spark学习之IDEA配置spark并wordcount提交集群
这篇文章包括以下内容
(1)IDEA中scala的安装
(2)hdfs简单的使用,没有写它的部署
(3) 使用scala编写简单的wordcount,输入文件和输出文件使用参数传递
(4)IDEA打包和提交方法
一 IDEA中scala的安装
(1) 下载IEDA 装jdk
(2) 启动应用程序 选择插件(pluigin)查看scala版本,然后去对应的网站下载https://plugins.jetbrains.com/plugin/1347-scala
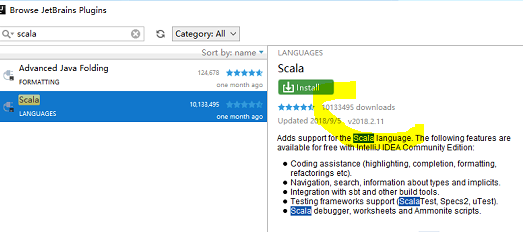
(4) 将刚才下载的scala zip文件移动到IDEA的plugin下面
(5) 回到启动页面 选择plugin

选择从磁盘安装,然后重启
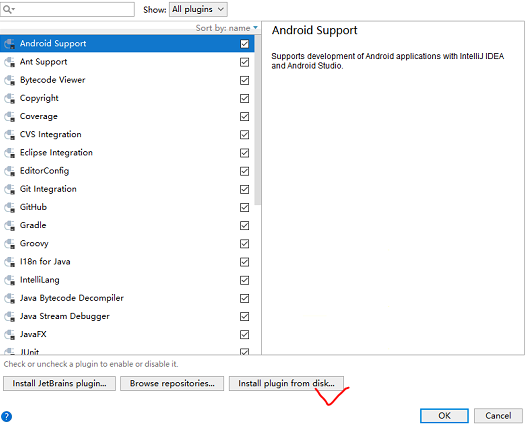
(6)新建项目 scala项目 如果没有scala sdk 那么windows下一个导入进去(注意版本一致)
二 提交wordcount并提交jar
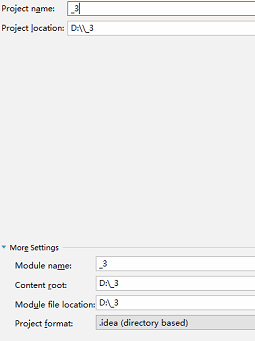
(1) 新建Maven项目
file->project->maven->next-->设置工程名称和路径(路径不要为中文)--->完成
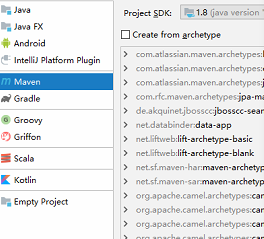
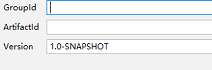
(2)将pol导入依赖,粘贴下面代码以后,需要点击右侧的maven project并刷新
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.xuebusi</groupId>
<artifactId>spark</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-</encoding> <!-- 这里对jar包版本做集中管理 -->
<scala.version>2.10.</scala.version>
<spark.version>1.6.</spark.version>
<hadoop.version>2.6.</hadoop.version>
</properties> <dependencies>
<dependency>
<!-- scala语言核心包 -->
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<!-- spark核心包 -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.</artifactId>
<version>${spark.version}</version>
</dependency> <dependency>
<!-- hadoop的客户端,用于访问HDFS -->
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<!-- 由于我们的程序可能有很多,所以这里可以不用指定main方法所在的类名,我们可以在提交spark程序的时候手动指定要调用那个main方法 -->
<!--
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.xuebusi.spark.WordCount</mainClass>
</transformer>
</transformers>
--> </configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
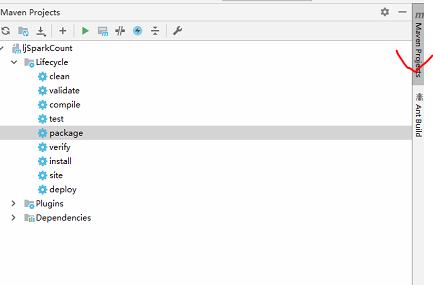
这个时候在左侧的依赖就会出现很多maven包,注意要有网络哈
(2)修改pol部分内容如下,错误的内容会出现红色的字样哦
在pom.xml文件中还有错误提示,因为src/main/和src/test/这两个目录下面没有scala目录。
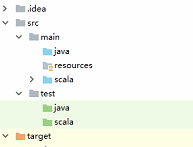
(3) 右击项目src,新建scala class,选择object
(4) 编写代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} /**
* Created by SYJ on 2017/1/23.
*/
object WordCount {
def main(args: Array[String]) {
//创建SparkConf
val conf: SparkConf = new SparkConf()
//创建SparkContext
val sc: SparkContext = new SparkContext(conf)
//从文件读取数据
val lines: RDD[String] = sc.textFile(args())
//按空格切分单词
val words: RDD[String] = lines.flatMap(_.split(" "))
//单词计数,每个单词每出现一次就计数为1
val wordAndOne: RDD[(String, Int)] = words.map((_, ))
//聚合,统计每个单词总共出现的次数
val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//排序,根据单词出现的次数排序
val fianlResult: RDD[(String, Int)] = result.sortBy(_._2, false)
//将统计结果保存到文件
fianlResult.saveAsTextFile(args())
//释放资源
sc.stop()
}
}
(5) 打包
将编写好的WordCount程序使用Maven插件打成jar包,打包的时候也要保证电脑能够联网,因为Maven可能会到中央仓库中下载一些依赖:
双击package

