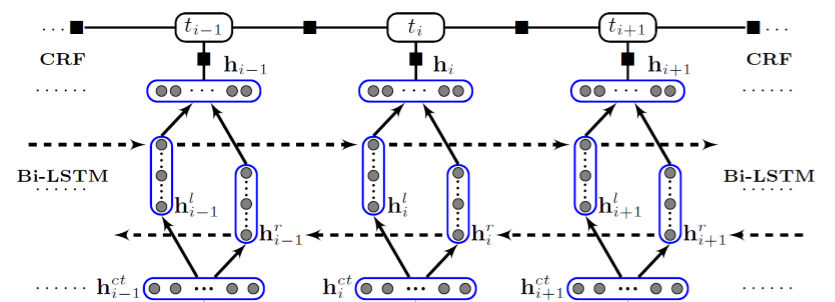
最底下的词向量层,上两层是Bi-LSTM层,最上面一层是CRF层。数据流程是从下层向上层计算。
2.2 CRF部分
2.2.1 理论
Point 1: 在CRF中,每个特征函数以下列信息作为输入,输出是一个实数值。
(1)一个句子s
(2)词在句子中的位置i
(3)当前词的标签
(4)前一个词的标签
注:通过限制特征只依赖于当前与之前词的标签,而不是句子中的任意标签,实际上是建立了一种特殊的线性CRF,而不是广义上的CRF。
Point 2: CRF的训练参数
(1)Input: x = {我,去,北京}
(2)Answer: ygold = {PN, VV, NN}
(3)y'是CRF标注的所有可能值,有3*3*3=27个;
(4)T矩阵存储转移分数,T[yiyi-1]是上个标签是的情况下,下个标签是yi的分数;
(5)hi是向量序列,通过神经网络Bi-LSTM得到,hi[yi]是被标成的发射分数;
(6)score(x,y)是模型对x被标注成y所打出的分数,是一个实数值;

Example : 我 去 北京
PN VV NN
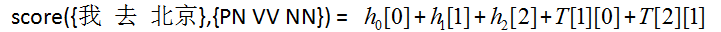
(7)P(ygold|x)是模型x对标注出ygold的概率;
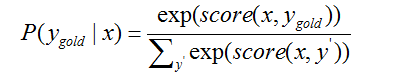
Point 3: CRF的训练目标:训练模型使得变大
Step 1: 对P(ygold|x)进行转化,取对数
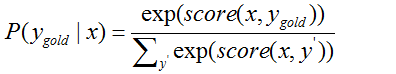
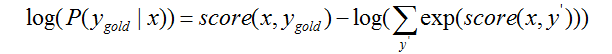
Step 2: 最终目标函数,使用梯度下降法
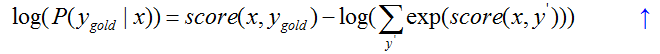

Step 3: 编程实现
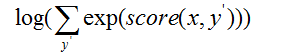
def _forward_alg(self, feats):
# do the forward algorithm to compute the partition function
init_alphas = torch.Tensor(1, self.labelSize).fill_(0)
# Wrap in a variable so that we will get automatic backprop
forward_var = autograd.Variable(init_alphas) # Iterate through the sentence
for idx in range(len(feats)):
feat = feats[idx]
alphas_t = [] # The forward variables at this timestep
for next_tag in range(self.labelSize):
# broadcast the emission score: it is the same regardless of the previous tag
if idx == 0:
alphas_t.append(feat[next_tag].view(1, -1))
else:
emit_score = feat[next_tag].view(1, -1).expand(1, self.labelSize)
# the ith entry of trans_score is the score of transitioning to next_tag from i
trans_score = self.T[next_tag]
