100天搞定机器学习|Day22 机器为什么能学习?
前情回顾
机器学习100天|Day1数据预处理
100天搞定机器学习|Day2简单线性回归分析
100天搞定机器学习|Day3多元线性回归
100天搞定机器学习|Day4-6 逻辑回归
100天搞定机器学习|Day7 K-NN
100天搞定机器学习|Day8 逻辑回归的数学原理
100天搞定机器学习|Day9-12 支持向量机
100天搞定机器学习|Day11 实现KNN
100天搞定机器学习|Day13-14 SVM的实现
100天搞定机器学习|Day15 朴素贝叶斯
100天搞定机器学习|Day16 通过内核技巧实现SVM
100天搞定机器学习|Day17-18 神奇的逻辑回归
100天搞定机器学习|Day19-20 加州理工学院公开课:机器学习与数据挖掘
Day17,Avik-Jain第22天完成Yaser Abu-Mostafa教授的Caltech机器学习课程-CS156中的课程2。
1 Hoeffding不等式
假设有一个罐子装满了橙色和绿色的球,为了估计罐子中橙色和绿色的比例,我们随机抓一把球,称为样本:
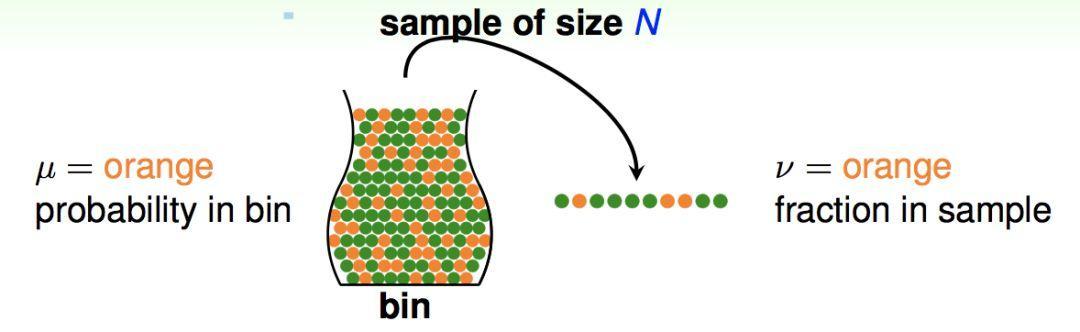
其中,设罐子中橙色球的比例为μ,样本中橙色球比例为v,样本的大小为N,我们对真实分布μ和样本分布v的差异容忍度为ε,则有下面的不等式成立:

也就是存在一个概率上界,只要我们保证样本容量N很大,就能使得“μ和v的差异大”这件事的概率是很小的。
2 对于一个假设函数h的情况
如果我们的假设函数h已经确定了,那么我们可以这样把我们的问题对应到罐子模型:每个球表示一个输入x,橙色表示h与真实的函数f预测的值不相同,绿色表示相同,即:
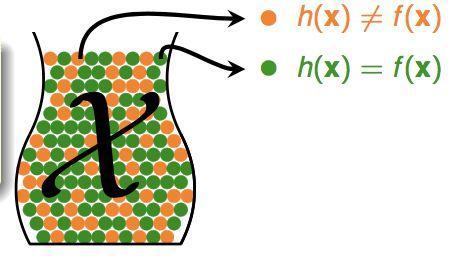
那么罐子中的所有球就是所有可能的输入x,而抓的一把球表示我们的训练集(注意!这里其实是做了一个假设:我们的训练集和测试集都由同一个未知的概率分布P来产生,也就是来源于同一个罐子),那么橙色球占的比例μ就表示我们的假设函数h在真正的输入空间中的预测错误率Eout(我们最后想要降低的),v就表示我们在训练集中的预测错误率Ein(我们的算法能最小化的),由Hoeffding不等式,就能得到:

也就是说,只要我们能保证训练集的量N足够大,就能保证训练集的错误率与真实的预测错误率是有很大概率接近的。
3 对于有限多个h的情况
上面一节我们证明了,对于一个给定的假设函数h,只要训练集足够大,我们能保证它在训练集上的预测效果与真正的预测效果很大概率是接近的。但是,我们只能保证它们的预测效果接近,也可能预测效果都是坏呢?
我们的机器学习算法是在假设空间里面选一个h,使得这个h在训练集上错误率很小,那么这个h是不是在整个输入空间上错误率也很小呢?这一节我们要证明的就是,对于假设空间只有有限个h时,只要训练集N足够大,这也是很大概率成立的。
首先我们来看这张表:
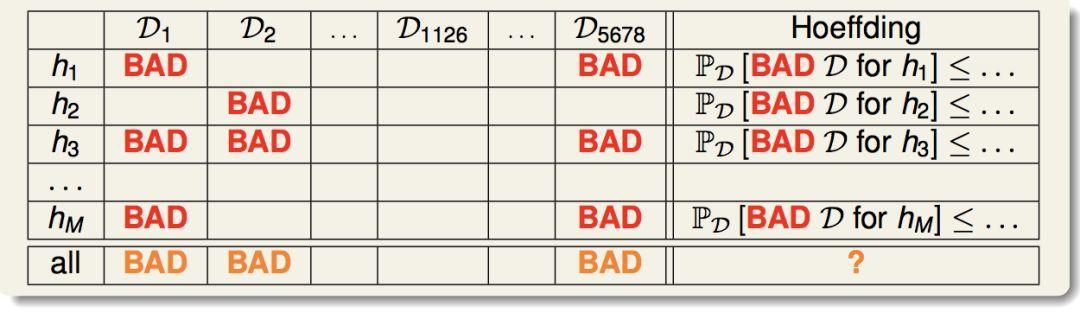
首先,对于一个给定的h,我们可以定义一个概念:“坏的训练集”(对应于表中红色的bad)。所谓坏的训练集,就是h在这个训练集上面的Ein和真实的Eout的差异超过了我们定义的容忍度ε。Hoeffding不等式保证了,对于一个给定的h(表中的一行),选到坏的训练集的概率是很低的。
然后,对于假设空间里面有M个候选的h,我们重新定义“坏的训练集”的概念(对应于表中橙色的bad),只要它对于任何一个h是坏的,那么它就是一个坏的。那么我们选到橙色坏的训练集的概率可以如下推导:
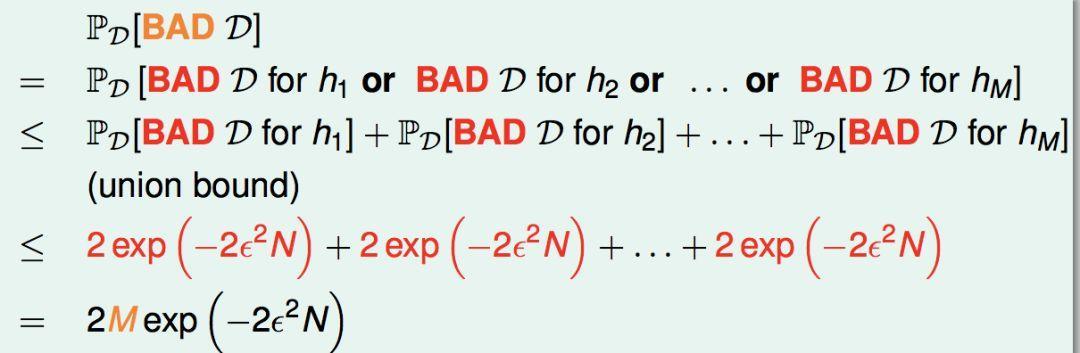
由于M是有限的,只要训练集N足够大,我们选到坏训练集的概率仍然是很小的。也就是说,我们的训练集很大可能是一个好的训练集,所有的h在上面都是好的,算法只要选取一个在训练集上表现好的h,那么它的预测能力也是PAC好的。也就是有不等式:
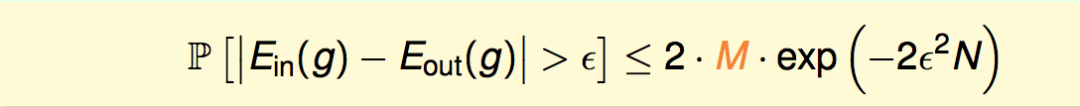
因此机器学习过程如下图:
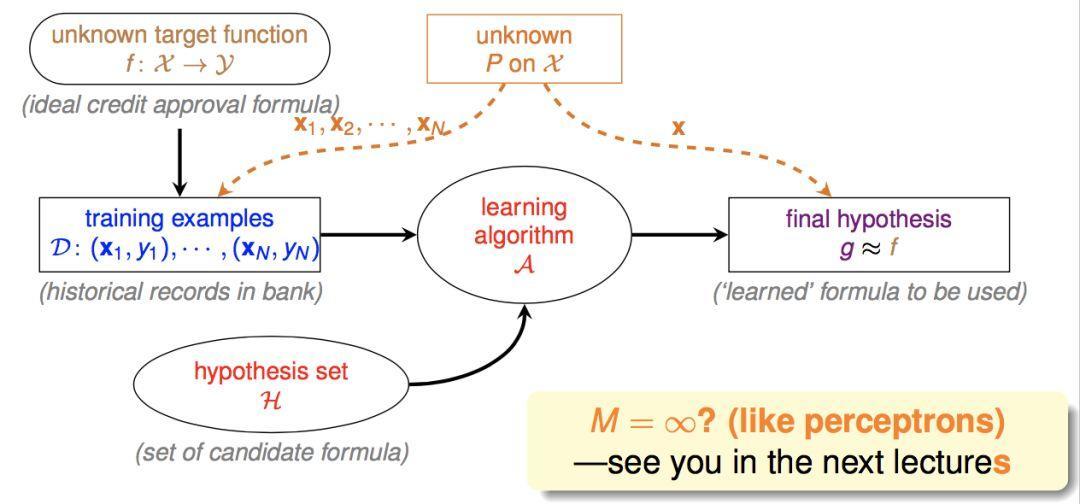
(这里多出来的橙色部分表示,训练集和测试集是由同一个概率分布产生的)
因此当有限个h的情况下,机器学习算法确实是能学到东西的。
之后我们会讨论,当假设空间存在无限个h时,机器学习是否还有效。
上一节我们证明了,当假设空间的大小是M时,可以得到概率上界:

即,只要训练数据量N足够大,那么训练集上的Ein与真实的预测错误率Eout是PAC(大概率)接近的。
但是,我们上面的理论只有在假设空间大小有限时才成立,如果假设空间无限大,右边的概率上界就会变成无限大。
事实上,右边的边界是一个比较弱的边界,这一节我们要找出一个更强的边界,来证明我们的机器学习算法对于假设空间无限大的情形仍然是可行的。我们将会用一个m来代替大M,并且证明当假设空间具有break point时,m具有N的多项式级别的上界。
2 成长函数
对于一组给定的训练集x1,x2,...,xN。定义函数H(x1,x2,......,xN),表示使用假设空间H里面的假设函数h,最多能把训练集划分成多少种圈圈叉叉组合(即产生多少种Dichotomy,最大是2^N)。
例如,假设空间是平面上的所有线,训练数据集是平面上的N个点,则有:
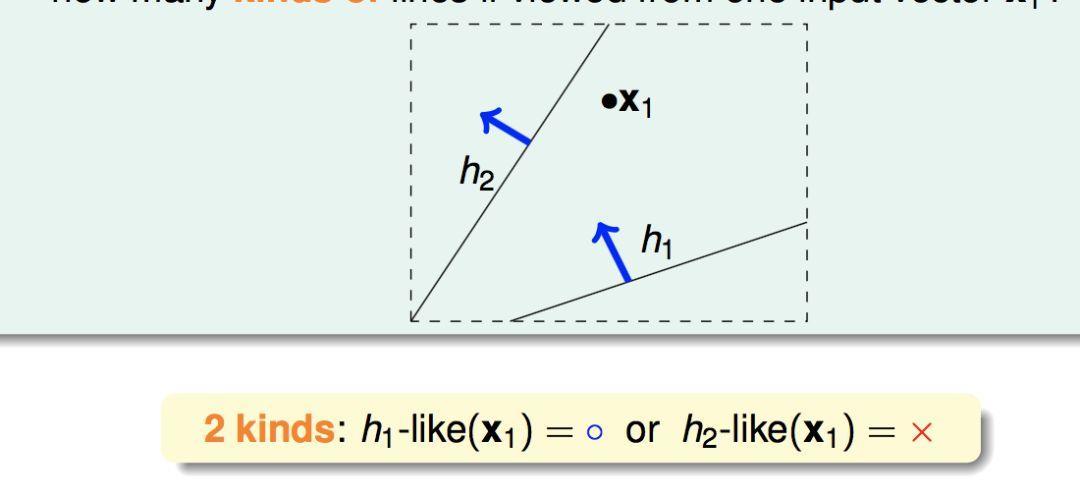
N = 1 时,有2种划分方式:
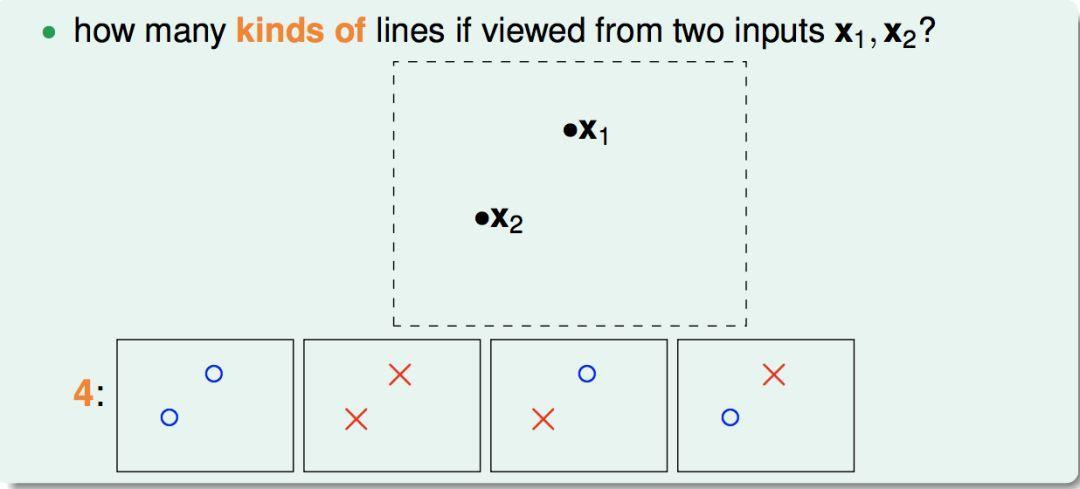
N = 2时,有4种划分方式:
N = 3 时, 有8种划分方式:

N = 4时,有14种划分方式(因为有两种是不可能用一条直线划分出来的):
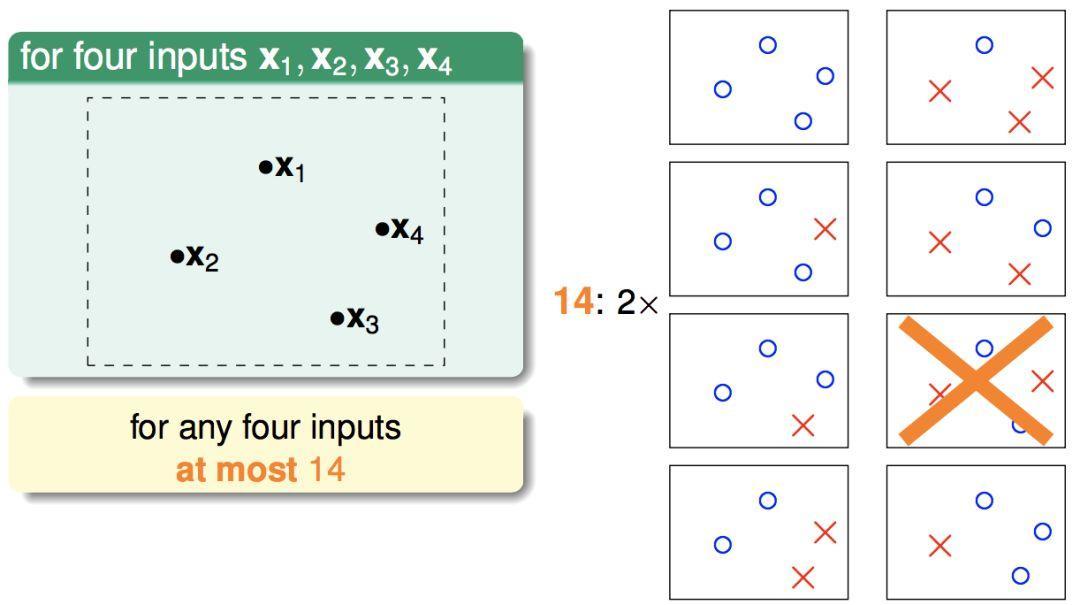
…………
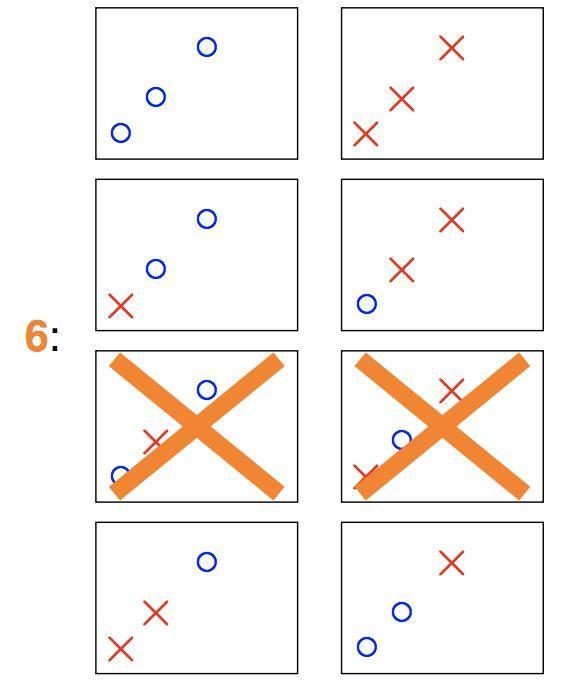
另外,划分数与训练集有关,(例如N=3时,如果三个点共线,那么有两种划分就不可能产生,因此只有6种划分而不是8种):
为了排除对于训练数据的依赖性,我们定义成长函数:
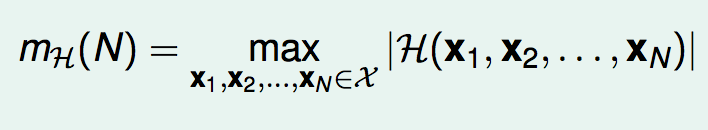
因此,成长函数的意义就是:使用假设空间H, 最多有多少种对训练集(大小为N)的划分方式。成长函数只与两个因素有关:训练集的大小N,假设空间的类型H。
下面列举了几种假设空间的成长函数:

3 break point
这里我们定义break point。所谓break point,就是指当训练集的大小为k时,成长函数满足:

即假设空间所不能shatter的训练集容量。
容易想到,如果k是break point,那么k + 1, k + 2....也是break point。
4 成长函数的上界
由于第一个break point会对后面的成长函数有所限制,于是我们定义上界函数B(N,k),表示在第一个break point是k的限制下,成长函数mH(N)的最大可能值:

现在我们开始推导这个上界函数的上界:
首先,B(N,k)产生的Dichotomy可以分为两种类型,一种是前N-1个点成对的出现,一种是前N-1个点只出现一次:
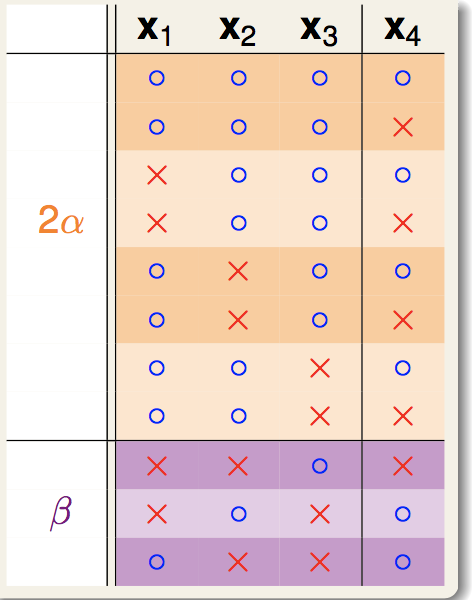
因此显然有:
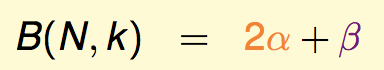
然后,对于前N-1个点在这里产生的所有情况:
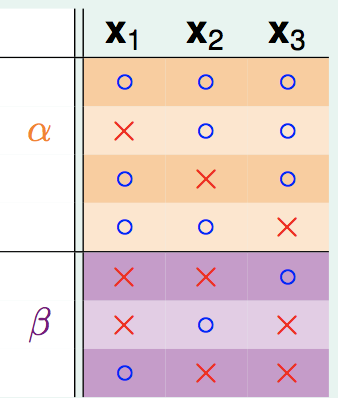
显然这里的个数就是α+β,显然,这前N-1个点产生的Dichotomy数仍然要受限于break point是k这个前提,因此:
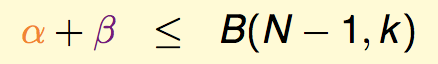
然后,对于成对出现的Dichotomy的前N-1个点:

我们可以说,这里的前N-1个点将会受限于break point是k-1。反证法:如果这里有k-1个点是能够shatter的,那么配合上我们的第N个点,就能找出k个点能shatter,这与B(N,k)的定义就矛盾了。因此我们有:
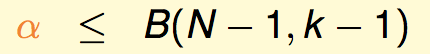
综合上面,我们有:

利用这个递推关系以及边界情形,我们可以用数学归纳法简单证明得到(事实上可以证明下面是等号关系):
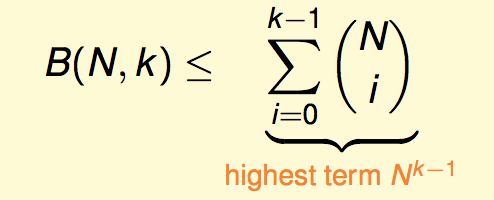
因此成长函数具有多项式级别的上界。
5 VC-Bound
这里我们不涉及严格的数学证明,而是用一种通俗化的方法来引出VC-Bound。也就是如何用m来替换M。


于是我们就得到了机器学习问题的PAC概率上界,称为VC-Bound:

因此我们得到了更强的边界,当右边的成长函数具有break point时,它的上界是N^k-1级别的,只要我们的N足够大,“存在一个假设函数h使得坏情况发生”这件事的几率就会很小。
6 结论
结论:当假设空间的成长函数具有break point时,只要N足够大,我们能PAC地保证训练集是一个好的训练集,所有h在上面的Ein和Eout都是近似的,算法可以对这些h做自由选择。也就是机器学习算法确实是能work的。
通俗的说,机器学习能work的条件:
1 好的假设空间。使得成长函数具有break point。
2 好的训练数据集。使得N足够大。
3 好的算法。使得我们能选择在训练集上表现好的h。
4 好的运气。因为还是有一定小概率会发生坏情况。
END

本文转自:
https://www.cnblogs.com/coldyan/
最新文章
- (三)Spark-Hadoop集群搭建-Java&Python版Spark
- 【原创】kafka client源代码分析
- 编译GCC4.8.2
- Hadoop2.2.0环境下Sqoop1.99.3安装
- Windows Phone 8.1 Update1 支持中文“小娜”及开发者模拟器更新
- 111. Minimum Depth of Binary Tree
- URAL 1009 K-based numbers(DP递推)
- Android定义自己的面板共享系统
- 【代码优化】当许多构造函数的参数,请考虑使用builder模式
- qml : qml控件自适应;
- python正则表达式补充
- java 按概率产生
- HDU 1851 (N个BASH博弈子游戏)
- 17 多校1 Add More Zero 水题
- centos docker 安装笔记
- PostgreSQL基础命令
- HMM模型和Viterbi算法
- Centos7扩展磁盘空间(LVM管理)
- Mysql 主键常用修改
- RTT下spi flash+elm fat文件系统移植小记
热门文章
- c++学习书籍推荐《C++编程思想第一卷》下载
- CSS Grid网格布局全攻略
- Java编程思想:文件加锁
- P4071 [SDOI2016]排列计数 题解
- 个人永久性免费-Excel催化剂功能第47波-VBA开发者喜爱的加密函数类
- html+css test1
- AbstractCollection
- 一份关于.NET Core云原生采用情况调查
- Python版:Selenium2.0之WebDriver学习总结_实例1
- [__NSCFString countByEnumeratingWithState:objects:count:]: unrecognized selector sent to instance 0x17deba00