打包成功提示
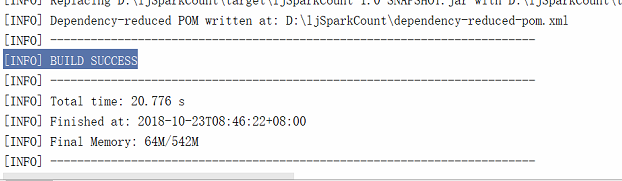
(6) 在jar包上面右击 copy path找到jar在win下的路径并上传到集群
(7) 启动hdfs 因为只用到hdfs,创建一个目录 hdfs dfs -mkdir /wc 然后创建一个txt文件
/hadoop/sbin/start-dfs.sh
(8)启动集群
/spark/sbin/start-all.sh
(9) jps查看master和worker是否都起来
(10) 提交给集群 后面两个参数分别为输入输出文件
bin/spark-submit --class spark.wordCount --executor-memory 512m --total-executor-cores 2 /home/hadoop/hadoop/spark-2.3.1-bin-hadoop2.7/spark_testJar/ljSparkCount-1.0-SNAPSHOT.jar hdfs://slave104:9000/wc hdfs://slave104:9000/wc/output
(11)验证

好了,到此结束,加油骚年
最新文章
- Node快速安装
- 几种常见的排序方法(C语言实现)
- Android Activity形象描述
- [扫描线]POJ2932 Coneology
- Context 之我见
- C# devExpress BandedGridView属性 备忘
- webService请求方式快速生成代码 (Postman)
- MySQL实例搭建
- 2014新年福利,居然有人将Ext JS 4.1的文档翻译了
- java动态代理源码解析
- python的设计原则及设计模式
- springboot整合JPA(简单整理,待续---)
- iis8.0 https配置教程
- python作业高级FTP
- Linux下安装PCRE
- python全栈开发day24-__new__、__del__、item系列、异常处理
- textrank的方法,大概懂了
- PHP计算两个绝对路径的相对路径
- 【Laravel5.5】 Laravel 在views中加载公共页面怎么实现
- 『TensotFlow』RNN/LSTM古诗生成
热门文章
- 【Sprint3冲刺之前】TDzhushou软件项目测试计划书
- vim 模式切换
- Android.mk: recipe commences before first target. Stop.
- webstorm 设置IP 访问 手机测试效果
- gulp css html image js 合并压缩
- Matlab中图片保存的四种方法
- IOS之禁用UIWebView的默认交互行为
- 2016/07/07 mymps(蚂蚁分类信息/地方门户系统)
- EasyHLS直播在Linux非root用户运行时出现无法写文件的问题解决mkdir 0777
- EasyPusher实现Android手机屏幕桌面直播,实时推送操作画面,用于手游直播等应用