# The ith entry of next_tag_var is the value for the edge (i -> next_tag) before we do log-sum-exp
next_tag_var = forward_var + trans_score + emit_score
# The forward variable for this tag is log-sum-exp of all the scores.
alphas_t.append(self.log_sum_exp(next_tag_var))
forward_var = torch.cat(alphas_t).view(1, -1)
alpha_score = self.log_sum_exp(forward_var)
return alpha_score
# Compute log sum exp in a numerically stable way for the forward algorithm
def log_sum_exp(self, vec):
max_score = vec[0, self.argmax(vec)]
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1])
return max_score + torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
def neg_log_likelihood(self, feats, tags):
forward_score = self._forward_alg(feats) # calculate denominator
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score # calculate loss
train()中的训练部分:
for iter in range(self.hyperParams.maxIter):
print('###Iteration' + str(iter) + "###")
random.shuffle(indexes)
for idx in range(len(trainExamples)):
# Step 1. Remember that Pytorch accumulates gradients. We need to clear them out before each instance
self.model.zero_grad()
# Step 2. Get our inputs ready for the network, that is, turn them into Variables of word indices.
self.model.LSTMHidden = self.model.init_hidden()
exam = trainExamples[indexes[idx]]
# Step 3. Run our forward pass. Compute the loss, gradients, and update the parameters by calling optimizer.step()
lstm_feats = self.model(exam.feat)
loss = self.model.crf.neg_log_likelihood(lstm_feats, exam.labelIndexs)
loss.backward()
optimizer.step()
if (idx + 1) % self.hyperParams.verboseIter == 0:
print('current: ', idx + 1, ", cost:", loss.data[0])
Point 4: 使用模型预测序列
使用维特比解码算法,解决篱笆图中的最短路径问题
step 1: 初始节点没有转移值
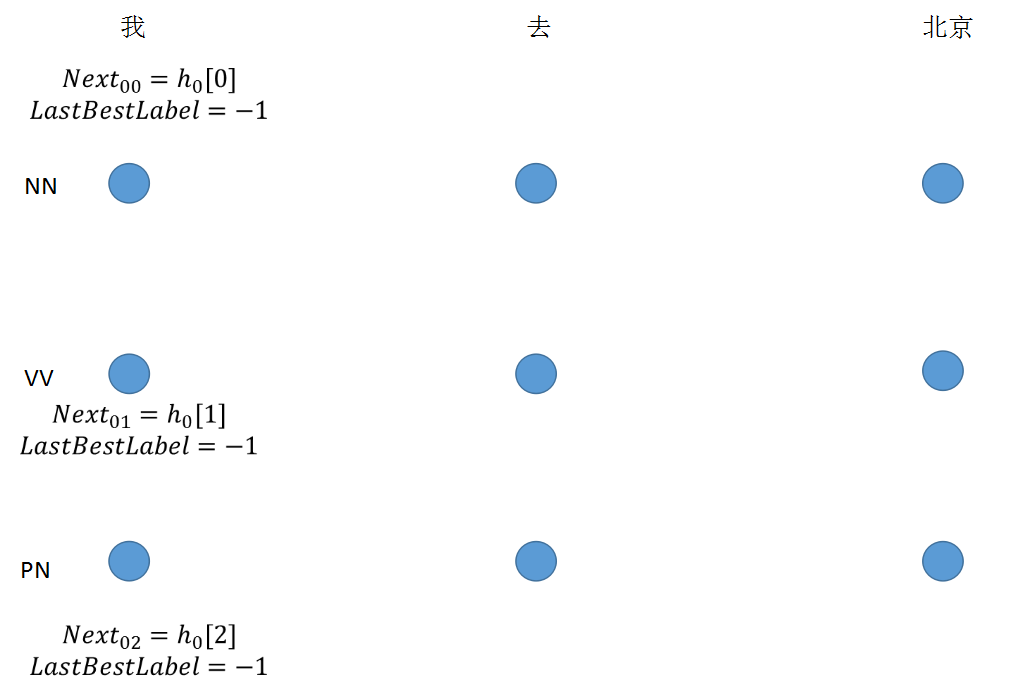
if idx == 0:
viterbi_var.append(feat[next_tag].view(1, -1))
step 2: 节点值由三部分组成,最后求取最大值,得到lastbestlabel的下标
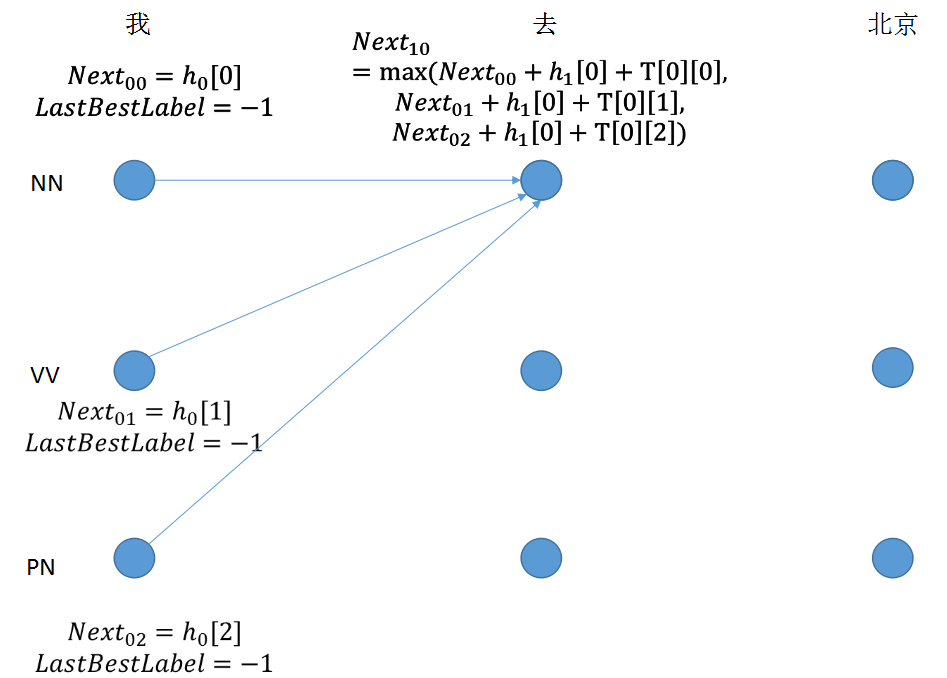
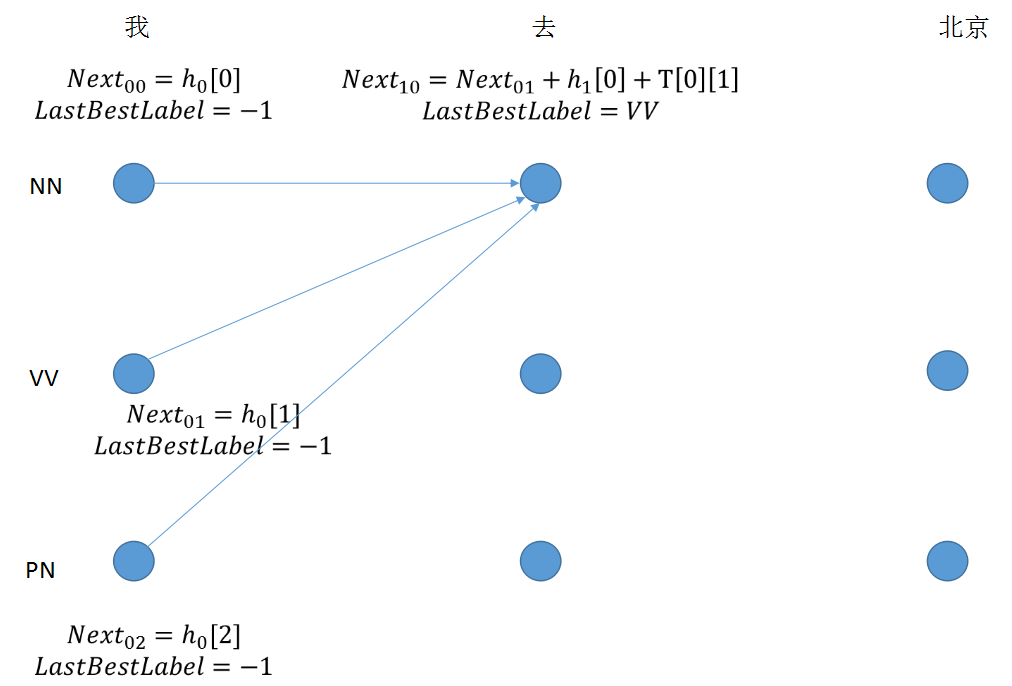
for next_tag in range(self.labelSize):
if idx == 0:
viterbi_var.append(feat[next_tag].view(1, -1))
else:
emit_score = feat[next_tag].view(1, -1).expand(1, self.labelSize)
trans_score = self.T[next_tag]
next_tag_var = forward_var + trans_score + emit_score
best_label_id = self.argmax(next_tag_var)
bptrs_t.append(best_label_id)
viterbi_var.append(next_tag_var[0][best_label_id])
step 3: 计算出所有节点,比较最后一个词的值,求取最大值之后,向前推出最佳序列。
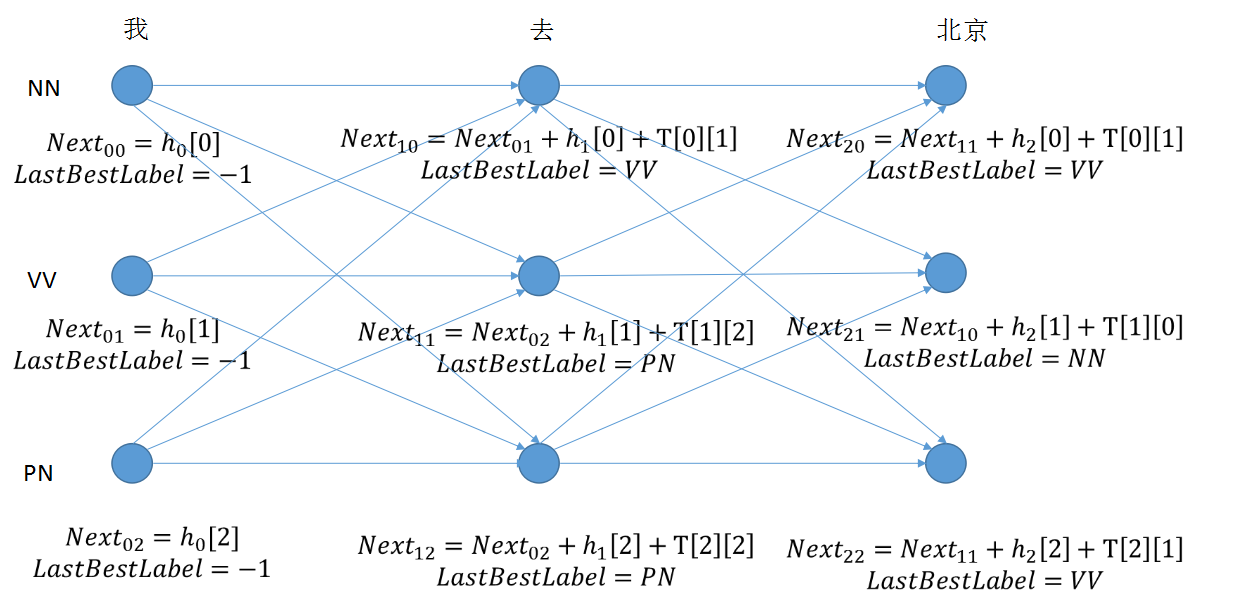

维特比解码算法实现预测序列
def _viterbi_decode(self, feats):
init_score = torch.Tensor(1, self.labelSize).fill_(0)
# forward_var at step i holds the viterbi variables for step i-1
forward_var = autograd.Variable(init_score)
back = []
for idx in range(len(feats)):
feat = feats[idx]
bptrs_t = [] # holds the backpointers for this step
viterbi_var = [] # holds the viterbi variables for this step
for next_tag in range(self.labelSize):
# next_tag_var[i] holds the viterbi variable for tag i at the previous step,
# plus the score of transitioning from tag i to next_tag.
# We don't include the emission scores here because the max does not
# depend on them (we add them in below)
if idx == 0:
viterbi_var.append(feat[next_tag].view(1, -1))
else:
emit_score = feat[next_tag].view(1, -1).expand(1, self.labelSize)
trans_score = self.T[next_tag]
next_tag_var = forward_var + trans_score + emit_score
best_label_id = self.argmax(next_tag_var)
bptrs_t.append(best_label_id)
viterbi_var.append(next_tag_var[0][best_label_id])
# Now add in the emission scores, and assign forward_var to the set of viterbi variables we just computed
forward_var = (torch.cat(viterbi_var)).view(1, -1)
if idx > 0:
back.append(bptrs_t)
best_label_id = self.argmax(forward_var)
# Follow the back pointers to decode the best path.
best_path = [best_label_id]
path_score = forward_var[0][best_label_id]
for bptrs_t in reversed(back):
best_label_id = bptrs_t[best_label_id]
best_path.append(best_label_id)
best_path.reverse()
return path_score, best_path
train()函数中的预测部分
# Check predictions after training
eval_dev = Eval()
for idx in range(len(devExamples)):
predictLabels = self.predict(devExamples[idx])
devInsts[idx].evalPRF(predictLabels, eval_dev)
print('Dev: ', end="")
eval_dev.getFscore() eval_test = Eval()
for idx in range(len(testExamples)):
predictLabels = self.predict(testExamples[idx])
testInsts[idx].evalPRF(predictLabels, eval_test)
print('Test: ', end="")
eval_test.getFscore()
def predict(self, exam):
tag_hiddens = self.model(exam.feat)
_, best_path = self.model.crf._viterbi_decode(tag_hiddens)
predictLabels = []
for idx in range(len(best_path)):
predictLabels.append(self.hyperParams.labelAlpha.from_id(best_path[idx]))
return predictLabels
Point 5 : 使用F1分数测量精度,最佳值为1,最差为0
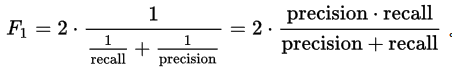
def getFscore(self):
if self.predict_num == 0:
self.precision = 0
else:
self.precision = self.correct_num / self.predict_num if self.gold_num == 0:
self.recall = 0
else:
self.recall = self.correct_num / self.gold_num if self.precision + self.recall == 0:
self.fscore = 0
else:
self.fscore = 2 * (self.precision * self.recall) / (self.precision + self.recall)
print("precision: ", self.precision, ", recall: ", self.recall, ", fscore: ", self.fscore)
注:全部代码和注释链接
扩展:可将数据中第二列和第一列一起放入Bi-LSTM中提取特征,这次只用到数据的第一列和第三列。
最新文章
- js: 从setTimeout说事件循环模型
- SpringMVC学习(一)
- .NET牛人需要了解的问题[转]
- EF架构~基于EF数据层的实现
- java的ArrayList使用方法
- 多线程操作Coredata(转)
- UBUNTU下如何开启SSHD服务
- 安装Chive提示CDbConnection failed to open the DB connection.
- CMAKE 学习
- flac文件提取专辑封面手记
- css2和CSS3的background属性简写
- 图像插值:OpenCV_remap
- JavaScript之事件及动画
- 一个小公式帮你轻松将IP地址从10进制转到2进制
- WPF常见主界面的布局
- SpringBoot打成jar包后,获取不到读取resources目录下文件路径的问题
- 012-mac下shell,zsh,oh-my-zsh,以及插件
- tomcat的jks的私钥导出nginx需要的key文件
- LeetCode:146_LRU cache | LRU缓存设计 | Hard
- C# Skip和Take的简单用法